
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



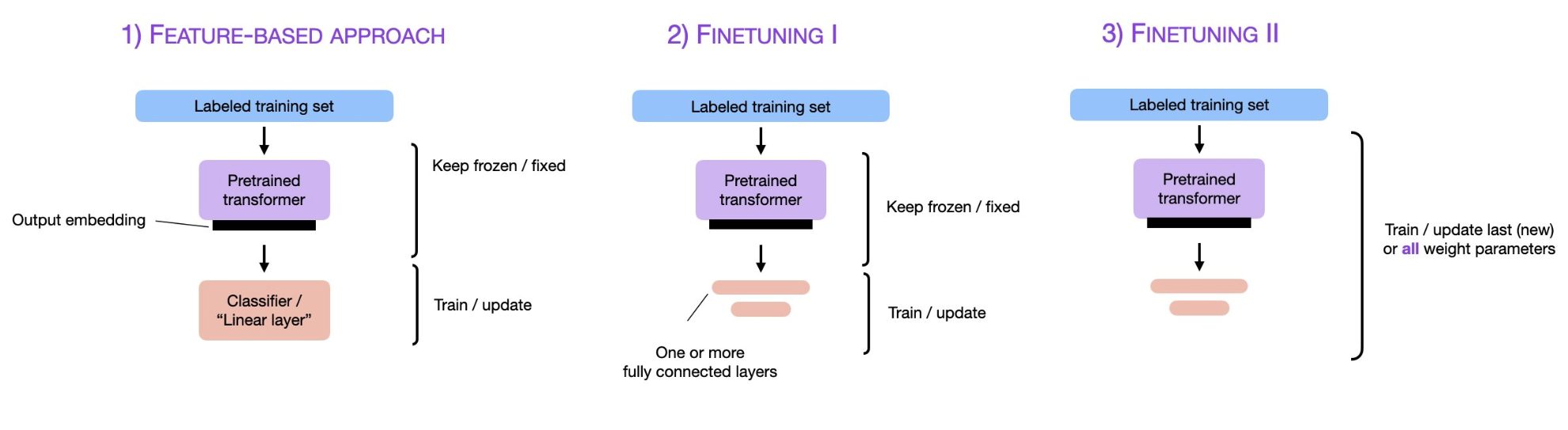
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
今日推荐
人工神经网络(Artificial Neural Network)算法简介
编程语言(Programming Language)、汇编语言(Assembly Language, ASM)、机器语言(Machine Language/Code)的区别和简介
Arena Hard:LM-SYS推出的更难更有区分度的大模型评测基准
谷歌发布新一代大模型Gemini 2.5 Flash,成本、速度和性能的最优均衡,同时支持推理和非推理模式,评测结果超Sonnet 3.7
ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
大语言模型的开发者运维LLMOps来临,比MLOps概念还要新:吴恩达联合Google云研发人员推出免费的LLMOps课程