
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



在OpenAI的首次开发者大会上,OpenAI发布了诸多的新功能。但是,ChatGPT目前一个非常难用的功能就是历史记录查询。当前,ChatGPT的历史对话是ChatGPT自动取名标题之后放在左侧,而新截图显示,ChatGPT可能即将上线一个新功能来改进这个管理。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。

StabilityAI是当前最流行的开源文本生成图像大模型Stable Diffusion背后的公司。这家公司在文本生成图片和文本生成视频方面开源了诸多的大模型。其中,Stable Diffusion是目前使用人数最多的开源文本生成图像大模型。就在刚才,StabilityAI又发布了一个全新的实时的文本生成图像大模型Stable Diffusion XL Turbo,这个最新的模型在A100上生成一张图片只需要0.207秒!
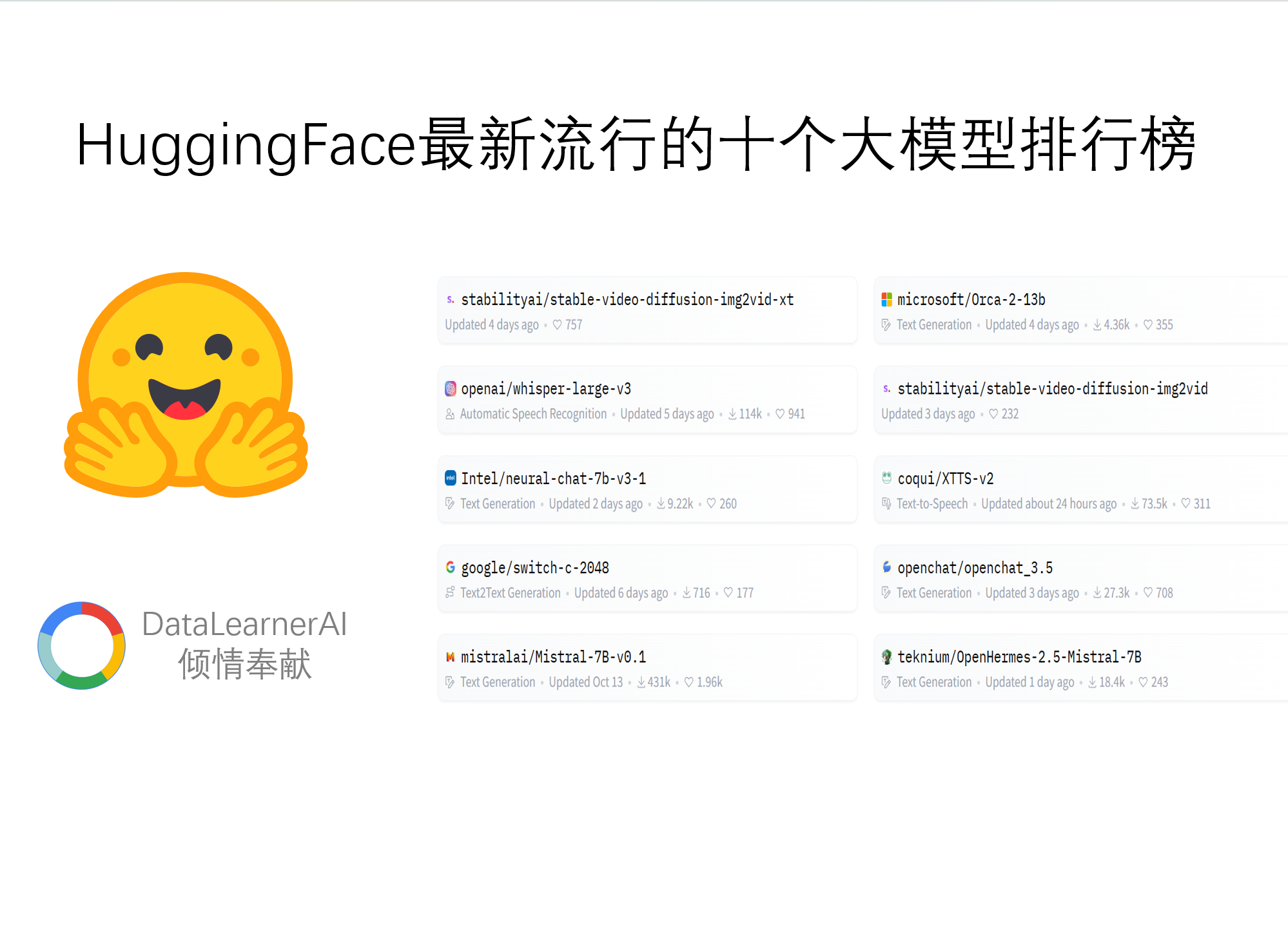
在本周,HuggingFace最流行的十个大模型多模态模型占了4个,包括StabilityAI最新开源的文本生成视频大模型Stable Video Diffusion、Coqui最新的语音合成大模型XTTS第二代等都吸引了大量的关注多。而大语言模型中,谷歌开源了2022年就已经发布的Switch大模型,该模型号称参数可以达到上万亿,也是十分有意思。

在深度学习和计算机视觉的发展历程中,视频生成技术一直是一个极具挑战和创新的领域。而发布了一系列开源领域最强图像生成模型Stable Diffusion系列模型背后的企业StabilityAI最近又开源了一个的文本生成视频大模型Stable Video Diffusion模型,这个模型可以生成最多20帧的视频。测试效果,这个模型普通版本与runway差不多,20帧版本则超过了runway!

上周五,OpenAI董事会突然把Sam开除的事件已经结束,闹了好几天之后Sam回归,董事会改组。而这件事的背后导火索有许多传闻,其中最重要的一个是OpenAI可能在最近有一项重大的技术突破,被认为是Sam和董事会分歧的重要原因。而今天,国外的路透社独家消息提到OpenAI内部一个称为Q\*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。本文将根据目前的信息汇总介绍一下Q\*项目。

OpenAI的董事会上周五开除Sam Altman,同日其创始人Greg Brockman,这件事引起了轩然大波。周末各方消息显示投资人施压董事会,要求召回Sam。本来大家以为Sam重回OpenAI。但是最新消息,OpenAI找了新的CEO,Sam与Greg等人加入微软成立新的团队。
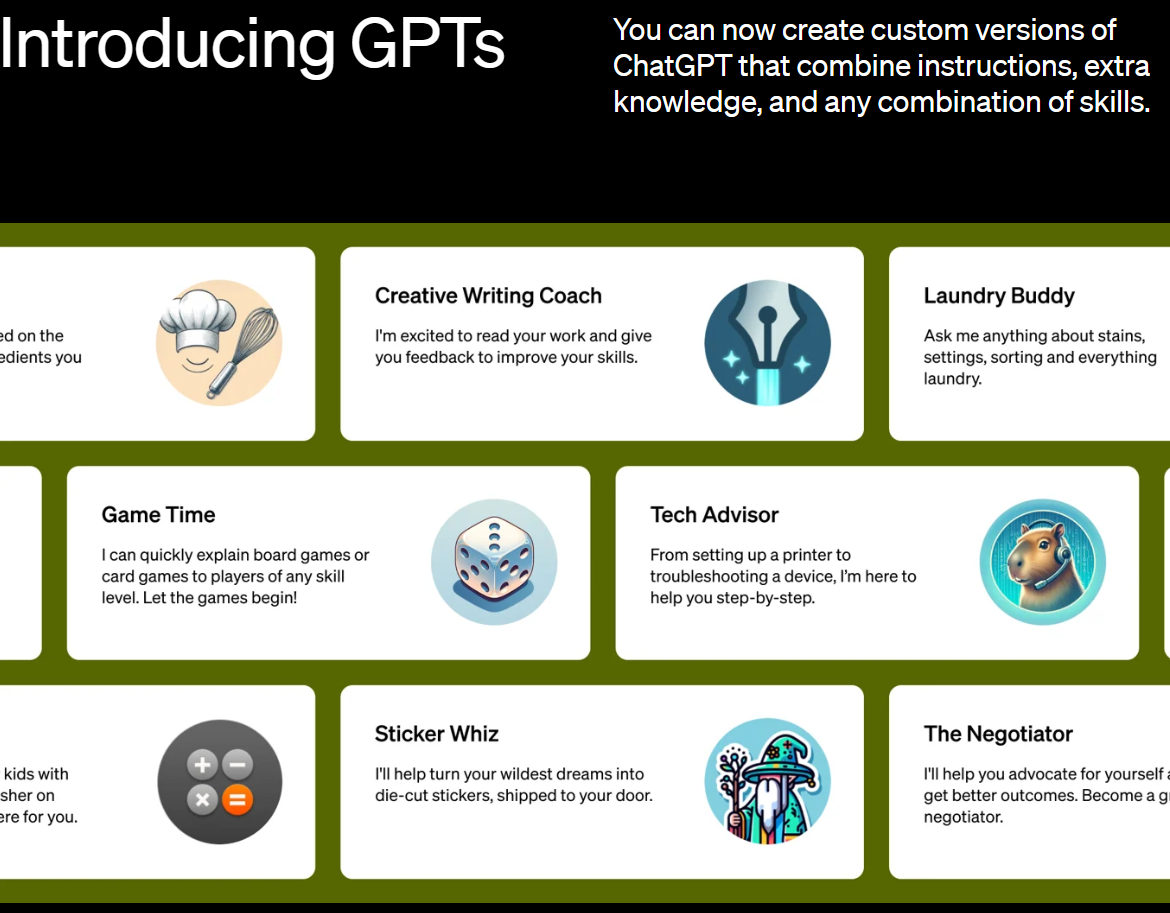
GPTs是OpenAI在其开发者日发布的一项最新的个性化GPT功能。所有人可以基于现有的GPT-4,配合网络流量、文件访问等功能,上传自己的数据,对接自己的接口来构建个性化的GPT,并对外提供服务。那么,2周后的今天GPTs的发展怎么样?有哪些受欢迎的GPTs被大量使用?本文结合各方数据介绍一下当前GPTs的情况。
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。
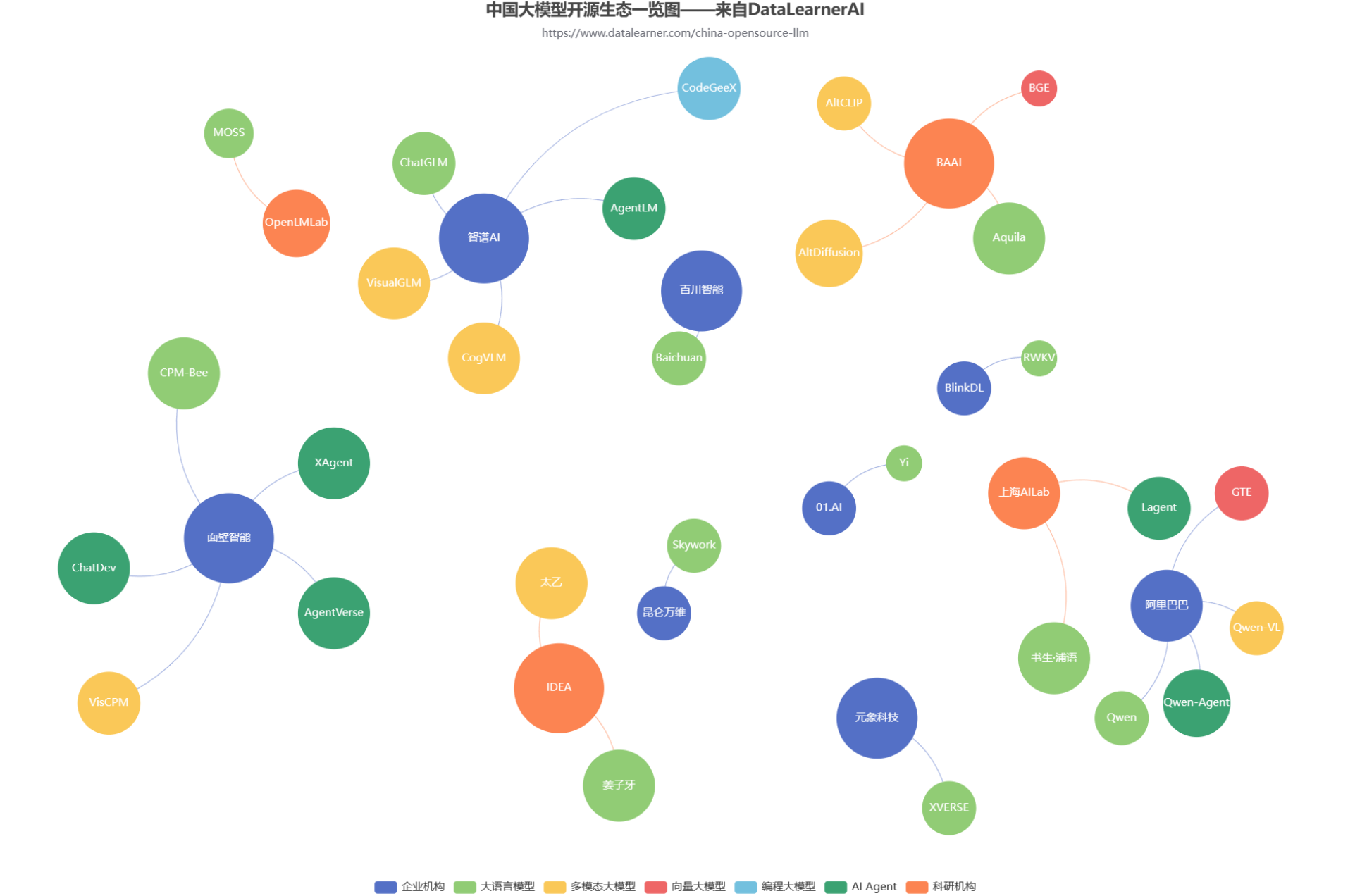
随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。但是,众多的大模型产品眼花缭乱。为了方便大家追踪国产开源大模型的发展情况,DataLearnerAI发布了中国国产大模型生态系统全景统计(地址:https://www.datalearner.com/china-opensource-llm ),本文也将根据这个统计结果简单分析当前国产开源大模型的生态发展情况。

GPT-4 Turbo是OpenAI最新发布的号称性能超过当前GPT-4的模型。在新版本的ChatGPT中已经可以使用。而接口也在开放。除了速度和质量外,GPT-4 Turbo最吸引人的是支持128K超长上下文输入。但是,实际测试中GPT-4 Turbo对于超过73K tokens文档的理解能力急速下降。

零一万物(01.AI)是由李开复在2023年3月份创办的一家大模型创业企业,并在2023年6月份正式开始运营。在2023年11月6日,零一万物开源了4个大语言模型,包括Yi-6B、Yi-6B-200K、Yi-34B、Yi-34B-200k。模型在MMLU的评分上登顶,最高支持200K超长上下文输入,获得了社区的广泛关注。
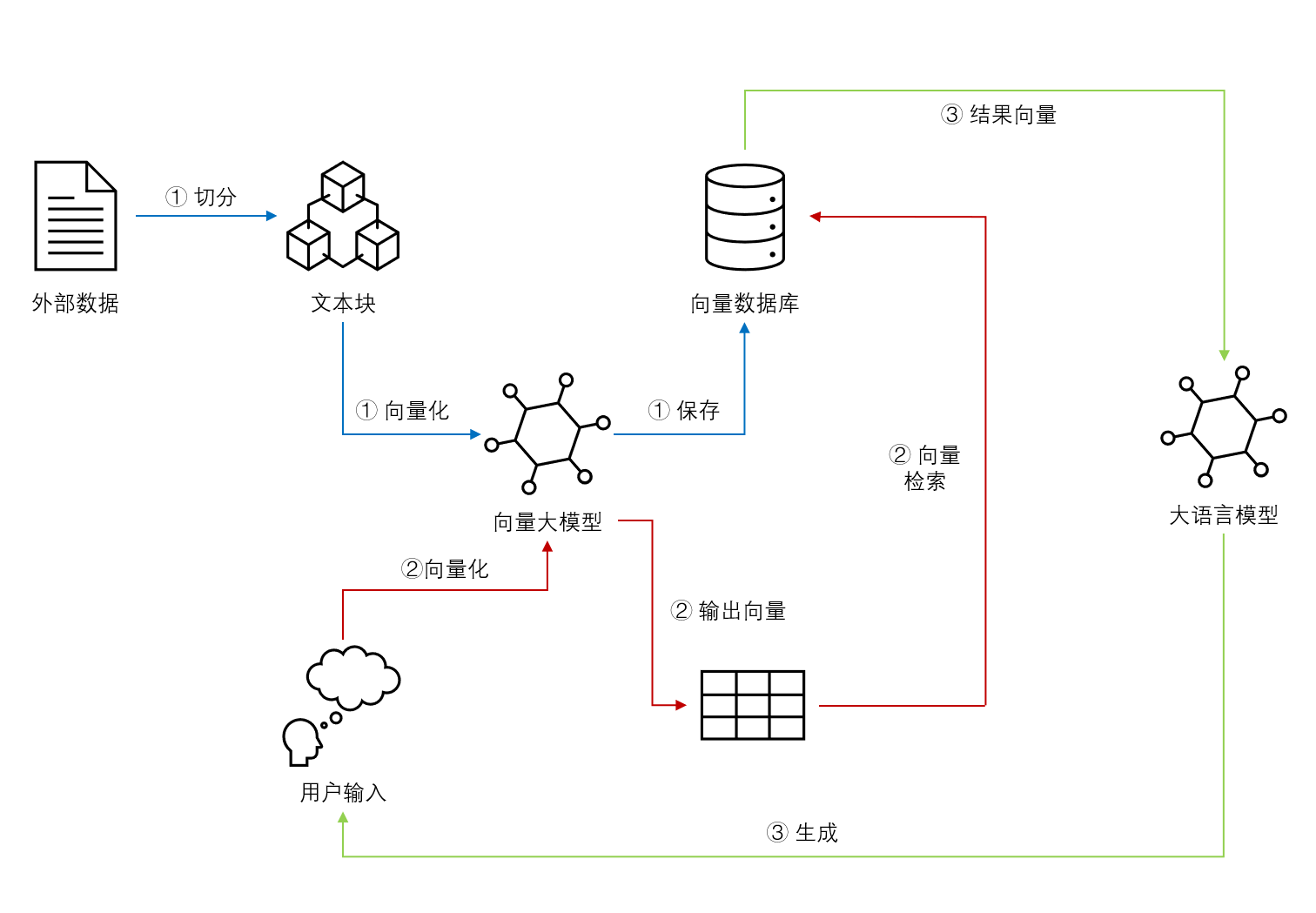
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。
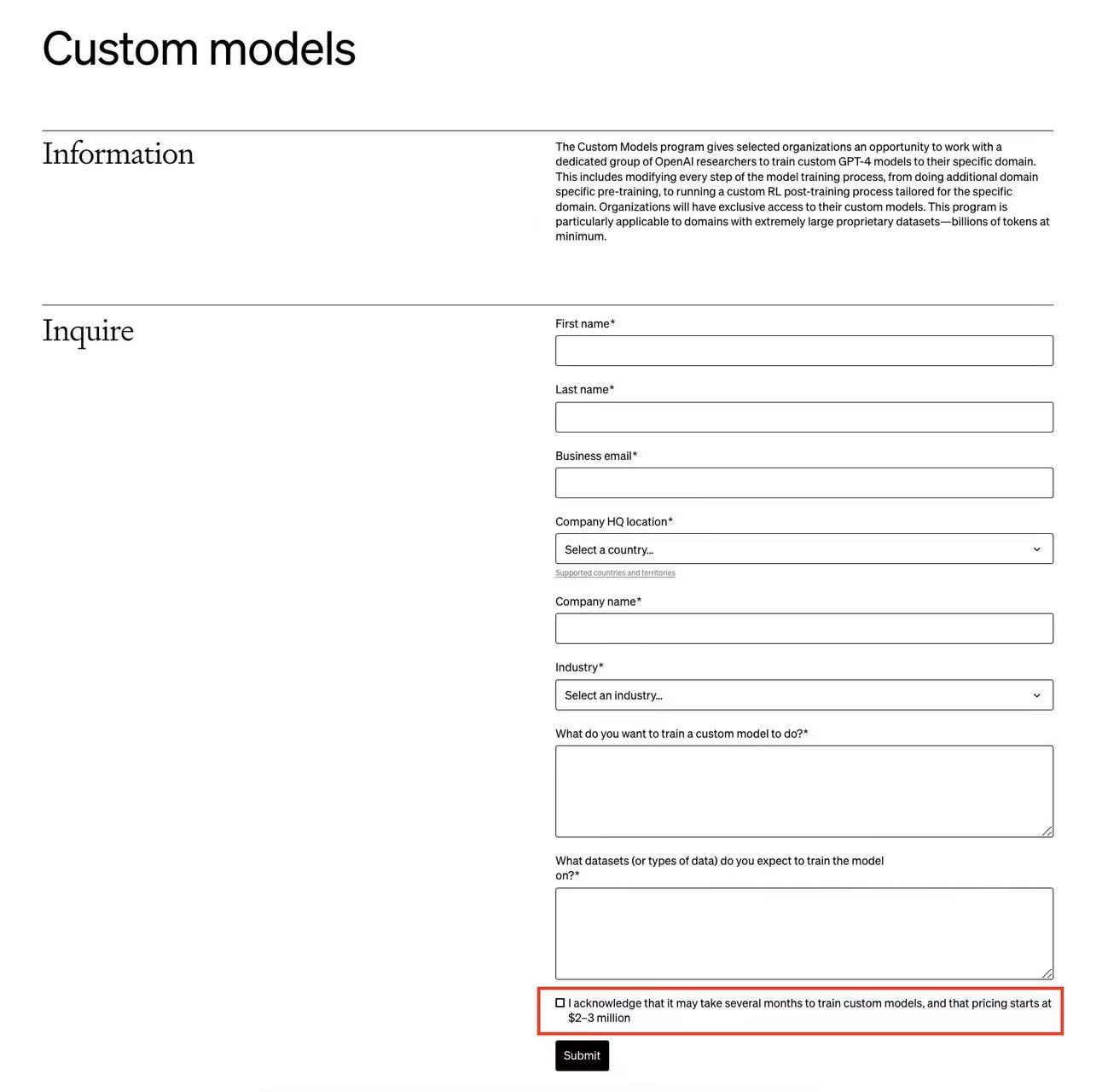
OpenAI的开发者日发布了许多更新。其中,普通用户可以微调GPT-4是非常值得期待的功能之一。但是,OpenAI还有一个针对企业的定制化GPT-4的训练服务,称为Custom Models。而这项为企业单独定制的GPT-4训练服务最新截图显示,需要几个月来训练模型,而且费用是200-300万美元起步!

OpenAI在发布了多模态的GPT-4V(GPT-4 with Vision)的接口,可以实现图像理解的功能(`Image-to-Text`)。这是OpenAI的第一个多模态接口,在以前的接口中,OpenAI都是文本大模型,相关的费用计算都是按照输入输出的tokens计算,虽然与一个单词多少钱有一点差异,但是也算直观。而GPT-4V是一个图像理解的接口,这里的费用计算不像文本的tokens那么直观,那么这个接口的费用计算逻辑是什么?这个计算逻辑透露了什么样的模型架构信息?本文将介绍这个问题。