
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。
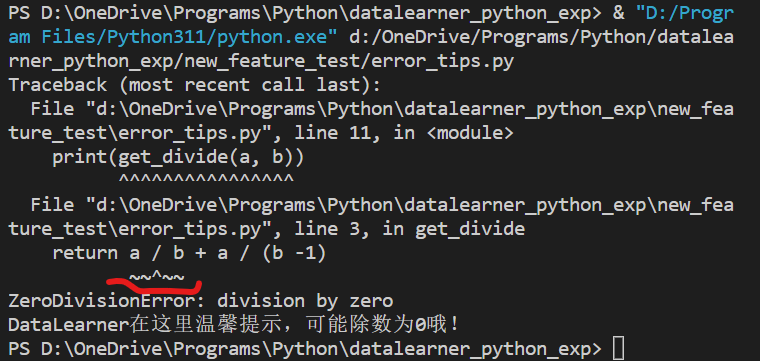
上个月Python的3.11版本发布了第一个beta版本,3.11带来了很多非常棒的新特性,例如错误提示更加具体,可以定位到具体代码位置等,十分友好,建议大家关注。这里简单为大家介绍一下。

检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。

Aquila-7B是北京人工智能研究院(BAAI)开源的一个可商用大语言模型。因为其良好的推理效果和友好的商用协议,使用的人较多。今天,BAAI再次开源2个基于Aquila-7B微调的编程大模型:AquilaCode-7B-multi和AquilaCode-7B-py。

大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。
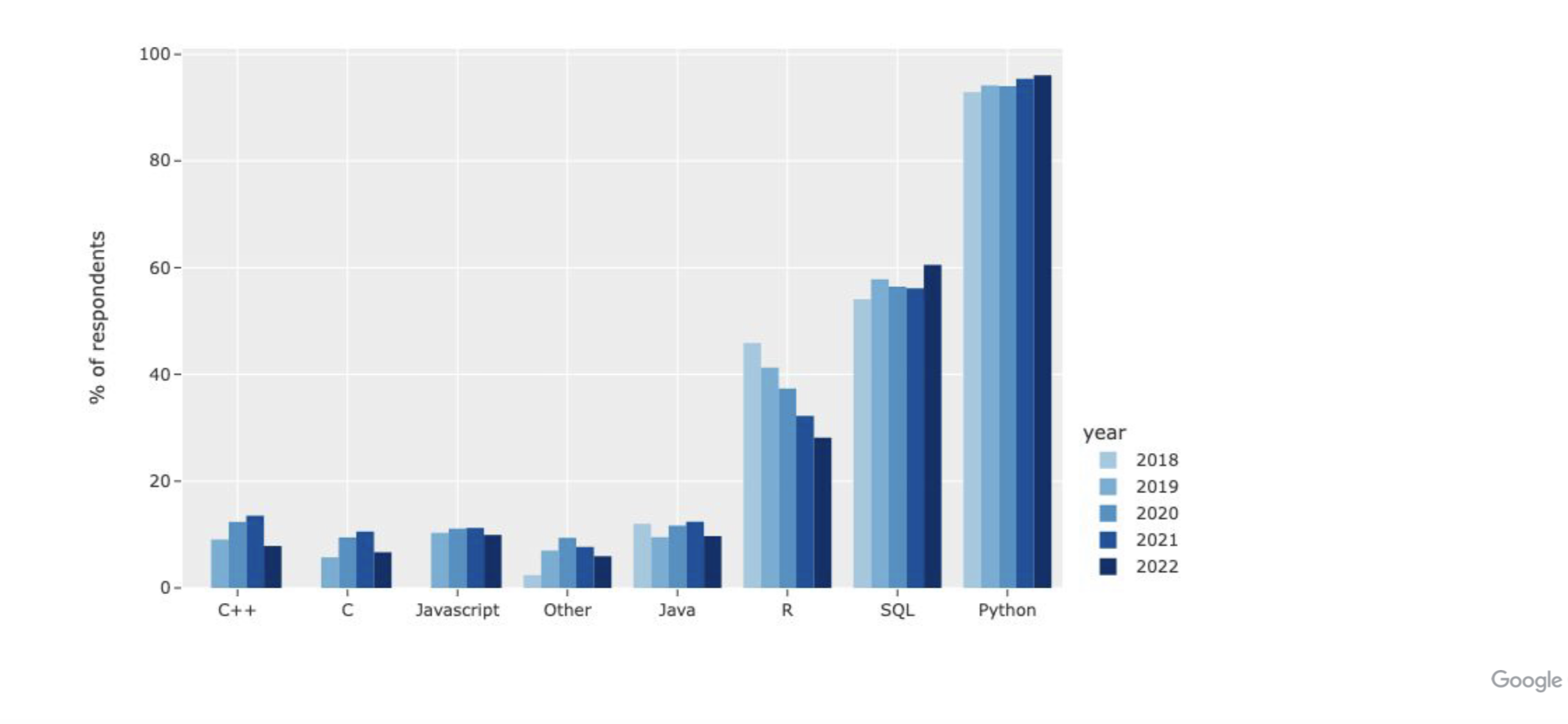
kaggle是各类机器学习竞赛的著名平台,上面聚集了大量的机器学习比赛和数据集,也有大量的数据处理相关专业人员。每年官方都会向平台用户发放问卷,调查数据科学家的工具使用和平台采用情况。今年的调查结果也在两天前发出,有很多有意思的结论。
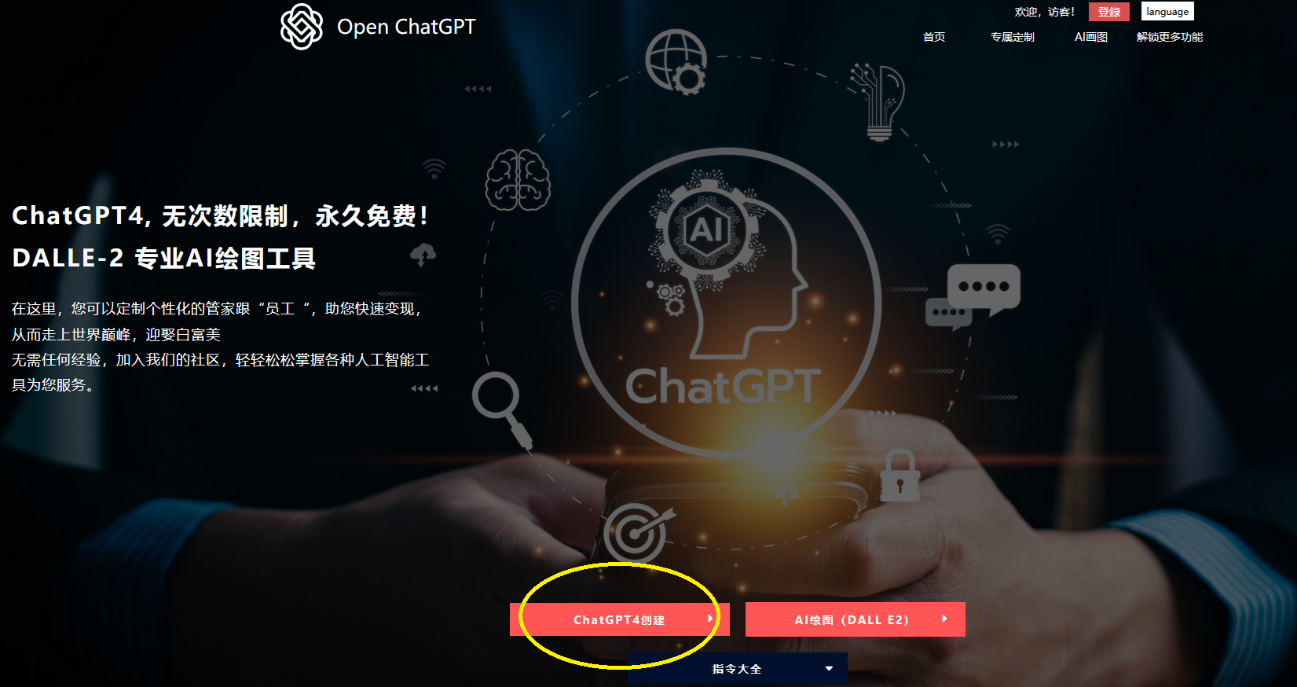
恰巧,我最近发现了一个网站——Open ChatGPT,网址是 https://open-chat-gpt.com/cn。 简单来说,该网站调用 ChatGPT-4 (最新版) 的 API,让用户创建各种指定角色,服务于生活跟工作。不仅如此,还支持连ChatGPT官网都还没用上的AI画图功能。目前,相比其他网页各种限制使用次数的,这网站非常可贵在于可以无限次免费使用ChatGPT-4...

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
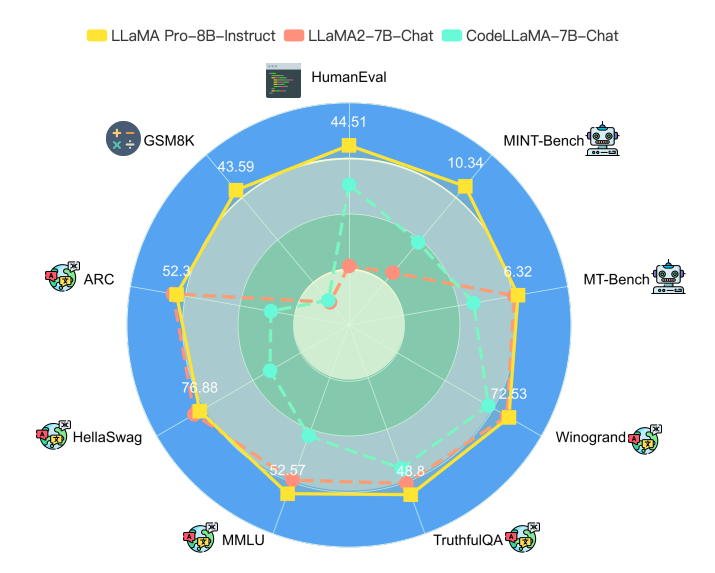
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。
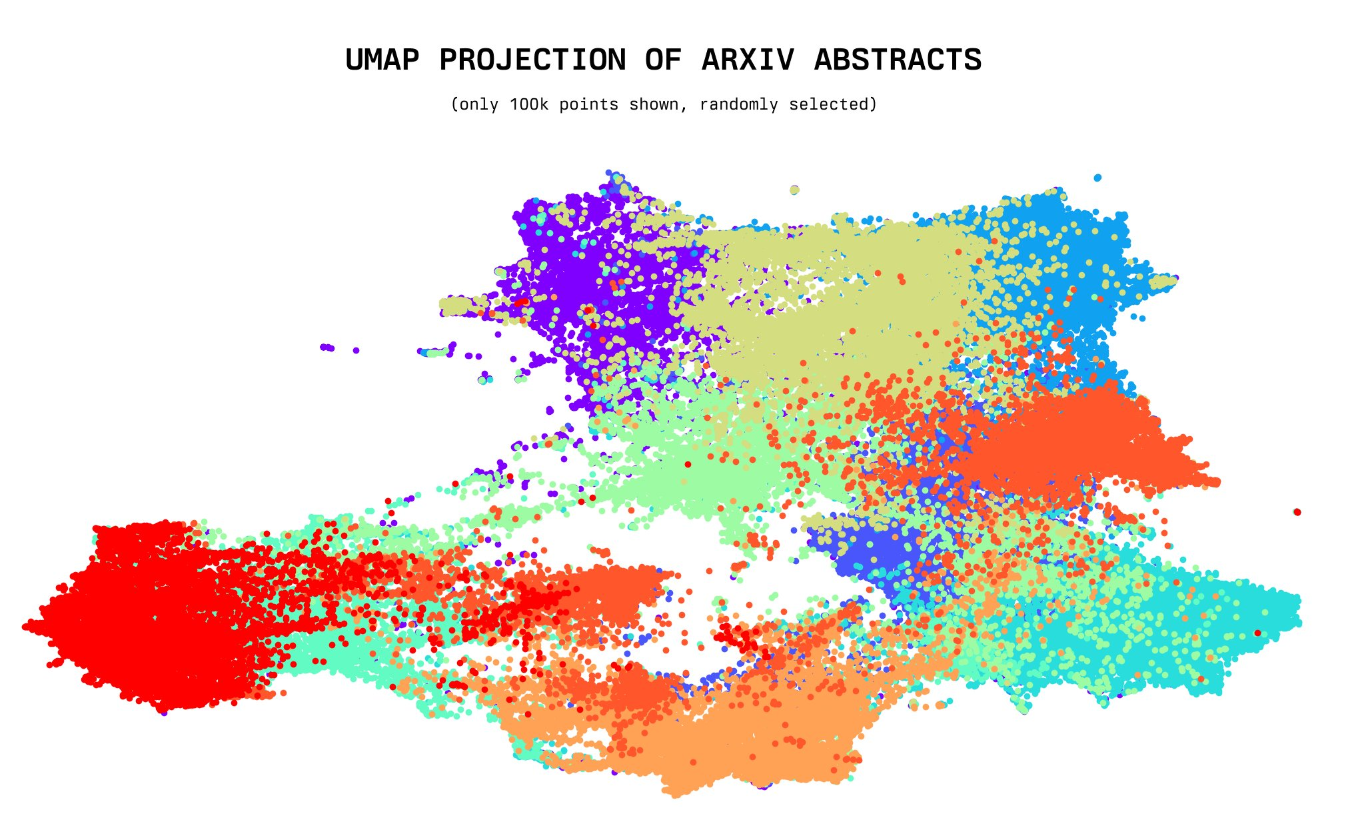
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果

XVERSE-13B是元象开源的一个大语言模型,发布一周后就登顶HuggingFace流行趋势榜。该模型最大的特点是支持多语言,其中文和英文水平都十分优异,在评测结果上超过了Baichuan-13B,与ChatGLM2-12B差不多,不过ChatGLM2-12B是收费模型,而XVERSE-13B是免费商用授权!

文本embedding是当前大模型应用中一个十分重要的角色。在长上下文支持、私有数据问答等方面有非常重要的应用。但是相比较开源领域快速发布的大模型节奏,开源的embedding模型和数据却非常少。今天,GPT4All宣布在其软件中增加embedding的支持,这是一个完全免费且可商用的产品,最重要的是可以在我们本地用CPU来做推理。
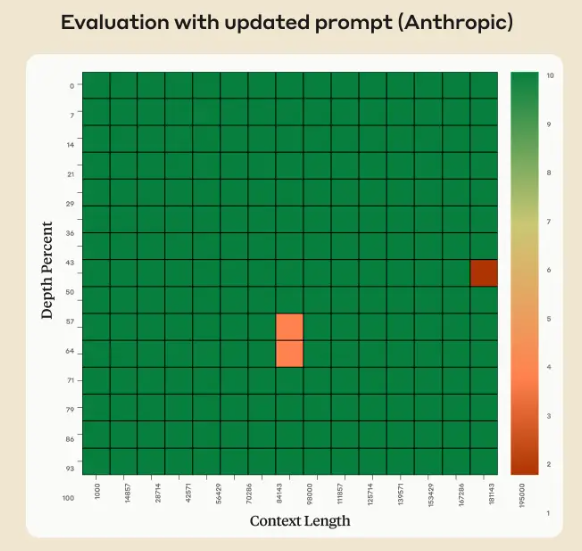
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。
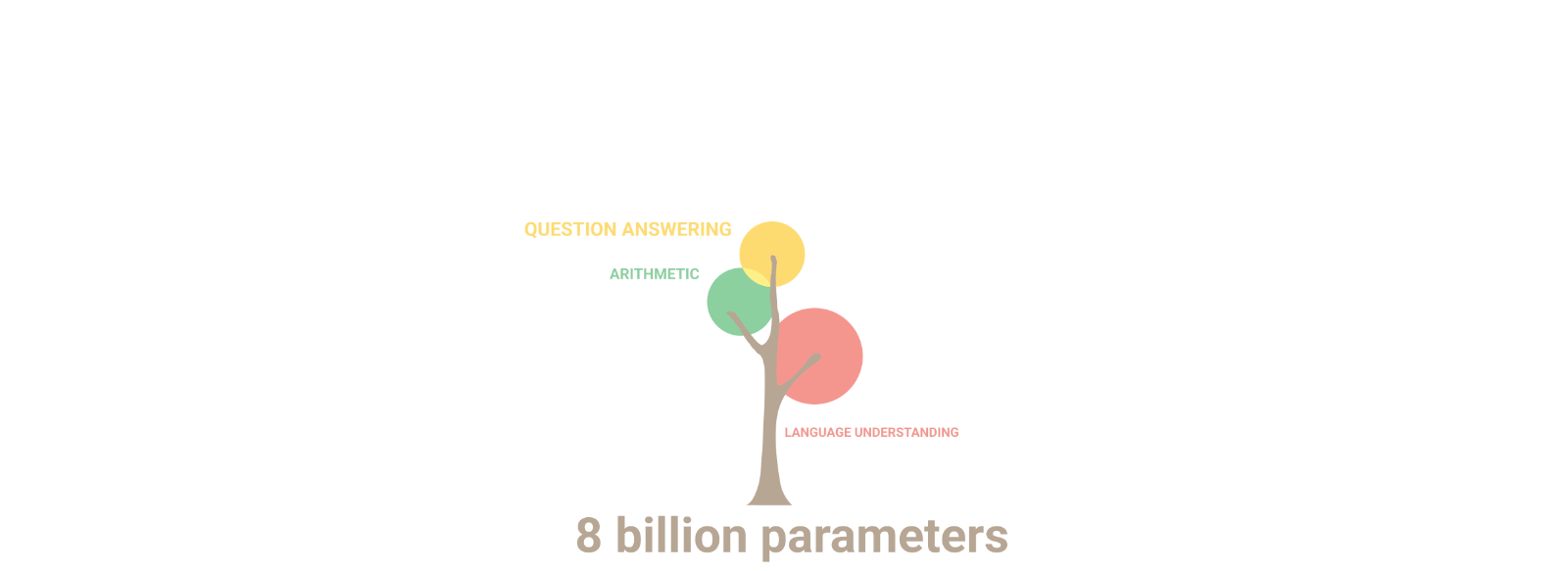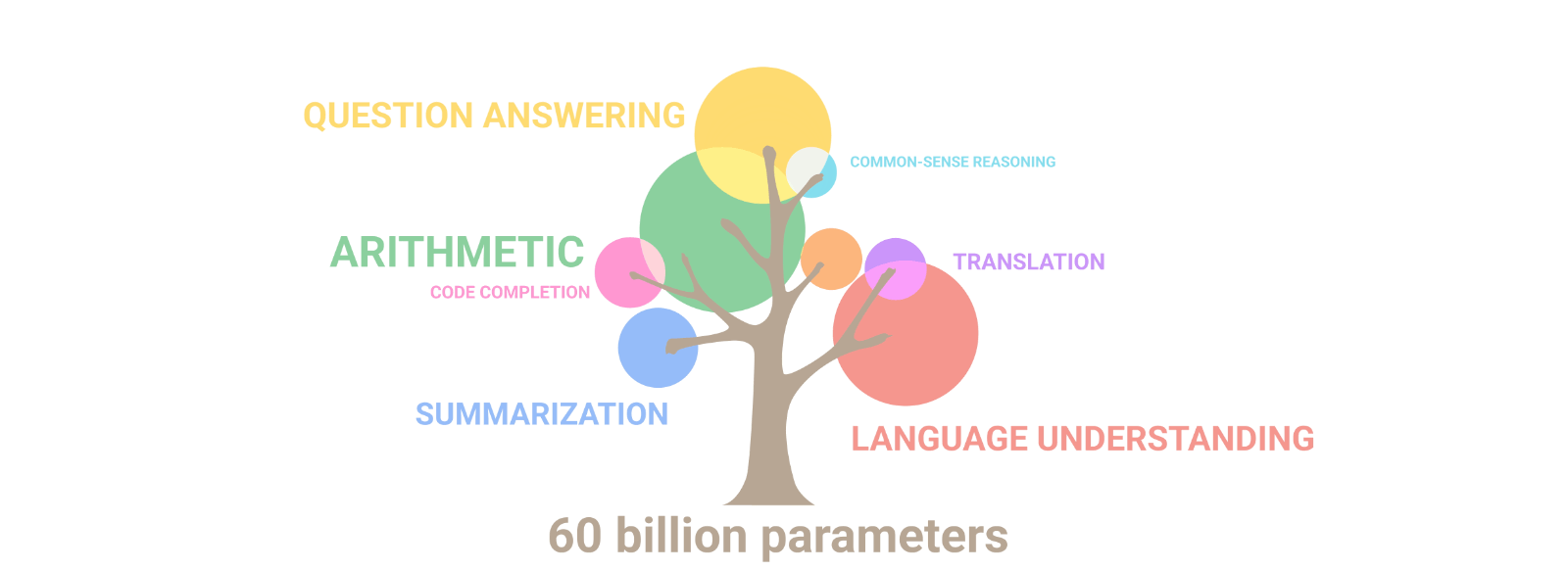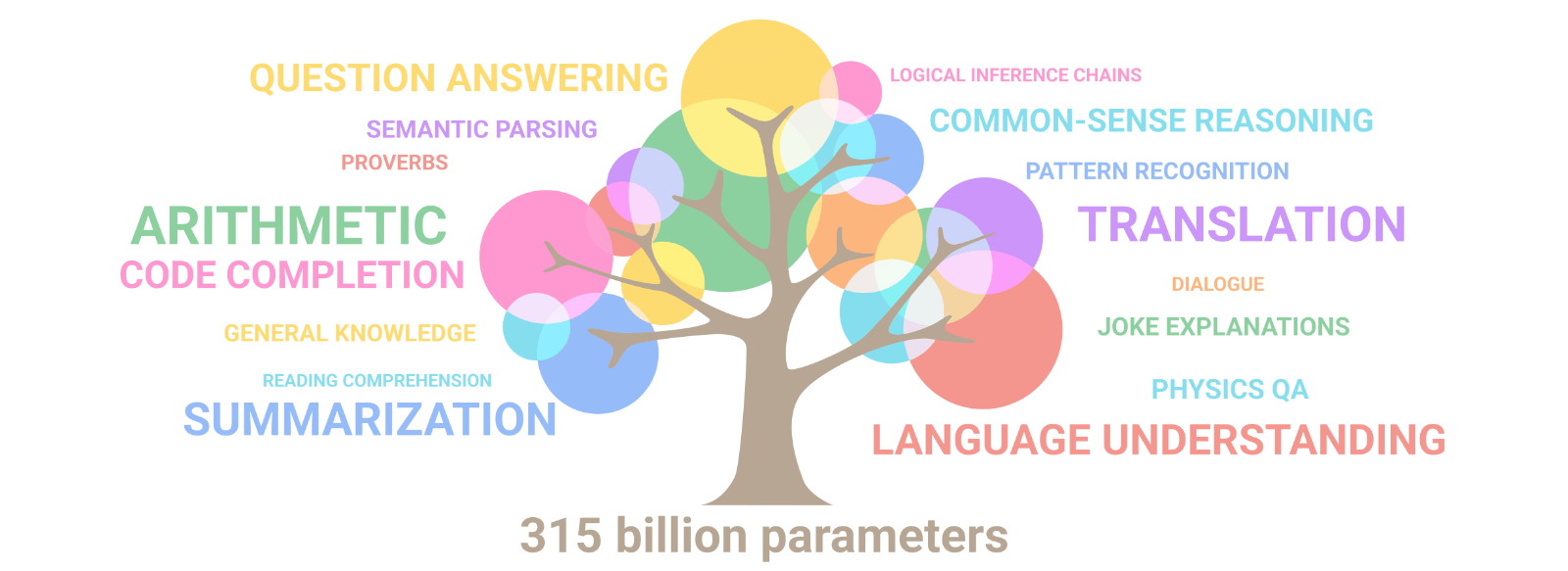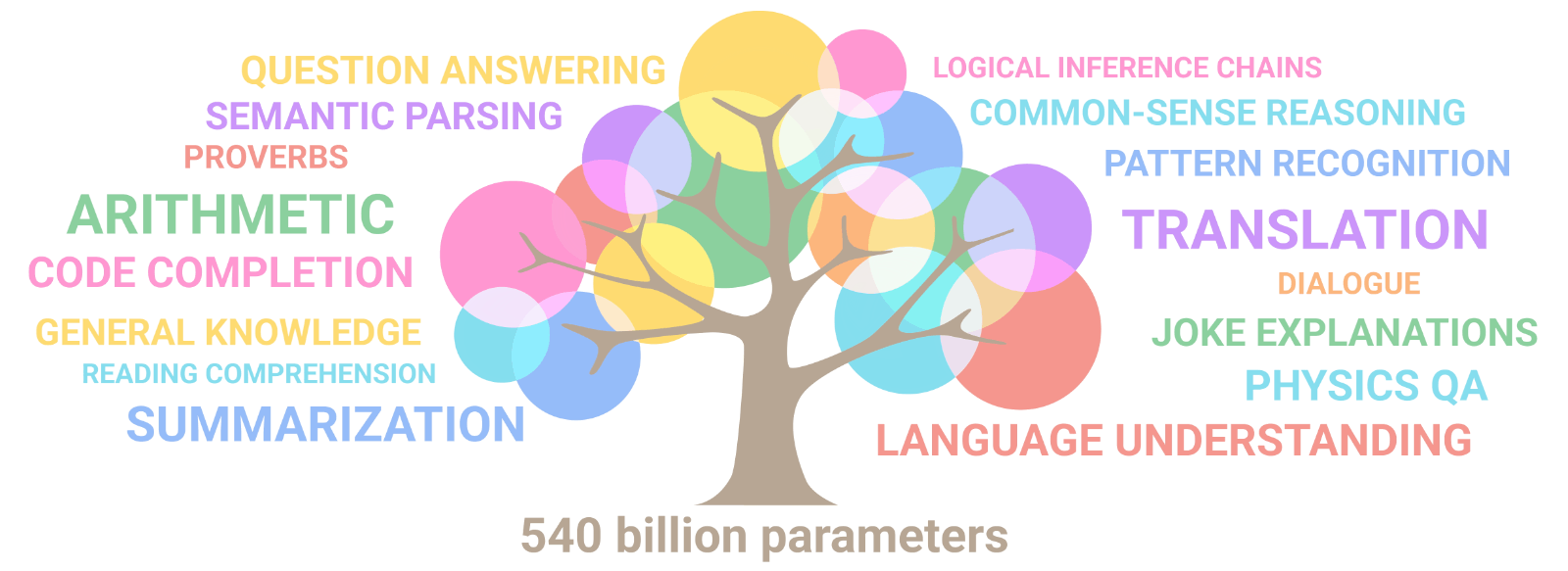
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
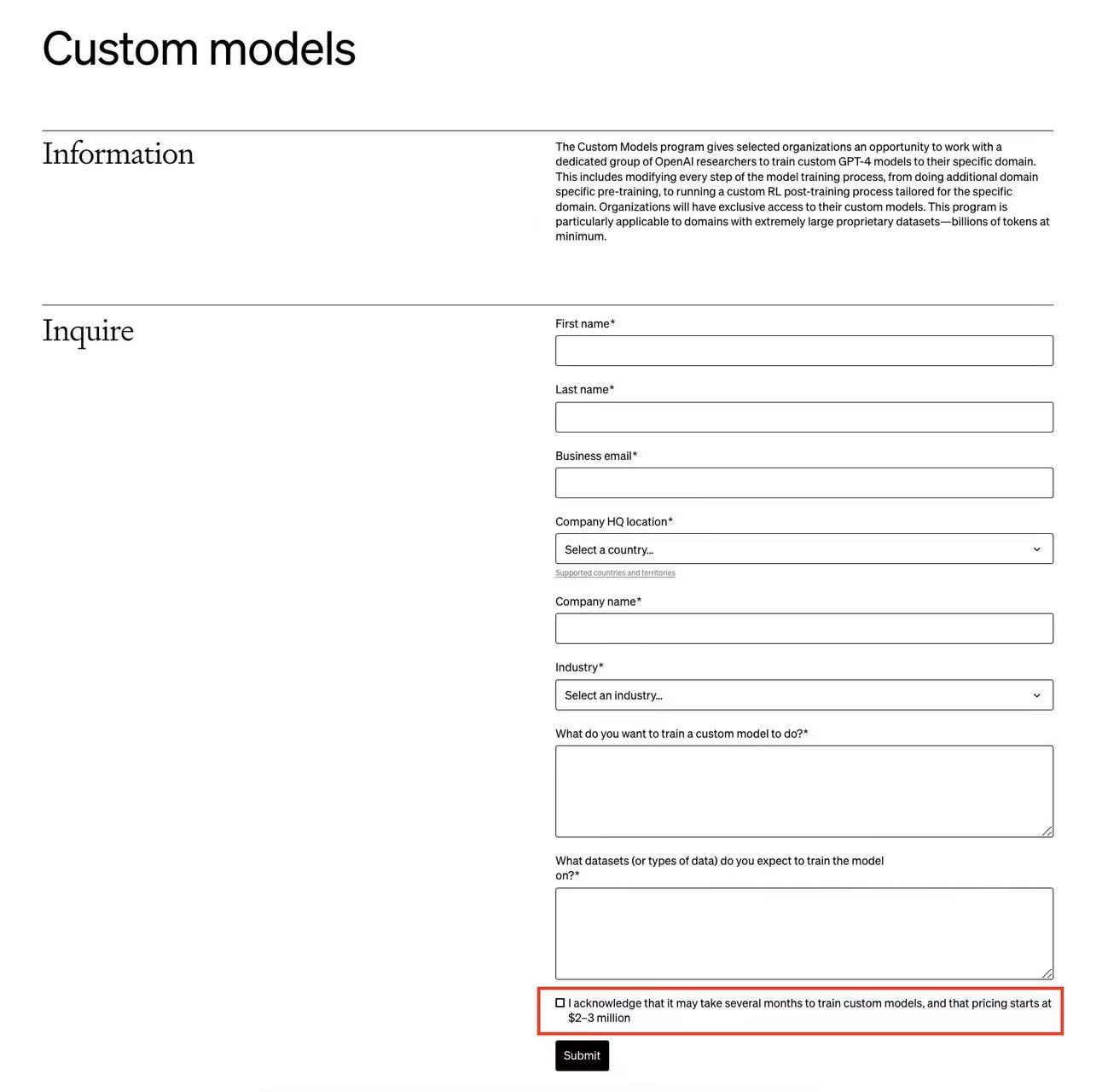
OpenAI的开发者日发布了许多更新。其中,普通用户可以微调GPT-4是非常值得期待的功能之一。但是,OpenAI还有一个针对企业的定制化GPT-4的训练服务,称为Custom Models。而这项为企业单独定制的GPT-4训练服务最新截图显示,需要几个月来训练模型,而且费用是200-300万美元起步!