
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



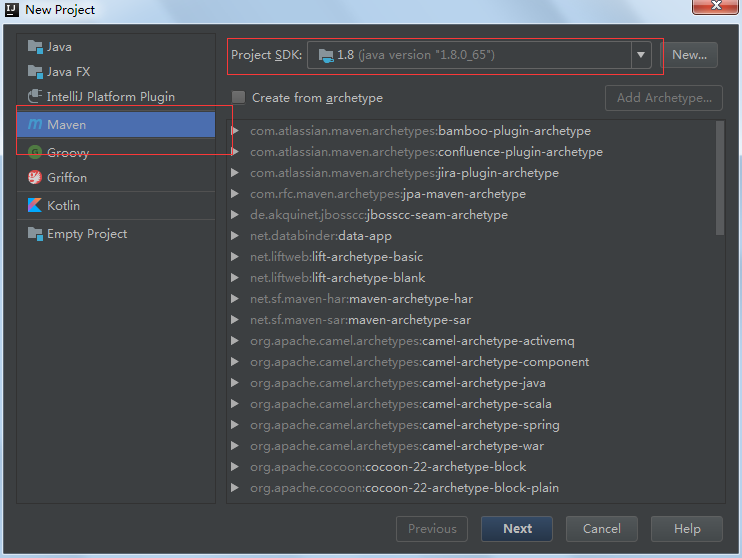
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
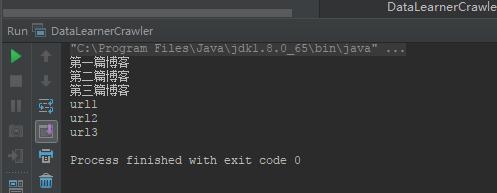
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。在这篇博客里,我们将简单介绍Jsoup解析HTML页面的操作。

使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
在使用HttpClient作为客户端请求数据的时候,我们常常需要以一个用户的身份多次请求一个网站内的多种资源。例如,我一次登录后,后面希望以这个身份继续访问不用重新登录。这里就可以使用cookie了。
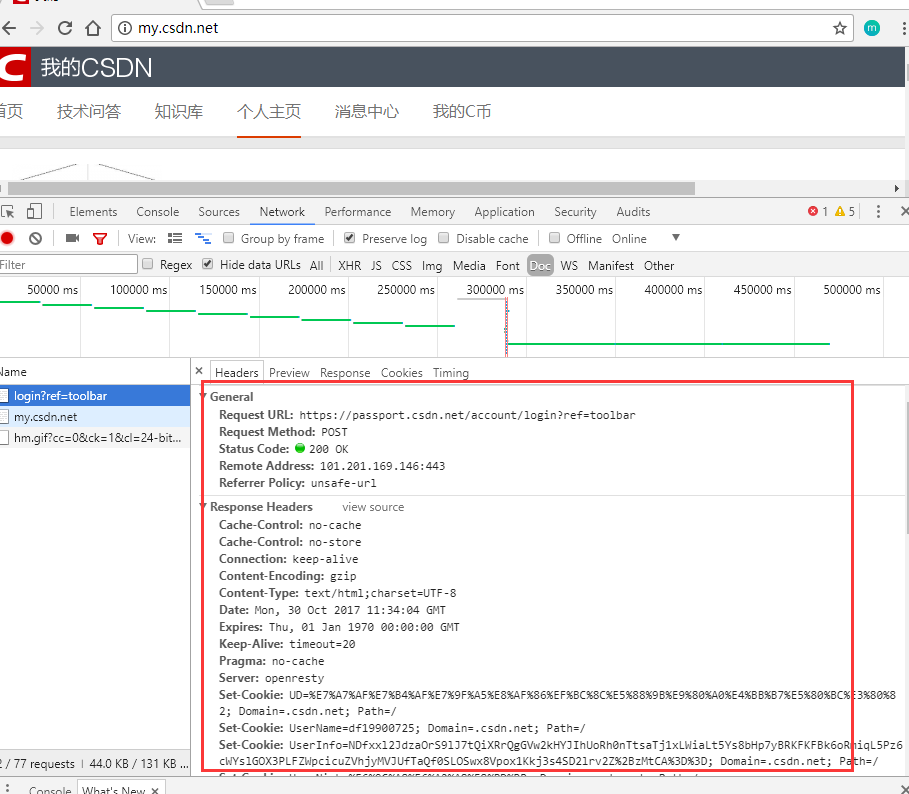
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录

今日推荐
MetaAI开源高质量高精度标注的图像数据集FACET:3.2万张图片、5万个主题,平均图像解析度达到1500×2000
OpenAI发布企业使用的ChatGPT:没有限制且更快的GPT-4、数据隔离、基于GPT-4的高级数据分析功能,但是暂不支持私有化部署
OpenAI官方Prompt教程:如何让ChatGPT扮演不同角色,完成教学任务
分解机(Factorization Machine, FM)模型简介以及如何使用SGD、ALS和MCMC求解分解机
Google发布第二代Gemini大语言模型,首个登场的Gemini 2 Flash Experimental,评测结果显示其能力已经超越上一代的Gemini 1.5 Pro!
线性数据结构之跳跃列表(Skip List)详解及其Java实现
预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning和prompt-tuning
智谱AI发布第二代CodeGeeX编程大模型:CodeGeeX2-6B,最低6GB显存可运行,基于ChatGLM2-6B微调