为什么最新的大语言模型(如ChatGPT)都使用强化学习来做微调(finetuning)?
最近,随着ChatGPT(ChatGPT模型卡:https://www.datalearner.com/ai-resources/pretrained-models/chat-gpt )的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT(BERT模型卡:https://www.datalearner.com/ai-resources/pretrained-models/BERT )横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习(Reinforcement Learning, RL)来做微调(finetuning),而不是用之前大家所知道的有监督的学习(supervised learning,SL)。这是为什么呢?
著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
原因1:预测response比预测排序更重要
在有监督的学习中,我们通常都将真实标签和模型输出之间的最小化作为目标。对某些提示(certain prompts)来说,标签(Labels)实际上是对response的排名分数。因此,使用常规的有监督学习对模型进行微调实际上是让模型来预测排序,而不是让模型来预测response。
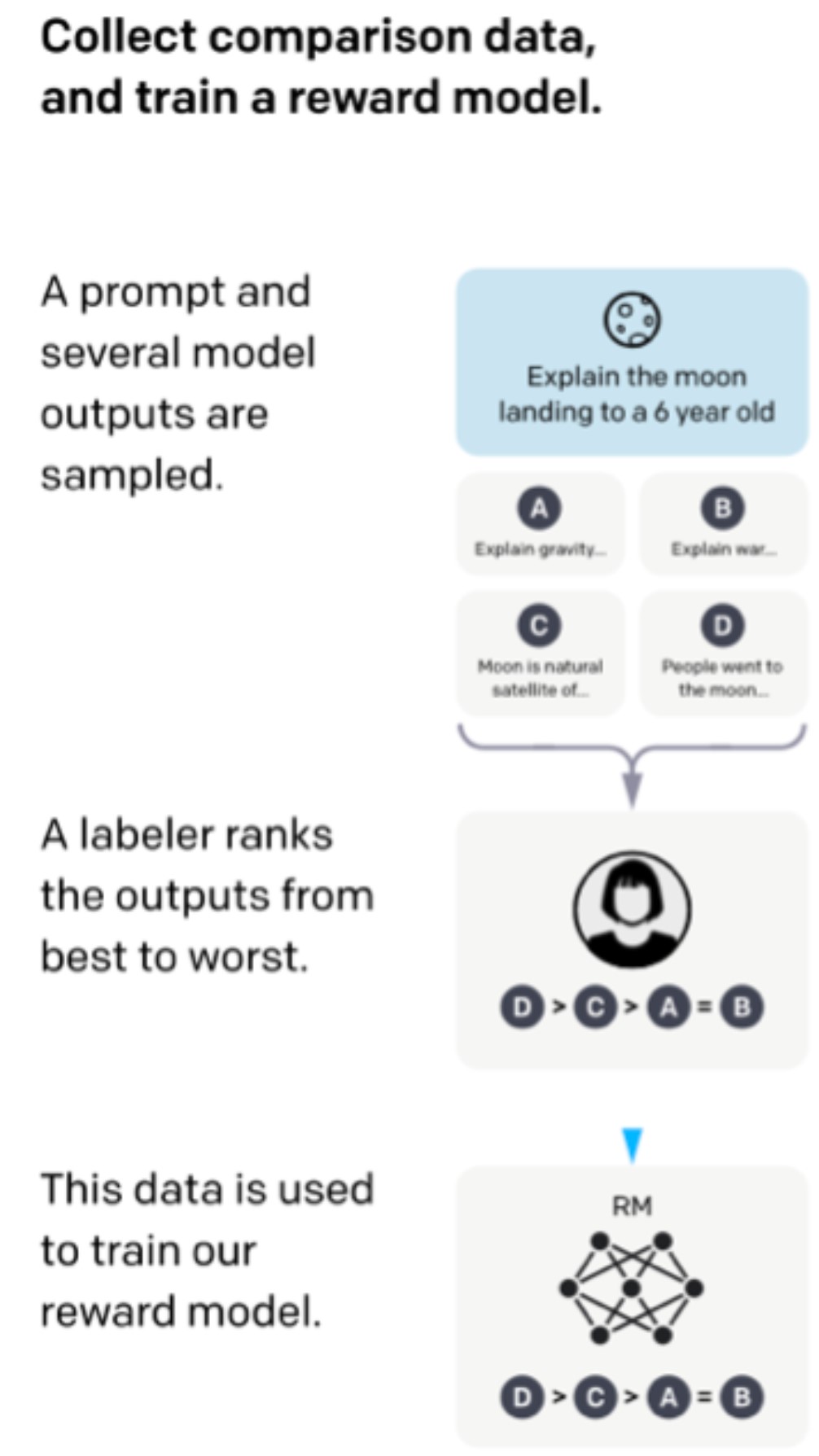
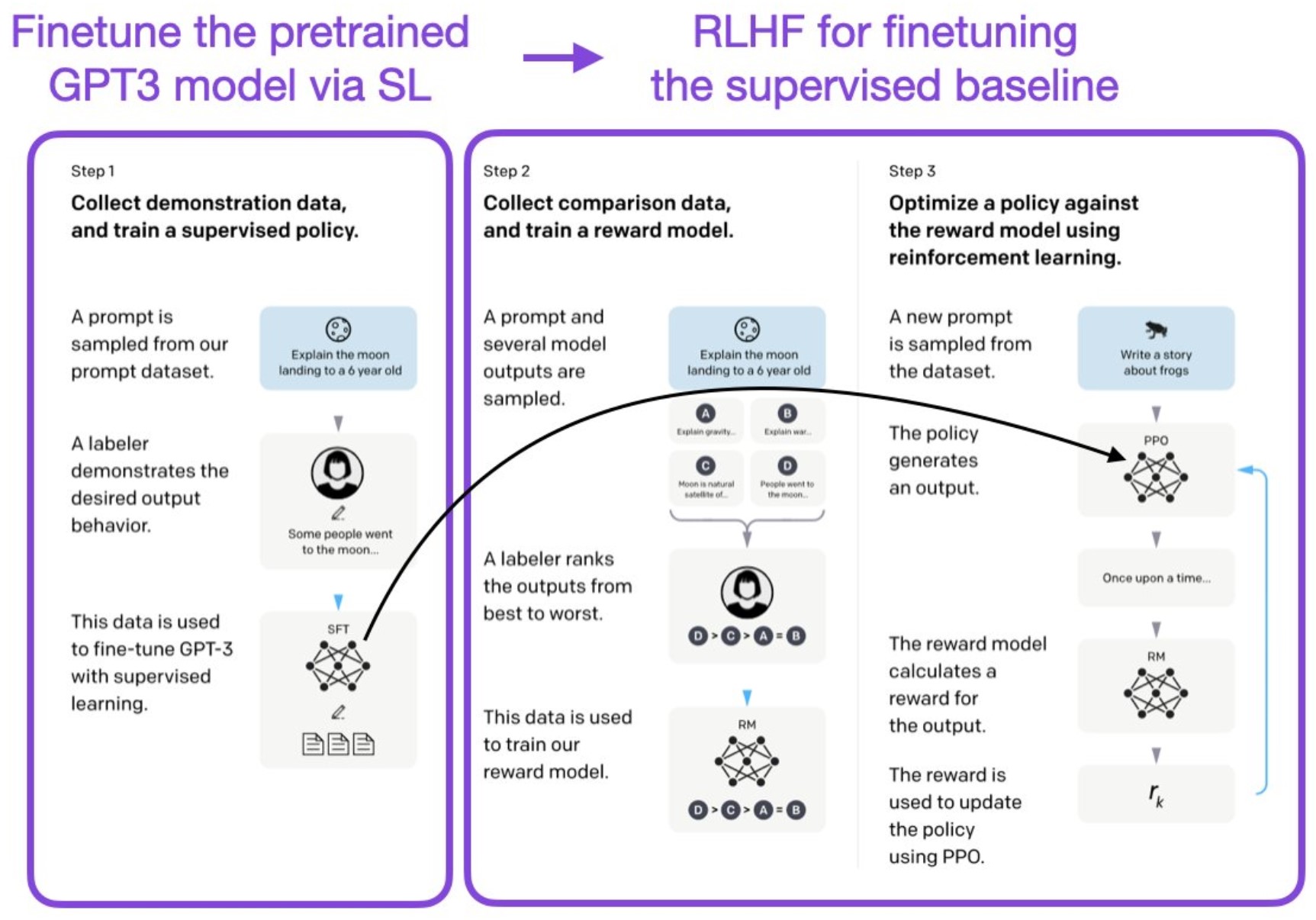
上图是基于prompt微调语言模型的一个过程,可以看到,当前大语言模型的微调过程是西安基于prompt抽取几个输出,然后labeler将答案排序,最后用排序结果来训练奖励模型。可以看到,模型的训练重点是要求模型可以预测更好的response。
原因2:多轮对话需要累积奖励
好吧,那么我们为什么不把这个任务重新表述为一个受限的优化问题,这样我们就有一个由 "输出文本损失 "和 "奖励分数 "项组成的综合损失,我们与SL共同优化?当然,如果我们想让模型产生正确的问答对,上述的约束性优化是可行的。但是ChatGPT应该有连贯的对话,所以我们也需要累积奖励。
原因3:交叉熵损失函数无法有效检测文本中细微的差别
回到上面提到的有监督学习的符号级损失:在有监督学习中,我们通过交叉熵优化损失。如果我们改变个别的词(tokens),由于总和规则,这只会对一个文本段落的整体损失产生小的影响。但是,否定一个词可以完全改变文本的含义,所以交叉熵并不是这种问题的最佳损失函数。
原因4:强化学习比有监督学习更能考虑整体影响
其实,用有监督学习来训练大语言模型模型也不是不可能。事实上,在 "Learning to Summarize from Human Feedback (2022)"的论文中已经做到了这一点。只是与有人类反馈的RL相比,它的表现并不那么好。根据经验,RLHF的表现往往比SL好。SL使用的是符号级的损失(可以对文本段落进行求和或求平均),RL则是将整个文本段落作为一个整体来考虑。
原因5:有监督学习其实和强化学习都很重要
其实,并不是SL或RLHF二选一的关心,InstructGPT和ChatGPT都使用了这两种东西!这是很重要的,即有监督的学习和基于人类反馈的强化学习的组合才是关键。ChatGPT/InstructGPT论文(https://arxiv.org/abs/2203.02155 )描述了首先通过SL调整模型,然后通过RL进一步更新。
如下图所示: