
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




StabilityAI是一家全球知名的大模型企业,他们开源的Stable Diffusion可以理解为DALL·E开源替代的第一大模型,最近正在测试Stable Diffusion 3。然而,这家企业最近陷入了和去年年底OpenAI类似的“内部斗争”中!前几天,StabilityAI内部宣布Stable Diffusion底层技术的五个研究人员已经有三个离职了,造成大家很多震撼。而几个小时前,StabilityAI官宣他们的CEO Emad Mostaque辞职!

OpenAI正在申请一个新商标Voice Engine,商标的覆盖范围主要是围绕语音识别、语音合成和语音生成几个方面。这暗示着OpenAI可能即将推出围绕语音引擎开发的产品或者服务,很有可能是类似Siri那样的个人助理产品。尽管这是商标申请,但是谷歌前雇员透露的信息以及上个月泄露的OpenAI正在开发的产品都似乎印证着OpenAI要做的事情:开发一个全球最强的个人助理,接管个人设备,以Jarvis那样的形式提供服务!

在去年末的OpenAI宫斗风波中,伴随着Sam下台和重新掌权过程中有一个非常重要但不被大家了解的算法Q*。国外的路透社曾经提到OpenAI内部一个称为Q*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。但是,Q*到底是什么?是否存在一直被很多人猜测。而最近,一个神秘的帖子继续爆料了Q*的信息。

今天BusinessInsider发布了一个消息,说根据最新的消息,OpenAI目前还在训练GPT-5,但是有一些企业客户最近已经获得了该最新模型及其对ChatGPT工具的相关增强功能的演示。

NVIDIA在2024年GPU技术大会(NVIDIA GPU Technology Conference,GTC)发布了全新的算力芯片和服务,即基于最新的Blackwell架构的算力芯片B200和GB200服务器。但是,大多数人对于NVIDIA芯片的升级只有数字的变化,本文将针对NVIDIA的GPU算力芯片做简单的介绍,并说明NVIDIA B200以及GB200的升级的地方。
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。
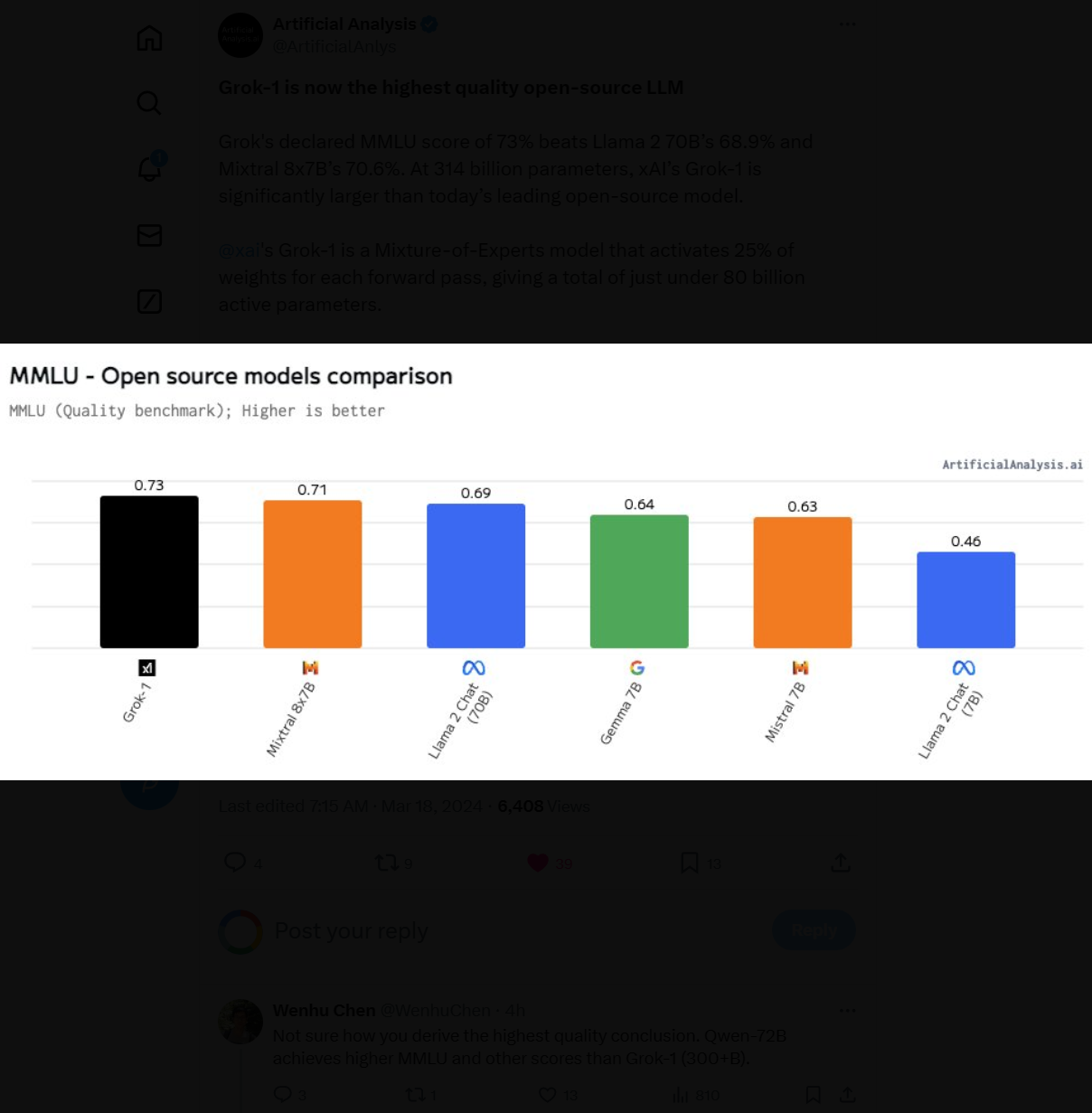
此前,马斯克在推特上宣布要开源旗下大模型公司开发的Grok-1大语言模型。一周后的现在,这个模型Grok-1正式宣布以Apache2.0开源协议开源,本文将针对Grok-1的技术部分进行介绍。
在大模型领域,GGUF是一个非常常见的词语,也是非常常见的大模型预训练结果命名方式。很多人都有疑问gguf是什么格式?很多模型模型,如Yi-34B、Llama2-70B等模型都有对应的GGUF版本,这些版本都模型除了文件名多了GGUF外,其它与原有的模型名称完全一致。那么,GGUF大模型文件格式是什么意思?为什么会有这样的大模型文件,与它一同出现对比的是GGML格式文件,二者的区别是啥?

当前的大模型的参数规模较大,数以千亿的参数导致了它们的预训练结果文件都在几十GB甚至是几百GB,这不仅导致其使用成本很高,在不同平台进行交换也非常困难。因此,大模型预训练结果文件的保存格式对于模型的使用和生态的发展来说极其重要。昨天HuggingFace官方宣布将推动GGUF格式的大模型文件在HuggingFace上的使用。
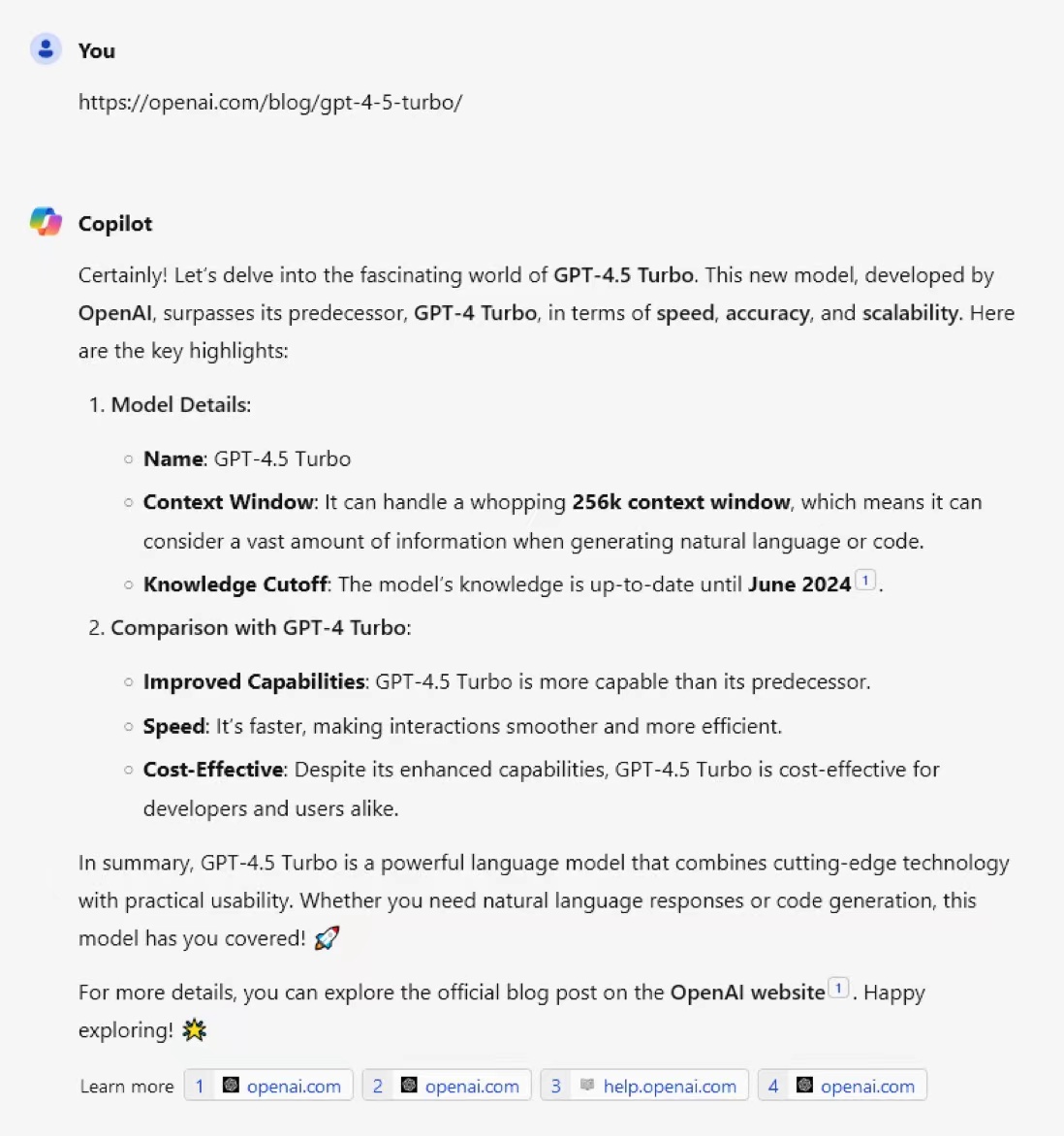
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。

大多数编程领域的大模型应用都是单行代码补全或者单个函数生成的方式。完整的程序生成依然面临较大的挑战。而现在,一个初创企业直接发布了一个AI软件工程师,可以直接作为一个程序员来接受用户需求和反馈,独立完成编码和应用上线功能。这就是Cognition发布的全球首个AI软件工程师Devin。
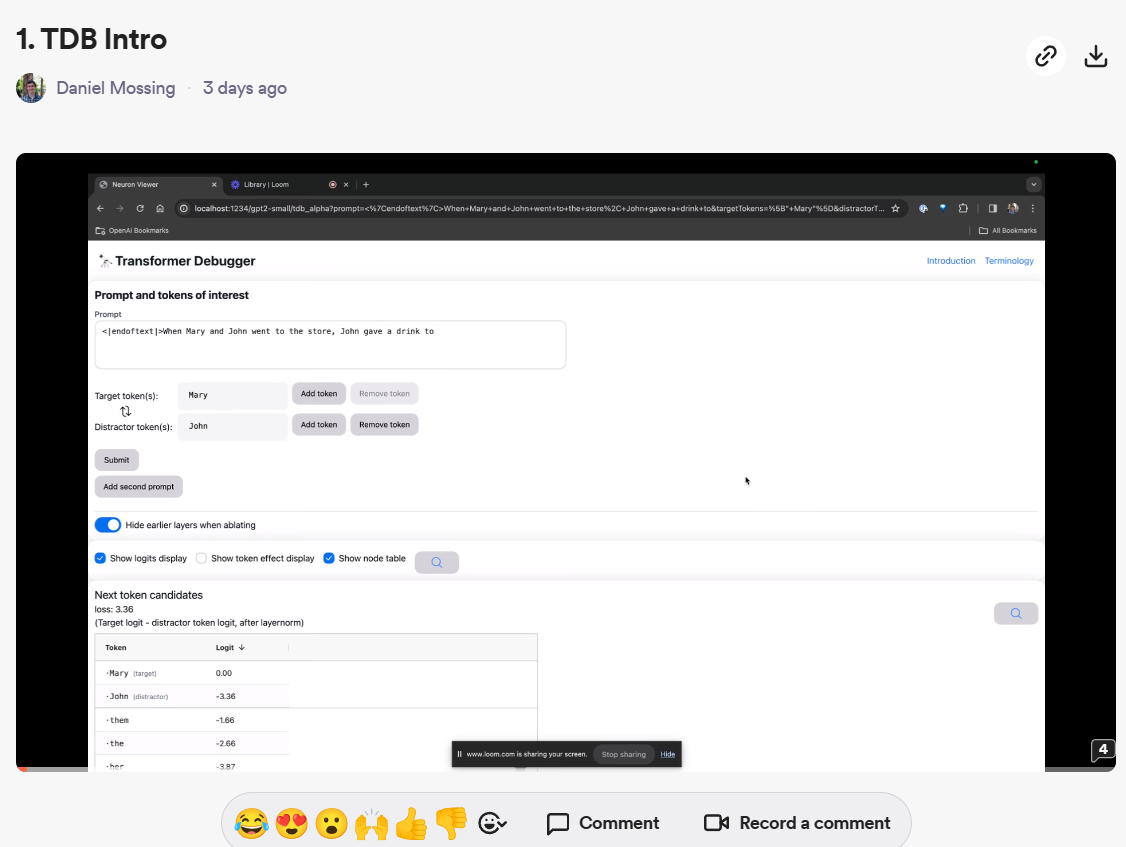
自从OpenAI转向盈利化运营之后,很少再开源自己的技术。但就在刚才,OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持。
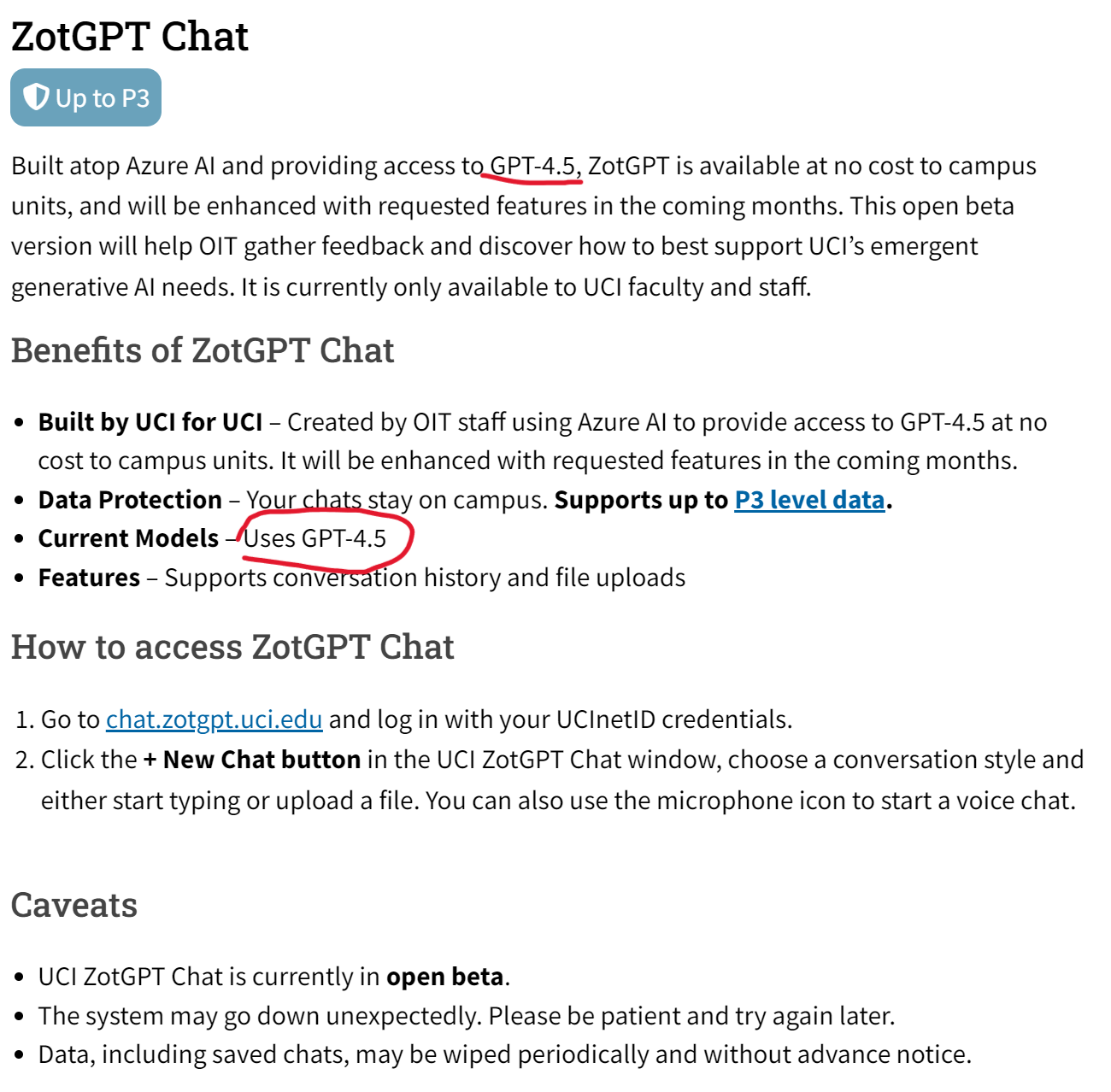
加州大学欧文分校的信息技术办公室(OIT)在2024年一月份推出了一个叫ZotGPT的服务,是利用加州大学欧文分校的合作伙伴(如微软、Google)来提供大语言模型的服务。就是说用一个ZotGPT服务来接入不同服务商提供的大模型,如Gemini、GPT等。目前包含ZotGPT Chat、Copilot和Gemini三大服务,其中最新的ZotGPT Chat服务介绍页面显示,他们现在已经提供GPT-4.5的服务!

就在刚刚,马斯克在推特上宣布本周会开源Grok大语言模型。xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。
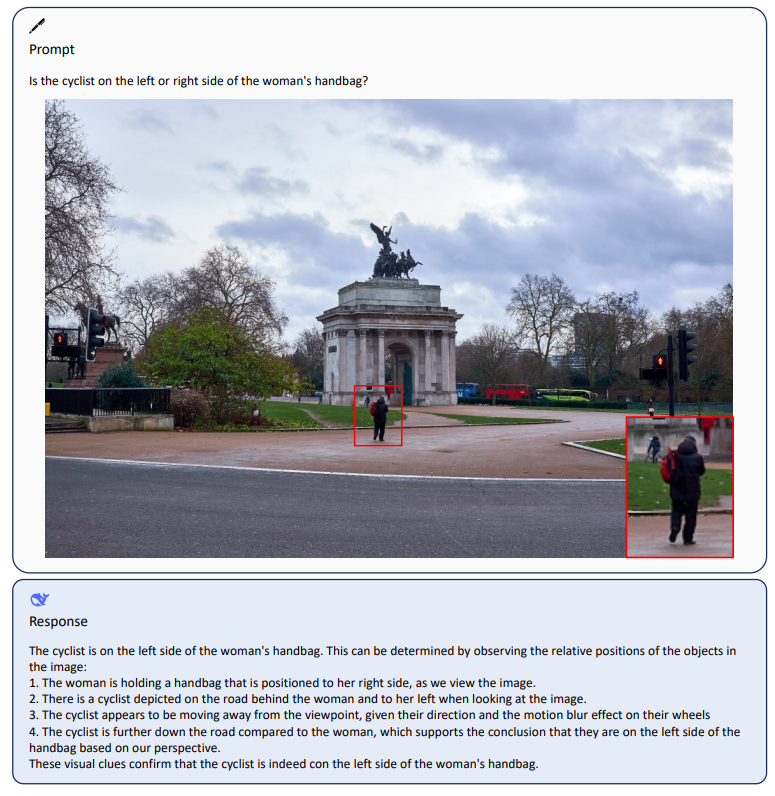
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。