缺少有标注的数据集吗?福音来了——HuggingFace发布few-shot神器SetFit
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。
SetFit在很少标记的数据训练中也获得了十分好的性能。例如,在用户评论情感分类数据中,在每一种情感分类的类别下仅仅标注8个实例,也让SetFit获得了很高的分类效果,比在3000个标注数据上进行微调的RoBERTa模型效果更好。RoBERTa是Yinhan Liu在2019年发布的一个模型,它以BERT架构为基础,但更改了超参数的选择使得模型可以在较少的资源下获得更好的性能。
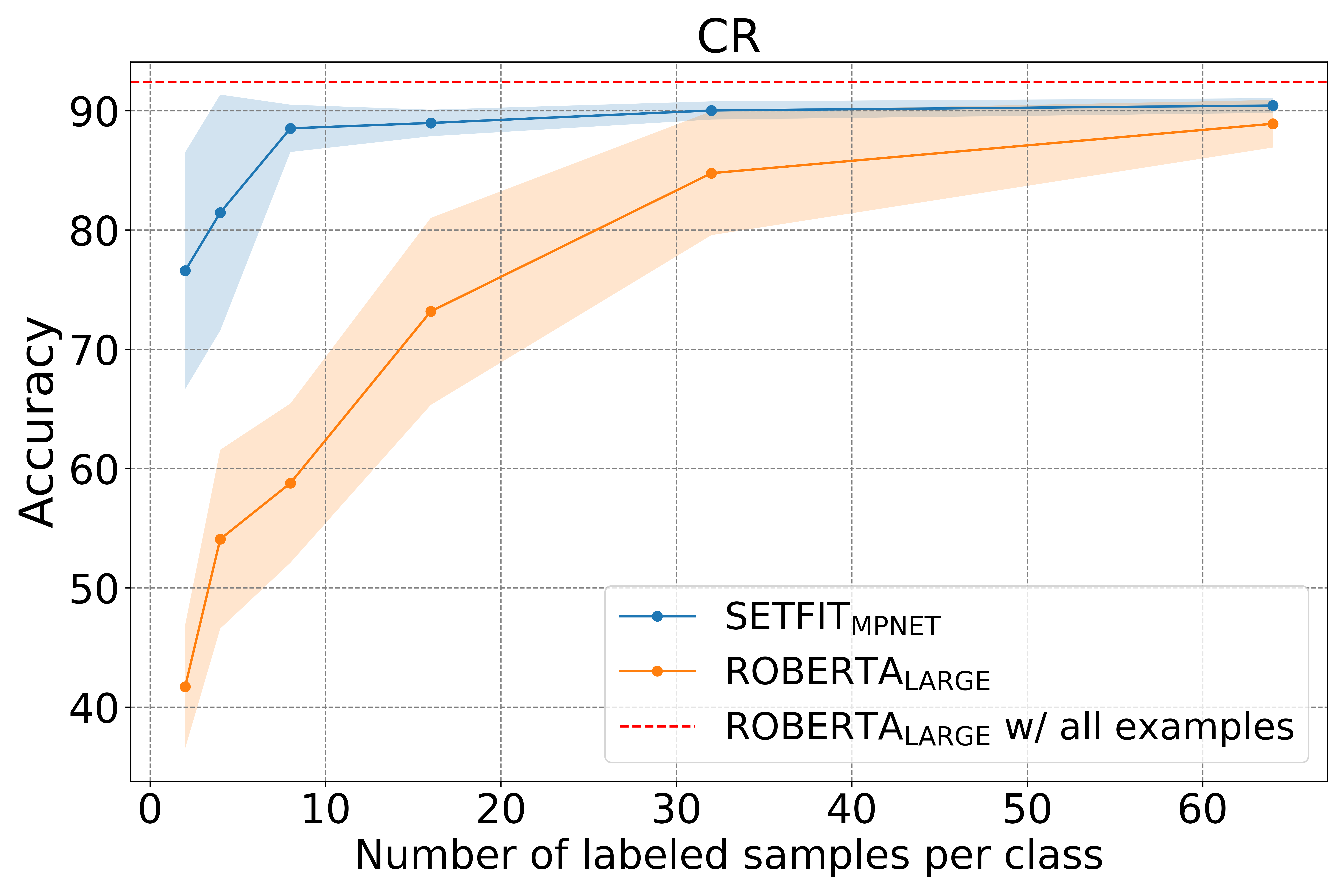
与其他少量标记的学习方法相比,SetFit有几个独特的特点。
🗣 没有提示或口述者。目前的微调技术需要手工制作的提示语或口头语来将例子转换成适合底层语言模型的格式。SetFit通过直接从少量标记的文本例子中生成丰富的embedding,完全免除了提示。
🏎 快速训练。SetFit不需要像T0或GPT-3那样的大规模模型来实现高准确率。因此,它的训练和运行推理的速度通常要快一个数量级(或更多)。
🌎 多语言支持。SetFit可以与Hub上的任何Sentence Transformer一起使用,这意味着你可以通过简单地微调多语言checkpoint对文本进行分类。
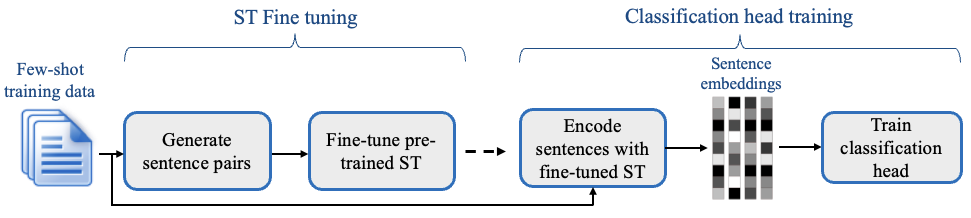
SetFit的设计考虑到了效率和简单性。SetFit首先在少量已标记的例子(通常每类8或16个)上对Sentence Transformer模型进行微调。然后,在经过微调的Sentence Transformer产生的embeddings上训练分类器头。
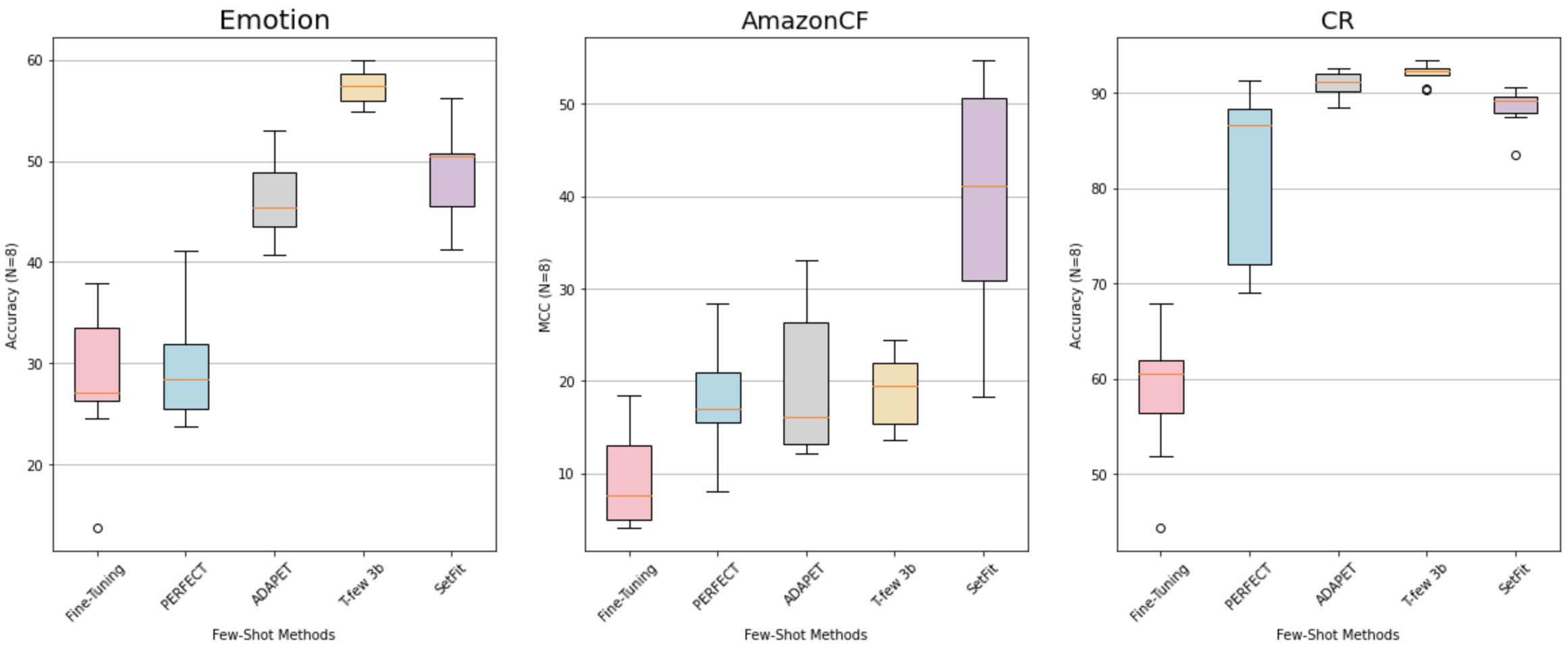
尽管SetFit比现有的few-shot模型小得多,但在各种基准上,SetFit的表现与最先进的few-shot模型相当或更好。在RAFT,一个少量分类基准上,SetFit Roberta(使用all-roberta-large-v1)以3.55亿个参数胜过PET和GPT-3。它略低于人类的平均表现和110亿参数的T-few--一个规模是SetFit Roberta的30倍的模型。SetFit在11个RAFT任务中的7个任务上也优于人类基线。
在其他数据集上,SetFit在各种任务中都显示出鲁棒性。如上图所示,在每类只有8个例子的情况下,它通常比PERFECT、ADAPET和微调的vanilla变换器更优秀。SetFit也取得了与T-Few 3B相当的结果,尽管它是无提示的,而且体积小27倍。
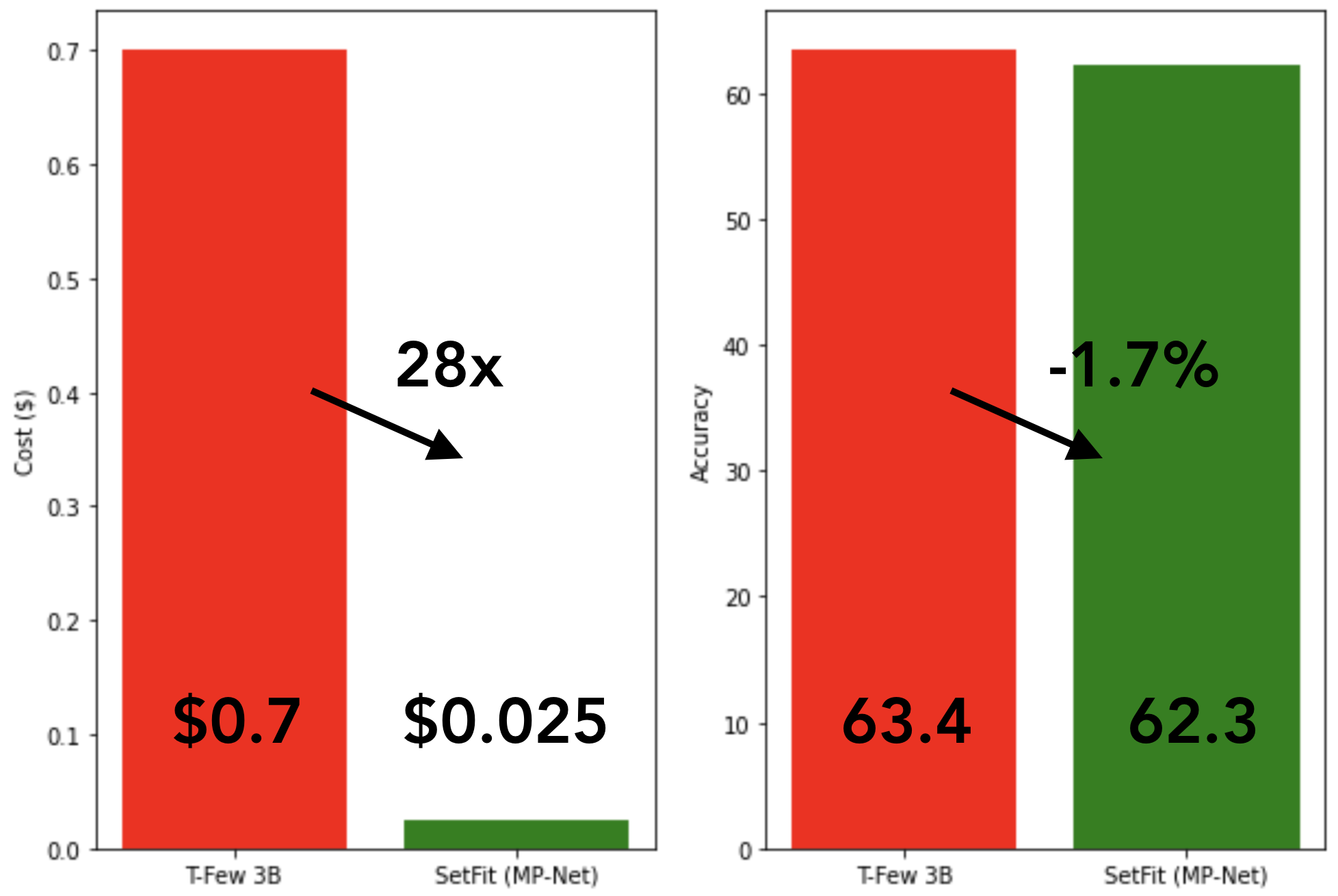
由于SetFit以相对较小的模型实现了较高的准确率,因此它的训练速度非常快,而且成本更低。例如,在NVIDIA V100上训练SetFit,有8个标记的例子,只需要30秒,成本为0.025美元。相比之下,训练T-Few 3B需要NVIDIA A100,需要11分钟,同样的实验成本约为0.7美元--多了28倍。事实上,SetFit可以在单个GPU上运行,比如在Google Colab上发现的那些GPU,甚至可以在CPU上训练SetFit,只需几分钟就可以完成! 如上图所示,SetFit的速度提升是在模型性能相当的情况下实现的。在推理方面也取得了类似的收益,提炼SetFit模型可以带来123倍🤯的速度提升。
论文地址:https://arxiv.org/abs/2209.11055 代码地址:https://github.com/huggingface/setfit 数据和模型地址:https://huggingface.co/SetFit
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
