
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



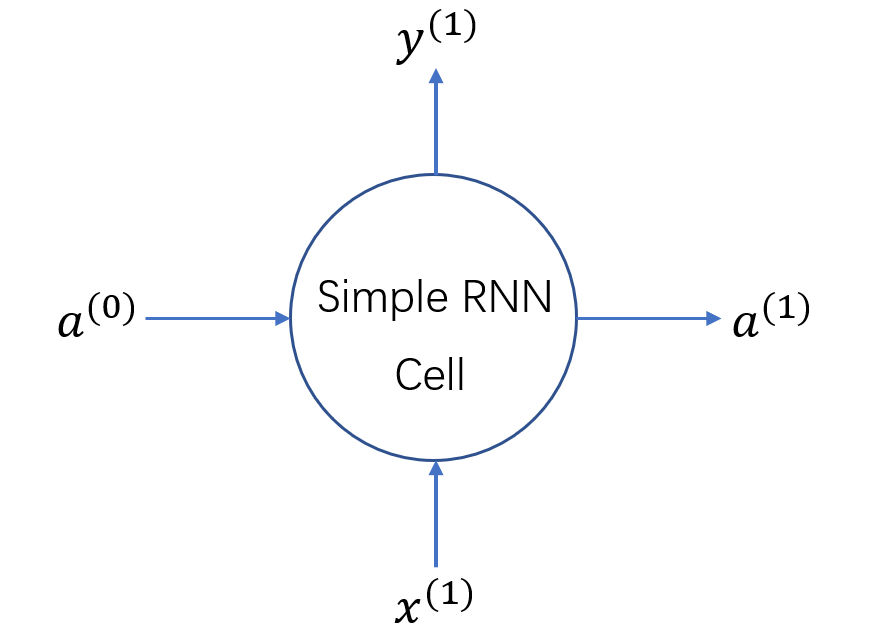
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。

网站启用HTTPS必须制作证书,而证书的制作需要定期更新。这里介绍了Certbot证书自动生成工具和自动更新的方法。并描述了Tomcat如何配置pem证书。
在使用Dask进行两个dataframe的concatenate操作的时候抛出ValueError,本文记录这个错误以及解决方案。
在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。
使用pandas的DataFrame和dask的DataFrame保存数据到csv文件时候会出现两个换行符的情况。本文描述如何解决。
Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
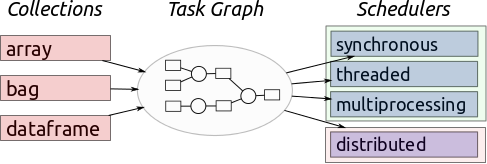
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。
今日推荐
OpenRouterAI:一个提供目前最优秀大模型API的网站,支持GPT-4 32k和Claude v2接口!
大语言模型的技术总结系列一:RNN与Transformer架构的区别以及为什么Transformer更好
重磅!MLPerf™训练1.1成绩发布!AI训练正在超越摩尔定律!
OpenAI官方教程:如何使用基于embeddings检索来解决GPT无法处理长文本和最新数据的问题
SlimPajama:CerebrasAI开源最新可商用的高质量大语言模型训练数据集,含6270亿个tokens!
重磅数据集公布!LAION-400-Million Open Dataset免费的4亿条图像-文本对数据( LAION-400M:English (image, text) pairs)