Python3.11最新特性来了,多个好特性提升!
1,509 阅读
上个月Python的3.11版本发布了第一个beta版本,3.11带来了很多非常棒的新特性,例如错误提示更加具体,可以定位到具体代码位置等,十分友好,建议大家关注。这里简单为大家介绍一下。
这个特性真的很好,之前的错误提示真的是不够准确,python的traceback真的是勉强到代码行。但是,3.11版本给了更加具体的提示。
例如,如下面的代码:
def get_divide(a, b):
try:
return a / b + a / (b - 1)
except ZeroDivisionError as err:
err.add_note("DataLearner在这里温馨提示,可能除数为0哦!")
raise
a = 1
b = 0
print(get_divide(a, b))
函数里面,a / b和a / (b - 1)都是容易出错的地方,在3.11里面,你可以得到下面的错误提示:
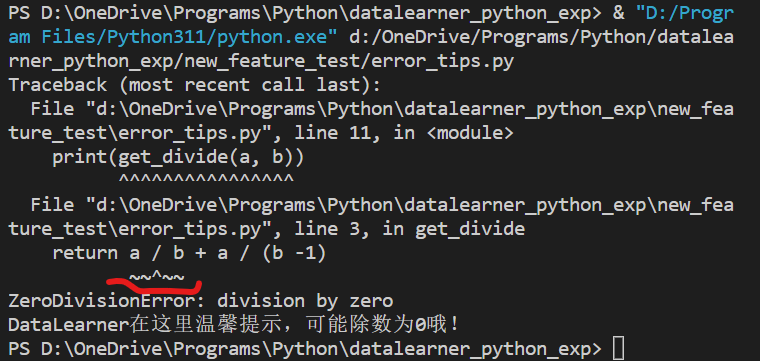
红色的地方有个波浪线,它会提示到具体是哪一个部分出错了。这个特性实在是太棒了。
此外,还可以在我们错误提示的地方加个note,这样的话,报错可以一并展示。非常贴心。
TOML 是一种旨在成为一个小规模、易于使用的语义化的配置文件格式,它被设计为可以无二义性的转换为一个哈希表。 “TOML”这个名字是“Tom's Obvious, Minimal Language”的首字母略写词。这个文件最主要的就是由key="value"这种形式的语法组成,如下所示,就是一个TOML文件示例:
# 這是一份 TOML 文件,来自Wikipedia
title = "TOML 範例"
[owner]
name = "Tom Preston-Werner"
dob = 1979-05-27T07:32:00-08:00 # First class dates
[database]
server = "192.168.1.1"
ports = [ 8001, 8001, 8002 ]
connection_max = 5000
enabled = true
显然,这种文件非常适合做配置型的文件,3.11版本的Python内置了tomllib,可以直接读取:
import tomllib
with open('.deepsource.toml', 'rb') as file:
data = tomllib.load(file)
不过,可惜的是,目前内置库不支持写成toml文件,只能读取。
在进行异步编程时,你经常会遇到这样的情况:你必须触发许多任务来并发运行,然后在它们完成后采取一些行动。例如,并行下载一堆图片,然后在最后将它们捆绑到一个压缩文件。
此前,Python处理异步任务完成后等待,需要手动调用asyncio.gather收集所有任务,这意味着手动管理识别所有的任务,一般是将所有任务创建之后加入到列表,再asyncio.gather(*tasks)。最新的3.11版本增加了一个新的API,可以创建一个上下文,在这里所有的任务完成之后才会继续执行下一个:
flight_schedule = {
'boston': [3, 2],
'detroit': [7, 4],
'new york': [1, 9],
}
async def main():
async with asyncio.TaskGroup() as tg:
for city, (departure_time, duration) in flight_schedule.items():
tg.create_task(simulate_flight(city, departure_time, duration))
print("Simulations done.")
asyncio.run(main())
这就是async with asyncio.TaskGroup() as tg,只要将所有需要异步完成的任务都放在这个代码里面,那么它就会让这个里面所有任务完成之后再继续跑后面的任务了,相比之前更加优雅简单。
这里还有一个比较有意思的特性,就是这些异步任务执行的时候可能会出现某些任务失败,某些任务成功的情况。在此之前,Python的处理很简单粗暴,就是遇到任意一个任务失败,整个程序崩溃。但是在这个async with asyncio.TaskGroup() as tg下的所有任务运行遇到失败的情况,它会把错误收集到一个错误组中,告诉你哪些是失败的。同时,如果你加上如下两种错误捕获的语句:
try:
asyncio.run(main())
except ExceptionGroup as eg:
print(f"Caught exceptions: {eg}")
或者
try:
asyncio.run(main())
except* ValueError as eg:
print(f"Caught ValueErrors: {eg}")
看到没,可以是except*,即既可以收集所有的错误到一个组中,也可以按照错误类型收集。
这是一个对深度学习和算法类的库十分重要的特性。Python在3.5支持了类型提示,也增加了泛型的支持。但是,泛型的定义依然只是灵活在了类型上,而对于长度可变,且类型不确定的这种场景的支持依然不足。
一个简单的例子是,加入你写了一个视频处理的算法,那么接受视频的参数可能是:
batch × time × height × width × channels
但是实际中,也许有其他的维度,或者更少的维度。这时候输入的参数长度就是可变化的。例如,我们的一个算法接受的输入定义为shape,那么,不同的对象shape包含的维度可能就不一样。那么,首先我们会定义一个shape的类型
from typing import Generic
from typing_extensions import TypeVarTuple
Shape = TypeVarTuple('Shape')
其次,我们的算法可以接受这个shape类型
class Array(Generic[*Shape]):
...
需要注意的是,Shape显然针对不同的输入有不同的情况,例如:
# 1维的例子,可能就是一个列表
items: Array[int] = Array()
# 3维的例子, X 轴, Y 轴 和 具体的数值
market_prices: Array[int, int, float] = Array()
那么,不管是那种,我们的算法由于定义的是可变泛型,因此对于上述的对象都可以处理。这就是可变泛型最大的用处。在做深度学习或者数值计算的时候,这个特性非常重要。
这个很有意思啊,有点像Java的子类的方法重载,但是这个使用很简单。例如,我们定义一个一个half()函数,正常浮点数就返回一半的结果,整数返回一半取整,列表就返回前半段结果。如果是之前,需要写一个函数,并针对输入类型判断处理,现在更简单,对方法声明singledispatch之后,就可以通过新的装饰器直接定义函数了:
from functools import singledispatch
@singledispatch
def half(x):
"""Returns the half of a number"""
return x / 2
@half.register
def _(x: int):
"""For integers, return an integer"""
return x // 2
@half.register
def _(x: list):
"""For a list of items, get the first half of it."""
list_length = len(x)
return x[: list_length // 2]
# Outputs:
print(half(3.6)) # 1.8
print(half(15)) # 7
print(half([1, 2, 3, 4])) # [1, 2]
真的十分简洁优雅。
目前,Python3.11版本发了第一个beta版本,但是这些新特性定下来后面基本不会有大的变化,更多应该是修修补补了。这里的错误提示真的是让人感觉十分不错,debug又简单了,哈哈哈。
参考1:https://deepsource.io/blog/python-3-11-whats-new/ 参考2:https://peps.python.org/pep-0646/#timebatch
