
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



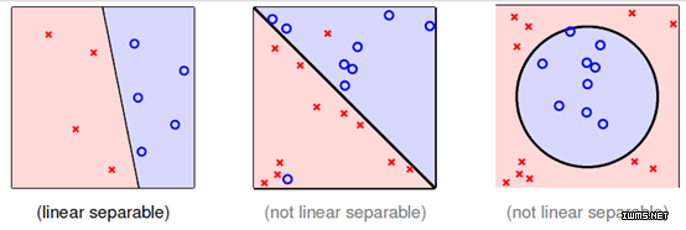
在机器学习或者深度学习中,正则项是我们经常遇到的概念。它对提高模型的准确性和泛化能力非常重要。本文详细描述了正则项的来源以及与其他概念的相关关系。

在回归模型中加入交互项是一种非常常见的处理方式。它可以极大的拓展回归模型对变量之间的依赖的解释。本篇博客将简要介绍这个交互项。