PyTorch 2.0发布——一个更快、更加Pythonic和灵活的PyTorch版本,让Tranformer运行更快!
在去年12月2日的PyTorch大会上(参考链接:[重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!](https://www.datalearner.com/blog/1051670030665432
汇总「python」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
在去年12月2日的PyTorch大会上(参考链接:[重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!](https://www.datalearner.com/blog/1051670030665432

Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。

《Python for Data Analysis: Data Wrangling with pandas, NumPy, and Jupyter》是由Wes McKinney撰写的Python数据分析专业工具书籍。很容易理解,这本书就是教大家如何使用Pandas、NumPy以及Jupyter分析数据的。
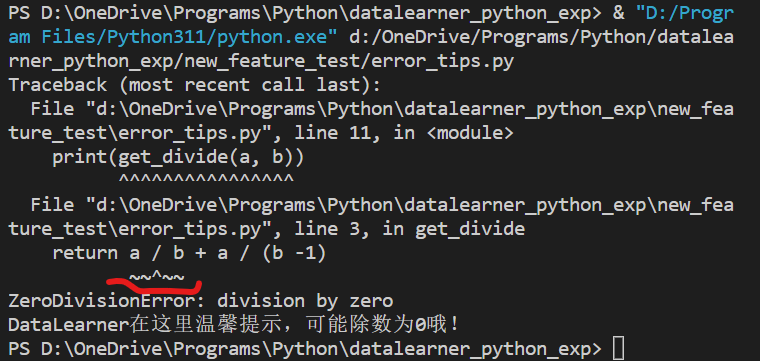
上个月Python的3.11版本发布了第一个beta版本,3.11带来了很多非常棒的新特性,例如错误提示更加具体,可以定位到具体代码位置等,十分友好,建议大家关注。这里简单为大家介绍一下。

昨天,卡地夫大学的NLP研究小组CardiffNLP发布了一个全新的NLP处理Python库——TweetNLP,这是一个完全基于推文训练的NLP的Python库。它提供了一组非常实用的NLP工具,可以做推文的情感分析、emoji预测、命名实体识别等。

在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。
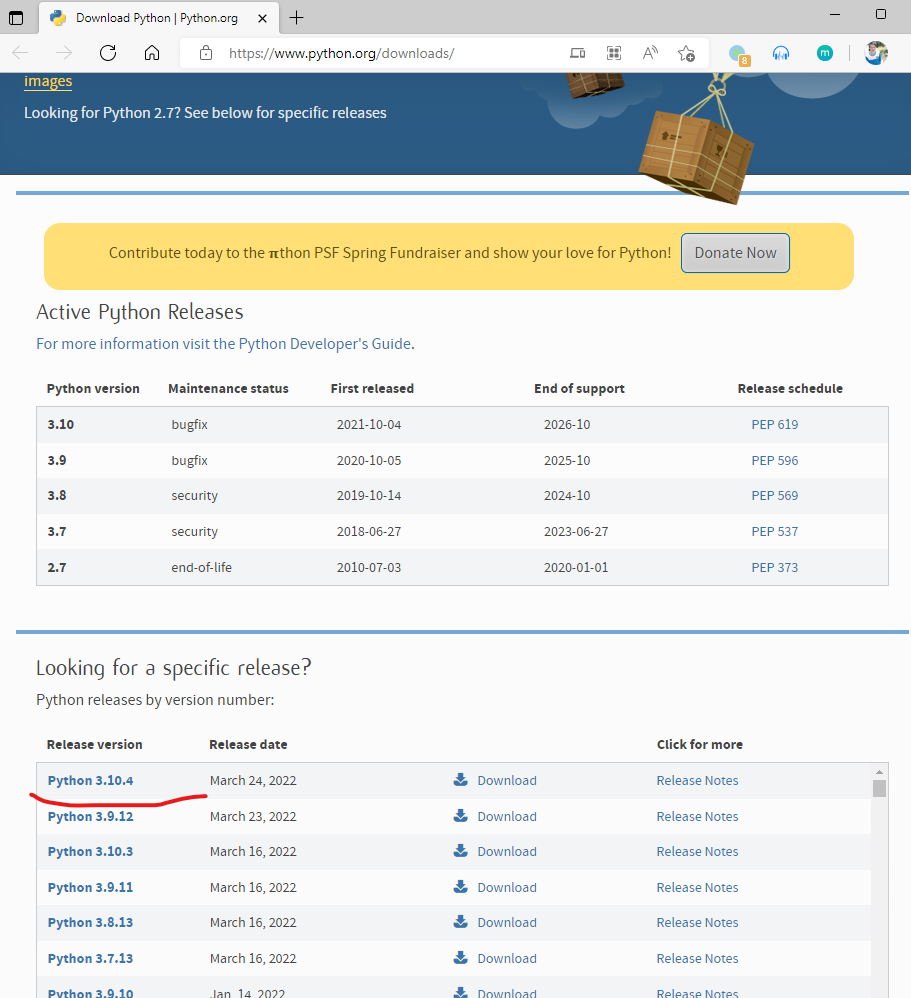
Python作为目前最流行的编程语言,因为其易用性以及丰富的库成为很多人的工具。它不仅是程序员的编程语言,也是各行各业提升工作效率的工具。本篇博客作为一篇针对完全小白的python语言搭建环境,不会为python语言本身做介绍,完全只考虑搭建python编程环境,目的是让你动手在电脑上写下第一行python程序,并成功运行,为广大童鞋提供一个入门参考。

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。

《Python Notes For Professionals》是StackOverflow上的人总结的Python使用方法。

去年5月份的时候,Python创始人Guido van Rossum在参加Language Summit时候说他希望Python3.11能在性能上获得巨大的提升,可以实现性能翻倍。目前看,似乎已经有了很大的希望!

Pandas和NumPy是Python数据科学领域中最基础的两个库,他们都可以读取大量的数据并对数据做计算等处理。有很多的操作他们都能做。那么,这两个Python库在数据处理的性能上有什么差别呢?今天在Reddit上看到一个有意思的讨论和大家分享一下。

pandas是Python中一个非常重要的分析工具,在数据处理方面应用非常广泛。但是,也是因为pandas包含的操作很多,所以初学者很多时候也不能特别能理解这些操作。 为了让初学者能够充分理解pandas中的操作,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。
pandas.get_dummies是pandas中一种非常高效的方法。它最主要的作用是可以将分类变量转变成dummy变量,也就是虚拟变量。这篇博客将简要的介绍一下pandas.get_dummies()方法,并描述其在机器学习中的应用的一些注意事项。

对于刚接触使用Python的同学来说,Python强大的生态与优秀的开源工具应该印象十分深刻。同时对于一些已经在使用Python解决问题的童鞋来说,使用pip来安装一些别人提供的工具应该已经熟悉了。当然,也有一些同学应该也听说可以使用conda来安装一些第三方的开源包。那么,python的包管理工具pip是一个什么样的东西?conda作为一个替代者或者补充,与pip有什么区别,二者分布适合什么情况下使用呢?本文将根据我的个人经验与观点为大家做一个简单的说明。
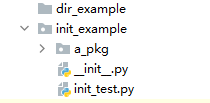
在Python工程中,我们经常可以看到带有“\_\_init\_\_.py”文件的目录,在PyCharm中,带有这个文件的目录被认为是Python的包目录,与目录的图标有不一样的显示。那么这个文件的作用是什么,我们平时如何使用呢,这篇文章将解释这个问题。
Python最新正式版本3.10在10月4日已经发布。这个版本从2020年5月开始开发,经历差不多一年半的时间终于正式发布。当然每一个新版本都有很多新功能。我们将持续关注新功能,在这篇文章中,我们将简述3.10中新功能中的语法——结构模式匹配(structural pattern matching)。

为初学者、中级和有经验的开发者提供70多个python项目, 10000, 小木, PythonHub今天在推上给大家分享了一个非常棒的项目,就是这个为为初学者、中级和有经验的开发者提供70多个python项目。 亲自动手实践一些项目可以增加我们的实际的编程技巧。每一次都做一点将会得到很多。很多人都在GitHub、Reddit或者是Quera上搜索过哪些项目可以让Python初学者、中级者增加经验的Python项目。这次它来了。
使用配置文件控制程序的运行是一种非常常见的编程技巧,因此配置文件的解析是所有编程语言中都不可缺少的模块。在Python中,通常使用configparser模块进行配置文件解析。但是configparser解析配置文件有几个常见问题:读取当前项目下某个位置的配置文件、重复配置项的处理以及大小写配置项的读取。本文将描述如何解决这三个问题。
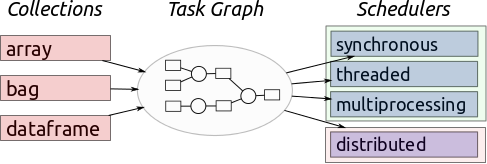
运行本地dask集群的时候出错Task exception was never retrieved的解决方法

有的时候使用Python遇到内存溢出的问题,但其实机器剩余内存很多。需要注意Python版本是否正确

NumPy是Python中非常优秀的一个数据科学工具包,使用Python做数据分析的童鞋几乎是必备的工具。NumPy的提供了非常丰富的计算能力,但是底层是C语言实现的,因此既有Python语法的低门槛,速度上却依然非常好。NumPy本身也和Pandas、SciPy一起成为一种生态了。今天,NumPy发布了1.20.0最新版本,这个版本的改动很大。值得童鞋们关注~
在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。