深度学习模型训练将训练批次(batch)设置为2的指数是否有实际价值?
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
简介
对于整数参数来说,固定在2的幂上是我们经常看到的一种软件工程习惯。例如,你可能听过这样的建议:为你的批次大小选择2的幂。Andrew Ng在他的一门deeplearning.ai课程中报告了64、128、256和512的典型批量大小,NVIDIA建议Tensor Cores选择8的倍数,甚至Goodfellow, Bengio & Courville在他们的《深度学习》一书中指出
一些种类的硬件通过特定尺寸的阵列实现更好的运行时间。特别是在使用GPU的时候,一般来说,2个批次可以提供更好的运行时间。
普通图像分类测试
我们先在一个大约有3000张图片的数据集上进行普通图片分类训练。训练是使用带有NVIDIA P100(不包含Tensor Cores)的Kaggle笔记本进行的。
微调包括一个现代的ConvNeXt、一个普通的ResNet和一个DeiT transformer模型,批次大小不同。 ResNet(80次epoch,批次大小为128和129):26分钟 DeiT(40次epoch,批次大小为64和65):39分钟 ConvNeXt(40个epoch,批次大小为64和65):37分钟 在下面的图中,你会看到批处理规模的颜色相似。你还会看到,不同批处理量的训练时间几乎是相同的。
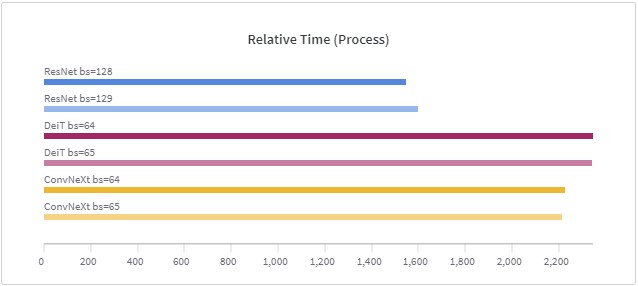
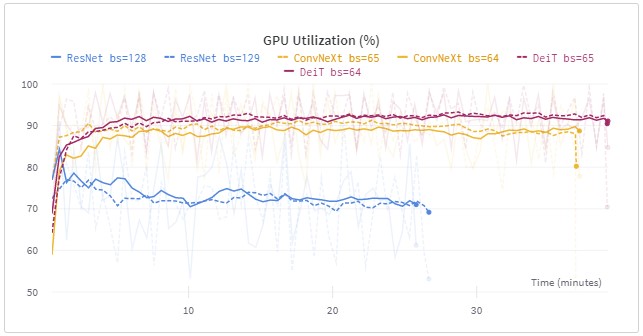
更重要的是什么?对于不同的批处理规模,GPU的利用率也是差不多的。ResNet为72%,ConvNeXt为89%,DeiT为92%。GPU的高利用率是一个强有力的指标,表明GPU是一个限制性因素。如果不同的、奇特的批量大小会影响到在GPU上进行并行计算的能力,我们应该在这里看到这一点。但实际上没有区别。
逐一测试批次大小
在逐一测试不同的批次大小时,情况仍然是一样的。下图显示了用不同的批处理规模训练ConvNeXt的5个epoch的运行时间。 现在,正如预期的那样,当增加批处理量时,运行时间会减少,直到它达到一个极限,但在特定的批处理量上没有突然中断。这更表明,对2的幂的限制是不必要的。

我们在哪里出错了?
为什么选择2的幂的经验法则不能被我们的实验所证实?
我认为这主要是因为并行化完全不局限于一个批次中的单个样本。像PyTorch、TensorFlow和cuBLAS这样的库已经进行了大量的优化,以有效地使用GPU。因此,一个奇怪的批次大小并不会让它们偏离轨道。
不过,我读过的许多讨论训练程序、学习率选择等的论文都只测试了某些批次大小。并没有设置过其它的数值。
最后,我们所有人(是的,甚至计算机科学家),都喜欢简单的解释和规则。像 "流式多处理器接收32个线程的warps "这样的理由很快就会被提出来,听起来很合理,而且传播很广。
如果你想深入了解底层的实现细节(包括CUDA编程),我强烈推荐康奈尔科技的MiniTorch。你也可以在这个Kaggle笔记本中重现我的测量结果,并根据自己的想法进行调整。
那张量核心和8的倍数呢?
我从一个读者那里得到提示(谢谢,Mohamed Yousef!),P100没有张量核心,有张量核心的GPU可能会显示不同的行为。我在RTX A4000(192个Tensor Cores)上重复运行。虽然训练的速度总体上比较快,但这个设置的结论并没有改变。训练ResNet50的80个epochs,两种批处理规模都花了16分钟。
我没有nvprof运行,所以可能是Tensor Cores无法启动的原因,而不是批量大小。我认为这仍然是一个公平的比较,因为当你需要nvprof你的训练以挤出最后一点性能时,你不再依靠任何经验法则了。
你可以在Tips for Optimizing GPU Performance Using Tensor Cores获得更多关于使用张量核心优化GPU性能的提示。请注意,那里显示的数字主要是对单层的测量,而不是像本博客中的端到端训练。
如何选择批处理的大小
简单地说:即使对于给定的数据集和模型架构,也没有单一的 "最佳 "批次大小。你需要权衡训练时间、内存使用、正则化和准确性。 较大的批处理量会训练得更快,消耗更多的内存,但可能显示较低的准确性。 你可以在Ayush Thakur的博文What's the Optimal Batch Size to Train a Neural Network? 中找到更多的细节和精彩讨论的链接。
一些不同的意见
不过,尽管如此,NVIDIA的研究人员JFPuget在推特上回复说,其实是有差别的,也就是前面说的,如果混合精度下在带有张量核心(tensor cores)的GPU上训练,设置成2的幂会影响到训练速度,尽管可能并不是很大。他的经验是曾将让同事将批次大小从132改成128之后训练速度提升了10%左右。而Thomas Bierhance没有测试混合精度下,在带有张量核心的GPU上的结果。
为此,威斯康星大学麦迪逊分校的Sebastian Raschka教授在几天前测试了混合精度下在带有张量核心的GPU上训练结果,结论依然是没有差别。

上图是V100上测试结果,很遗憾,没有差别。同时,即使是用4个V100做并行训练,结论也是一样。所以Sebastian Raschka认为,设置为2的幂真的没有必要。也就是说当你有一个批次大小为128的模型,你想运行,但是你的内存不够,那么,在将其缩减到64之前,用120和100的批处理大小来训练该模型可能是可以的。
然后NVIDIA的另一位PyTorch工程师也提醒他,如果使用PyTorch启用cudnn.benchmark的话,对于新的input shape会去解析kernels,这时候如果使用不同的batch size可能会有一些性能影响,不过这个指挥影响第一个迭代,如果模型运行时间很长,那么影响不大。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
