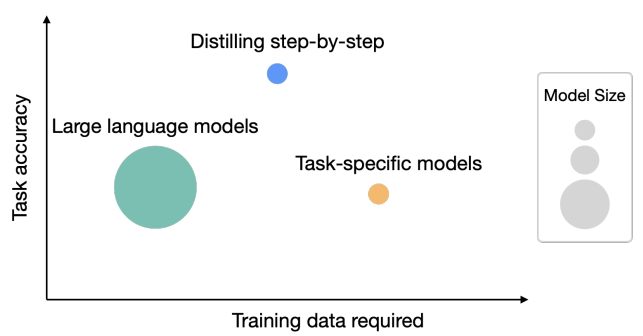
如何用7.7亿参数的蒸馏模型超过5400亿的大语言模型——Google提出新的模型蒸馏方法:逐步蒸馏(Distilling step-by-step)详解
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)