
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
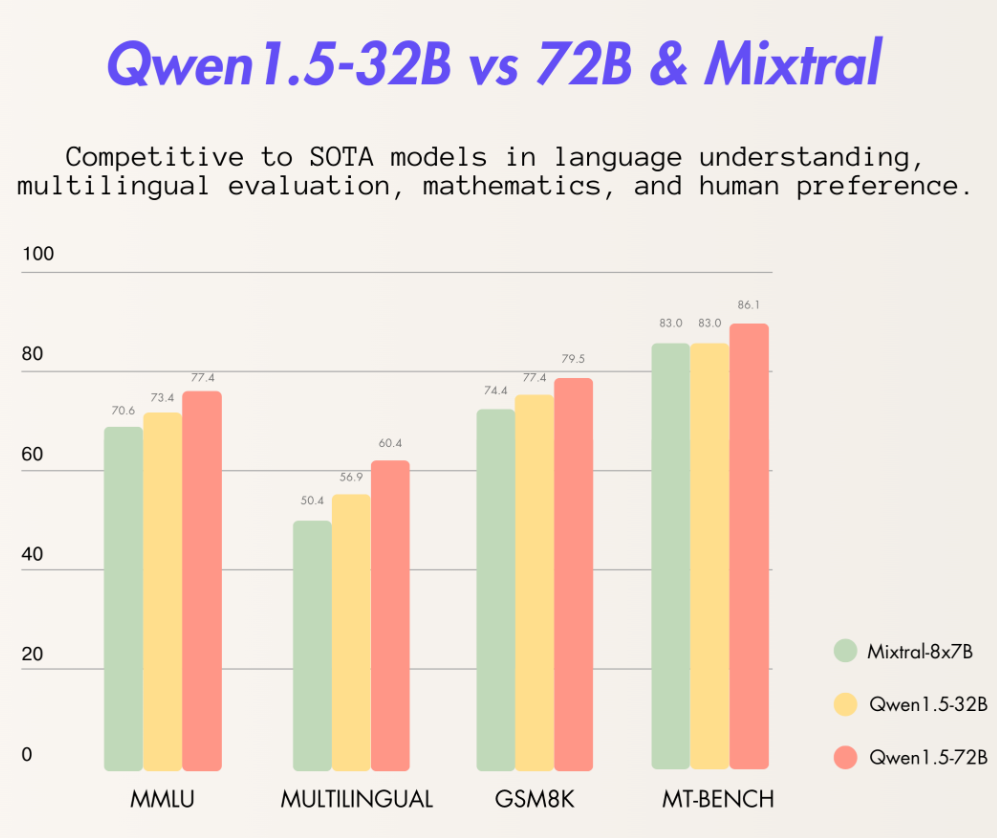
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。
今日推荐
如何提高大语言模型作为Agent的能力?清华大学与智谱AI推出AgentTuning方案
分解机(Factorization Machine, FM)模型简介以及如何使用SGD、ALS和MCMC求解分解机
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)
让大模型支持更长的上下文的方法哪个更好?训练支持更长上下文的模型还是基于检索增强?
马斯克创造的新的大模型企业xAI的大模型GrokAI模型评测结果出炉~MMLU与代码评分超过ChatGPT-3.5
Dask concat throws ValueError: Shape of passed values is (xxx, xxx), indices imply (xxx, xxx)
微软开源DeepSpeed Chat——一个端到端的RLHF的pipeline,可以用来训练类ChatGPT模型。