
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



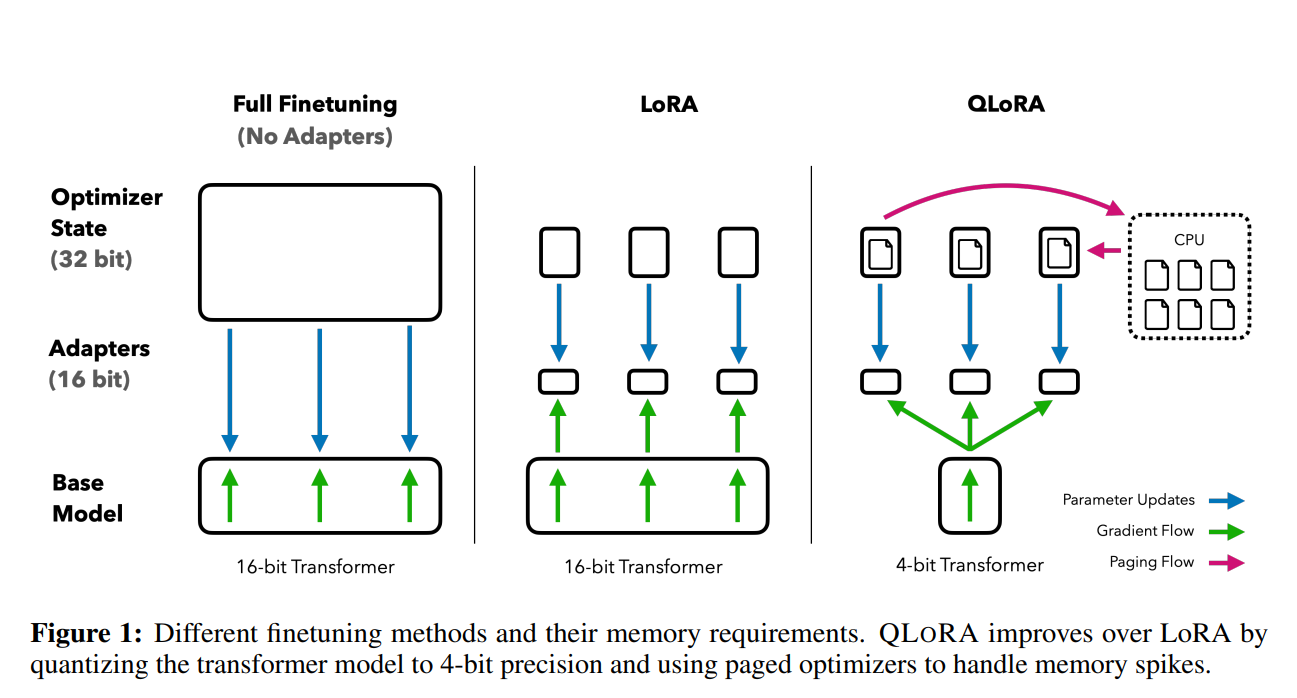
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
今日推荐
可能是过去三十年来编程语言最大的革新:新的面向AI的编程语言Mojo发布~
OpenAI发布企业使用的ChatGPT:没有限制且更快的GPT-4、数据隔离、基于GPT-4的高级数据分析功能,但是暂不支持私有化部署
流浪地球2的数字生命计划可能快实现了!HeyGen即将发布下一代AI真人视频生成技术,效果逼真到无法几乎分辨!
Arena Hard:LM-SYS推出的更难更有区分度的大模型评测基准
Java爬虫入门简介(三) —— Jsoup解析HTML页面
Python报Memory Error或者是numpy报ValueError: array is too big; `arr.size * arr.dtype.itemsize` 的解决方法
Anthropic发布Claude3.5-Sonnet模型,超过Claude3系列所有模型的能力,并且支持多模态!
三年后OpenAI再次发布自动语音识别和语音合成大模型(替换Whisper系列):不开源,仅提供API,英文错字率已经下降到2.46%