分类和Logistic回归
预测连续值(如房价),可以通过线性回归zhongd中的线性函数来做,只要设定输入值(如房子大小)即可,但是有时候,我们希望去预测一个离散的变量,比如说预测一个栅格像素密度是否表示成数字 “0”或者“1”,此时,线性回归的效果就显得非常差了。现在,我们将会聚焦二元分类(binary classification)问题,其中y仅取值0或者1。举例来看,如果我们想要尝试建立一个垃圾邮件分类器,那么x(i)表示邮件的一系列特征,y=1则表示这是一篇垃圾邮件,y=0则反之,这里的1表示积极反馈(positive class),0表示消极反馈(negative class),它们有时候也被表示成“+”或者“-”。
###Logistic regression
在线性回归中,我们通常用线性函数y=hθ(x)预测x(i)的y(i),然而这不能解决预测二元分类标签(y(i)∈{0,1})的问题。当我们知道y∈{0,1}时,hθ(x)的取值比1大或者比0小则显得没有任何意义。
于是,我们将假设hθ(x)的形式表示如下:
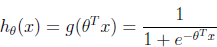



那么,鉴于logistic回归模型,如何确定θ来满足它呢? 下面,我们来看看最小二乘回归,它可以在一组假定下通过求导来作为最大似然估计。
首先,假定:


假定有m个训练样本,那么参数的似然可被表示如下:


那么问题来了,如何最大化似然呢?
和线性回归中的求导类似,我们可以使用梯度上升方法,所以写成向量形式,更新规则就可以被表示成
下面我们将用一个训练样本(x,y)来开始工作,通过偏导来展开随机梯度上升:


于是,随机梯度上升规则如下:

如果和LMS更新规则进行比较的话,我们可以发现更新规则是一样的,但是这确实不同的算法,因为hθ(x(i))在这里被定义为非线性函数θTx(i)。
###思考: 1、在众多的关于BPR的推荐问题文献中,我们可以发现sigmoid损失函数的普遍使用,而且文献中的建模以及优化求解过程与logistic回归的过程十分相似,由此我们大胆猜想,BPR来做推荐是不是就是logistic回归的应用?
2、不同的算法和学习问题却以相同的更新规则结束,是巧合?还是有背后的原因?
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
