12倍推理速度提升!Meta AI开源全新的AI推理引擎AITemplate
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
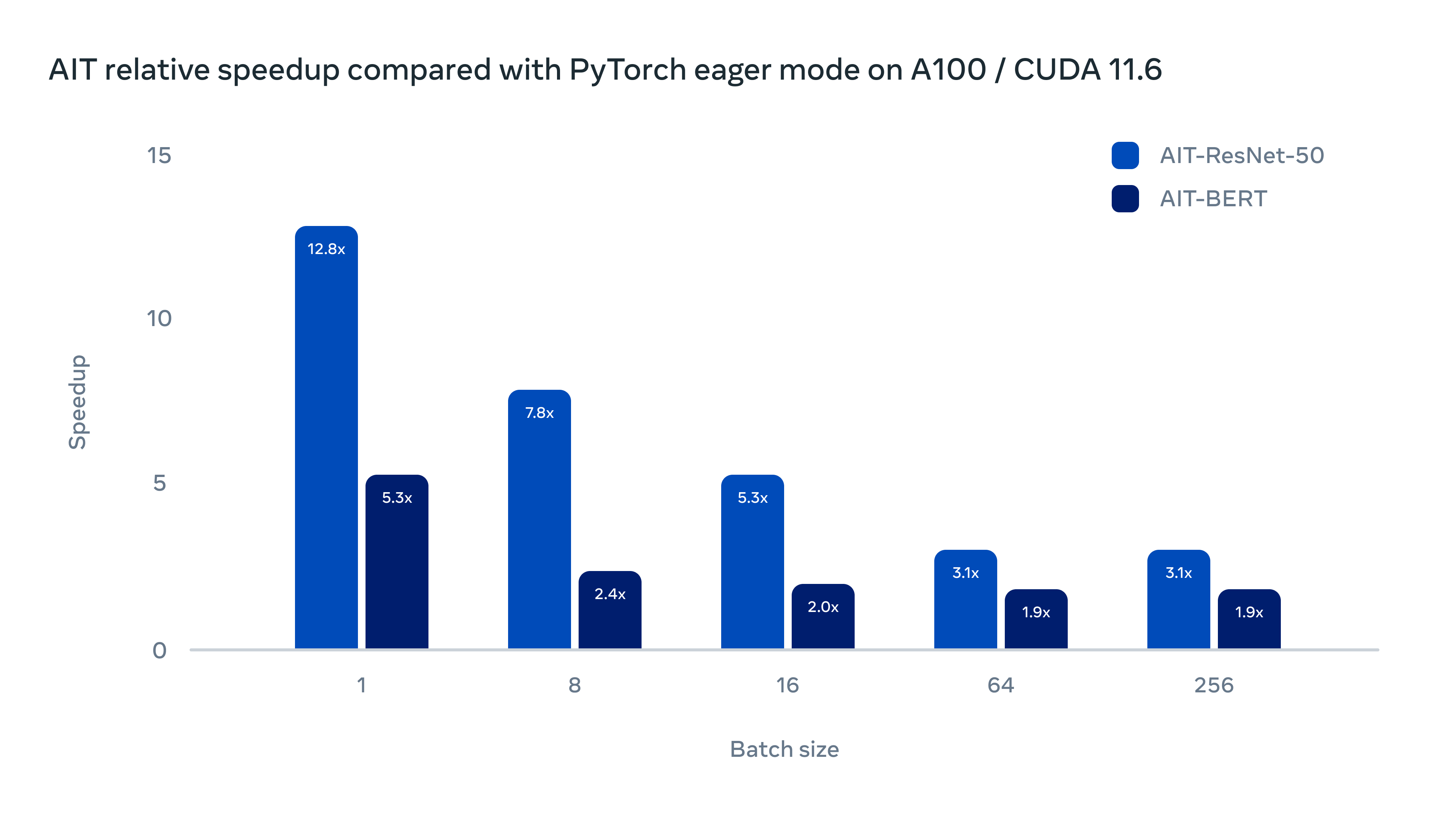
下图是AIT在A100/CUDA 11.6上的表现。与PyTorch的eager模式相比,ResNet-50最高有12倍性能的提升,BERT最多有5.3倍的性能提升,可以看到效果十分惊艳!
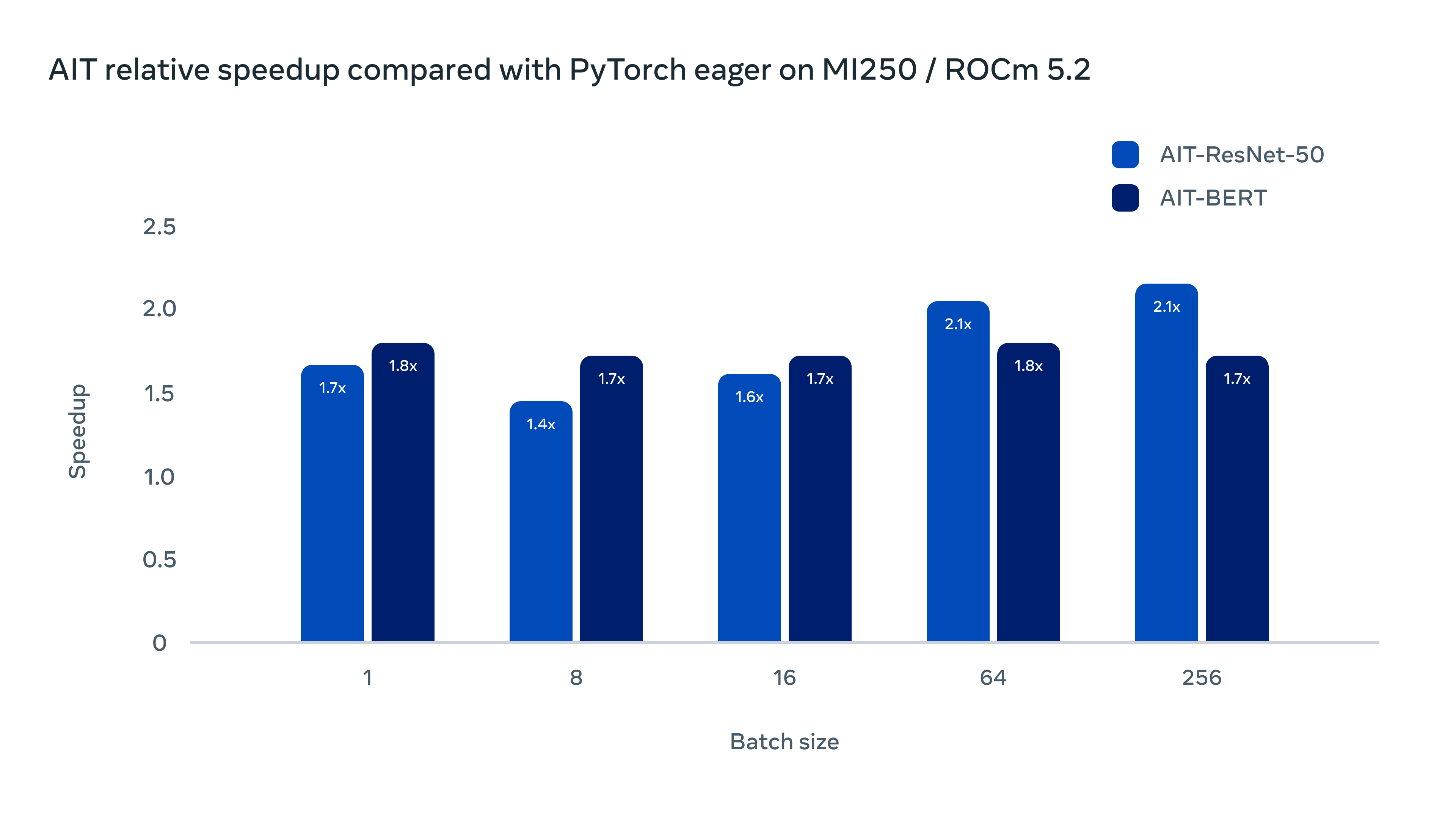
在AMD的软硬件平台上也有很好的表现(MI250/ROCm 5.2)
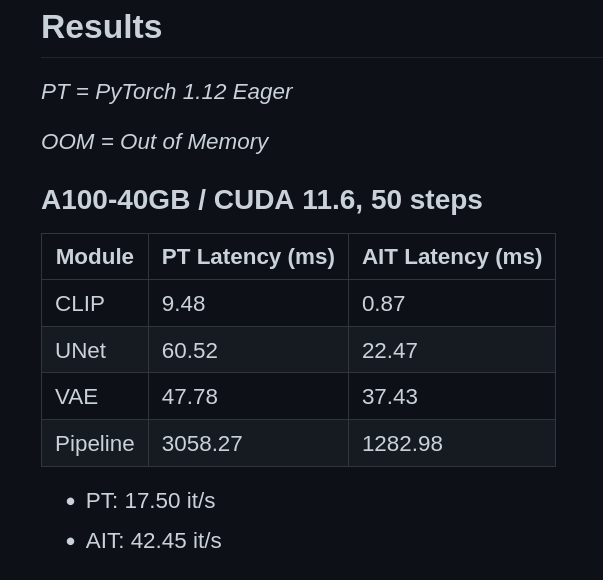
已经有人测试过使用AITemplate也可以提升Stable Diffusion的速度:
关于AITemplate具体相关内容:
为什么要开发AITemplate
近几年,大模型的发展虽然取得了很好的效果,但是运行速度相对而言还是慢很多。
GPU在提供部署人工智能模型所需的计算方面发挥着重要作用,特别是对于计算机视觉、自然语言处理和多模态学习中的大规模预训练模型。目前,人工智能从业者在选择高性能的GPU推理解决方案时,灵活性非常有限,因为这些都集中在特定平台和封闭的黑盒子运行时。为一个技术供应商的GPU设计的机器学习系统必须完全重新实现,以便在不同供应商的硬件上工作。由于复杂的运行时环境中的硬件依赖性,这种灵活性的缺乏也使得构成这些解决方案的代码难以迭代和维护。
此外,人工智能生产管道往往需要快速开发。开发人员急于尝试新的建模技术,因为该领域正在迅速发展。虽然像TensorRT这样的专有软件工具包提供了定制的方式,但它们往往不足以满足这一需求。此外,封闭的专有解决方案可能使快速调试代码更加困难,降低了开发的敏捷性。
为了应对这些行业挑战,Meta AI开发了AITemplate(AIT)并将其开源,这是一个统一的推理系统,为AMD和NVIDIA GPU硬件提供独立的加速后端。它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。有了AIT,现在可以在两个GPU供应商的硬件上运行高性能的推理。与PyTorch的eager模式相比,我们使用AIT在NVIDIA GPU上实现了高达12倍的性能改进,在AMD GPU上实现了4倍的性能改进。
AITemplate简介
部署AITemplate是很直接的。AI模型被编译成一个独立的二进制文件,没有依赖性。这个二进制文件可以在任何具有相同硬件和较新的CUDA 11 / ROCM 5版本的环境中工作,这导致了良好的向后兼容性。这在生产环境中非常重要,因为稳定性和向后兼容性是至关重要的。AITemplate还提供了开箱即用的广泛使用的模型(如VisionTransformer、BERT、Stable Diffusion、ResNet和MaskRCNN)。这简化了部署过程,使从业人员能够轻松部署PyTorch预训练的模型。
AITemplate(AIT)是一个Python框架,它将深度神经网络转化为CUDA(NVIDIA GPU)/HIP(AMD GPU)C++代码,以实现闪电般的推理服务。AITemplate的亮点包括。
- 高性能:接近屋顶线fp16 TensorCore(NVIDIA GPU)/MatrixCore(AMD GPU)在主要模型上的性能,包括ResNet、MaskRCNN、BERT、VisionTransformer、Stable Diffusion等。
- 统一、开放、灵活。用于NVIDIA GPU或AMD GPU的无缝fp16深度神经网络模型。完全开放源代码,乐高式的易扩展高性能基元,支持新的模型。支持比现有解决方案更全面的融合,适用于两种GPU平台。
AITemplate安装使用
AITemplate不依赖第三方库或运行时,如cuBLAS、cuDNN、rocBLAS、MIOpen、TensorRT、MIGraphX等。每个模型都被编译成一个独立的可移植二进制文件,它可以在任何具有相同硬件的软件环境中使用。
AITemplate生成的Python运行时可以将PyTorch张量作为输入和输出,而无需额外的拷贝。对于没有PyTorch的环境,AITemplate的Python/C++运行时是独立的。
AITemplate为在codegen中进行扩展提供了一种直接的方法。要在AITemplate中添加一个新的运算符或新的融合内核,大多数情况下只需要添加两个Python文件:一个是图节点定义,另一个是后端codegen。文本头文件中的CUDA/HIP内核可以直接在codegen中利用。
硬件要求:
- NVIDIA。AIT只在SM80以上的GPU(安培等)上测试。并非所有内核都能在旧的SM75/SM70(T4/V100)GPU上工作。
- AMD:AIT只在CDNA2(MI-210/250)GPU上测试。对于旧的CDNA1(MI-100)GPU可能存在编译器问题。
AITemplate的发布周期为90天。在接下来的一到两个版本中,我们将重点关注以下内容:
- 废除FlashAttention。将CUDA注意力的计算统一到Composable Kernel(AMD GPU)风格的背对背融合上,以提高性能,增加NVIDIA GPU Transformer用户的灵活性。
- 移除内核剖析要求。
- GEMM + LayerNorm融合,GEMM + GEMM融合,Conv + Conv融合。
- 更好的动态形状支持。专注于变形器中的动态序列。
- 更多的模型模板。提供带有控制流和容器的模型模板。
- 更多的自动图形传递。解除手动重写模型以获得最佳性能。
- 在AMD后端启用更多的融合功能。
- 一些正在进行的/潜在的工作,不会出现在下一个短期版本中。
- 自动转换Pytorch-FX、ONNX、Open-XLA和其他格式的模型。
- 量化模型(int8/fp8/int4)支持。
- 针对AMD Epyc CPU的AVX2/AVX-512的可组合内核CPU扩展。
具体相信信息大家可以去GitHub上查看使用:https://github.com/facebookincubator/AITemplate
