
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



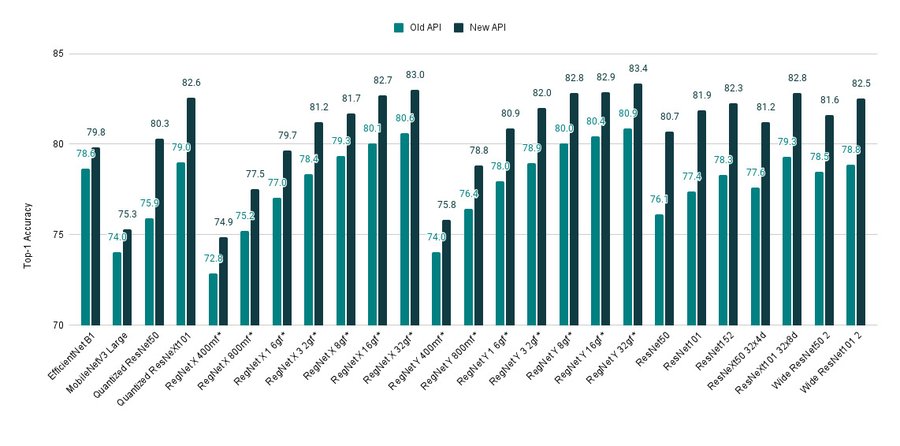
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。



九月份刚过去,GitHub上最火的AI研究排序出炉。这是根据9月份GitHub上创建的新的AI研究相关的项目排序,根据Star的数量来的。都是AI各大领域比较受欢迎和重要的项目。

吴恩达是人工智能领域非常著名的人物。2011年在谷歌创建的谷歌大脑项目,震惊了全世界。2014年他加入百度负责百度大脑计划,并于2017年离职。离职之后他创建了人工智能公司LandingAI,并担任首席执行官。昨天吴恩达宣布他新成立的这家公司已经募集到5,700万美金。本文主要简单介绍这家公司的业务。

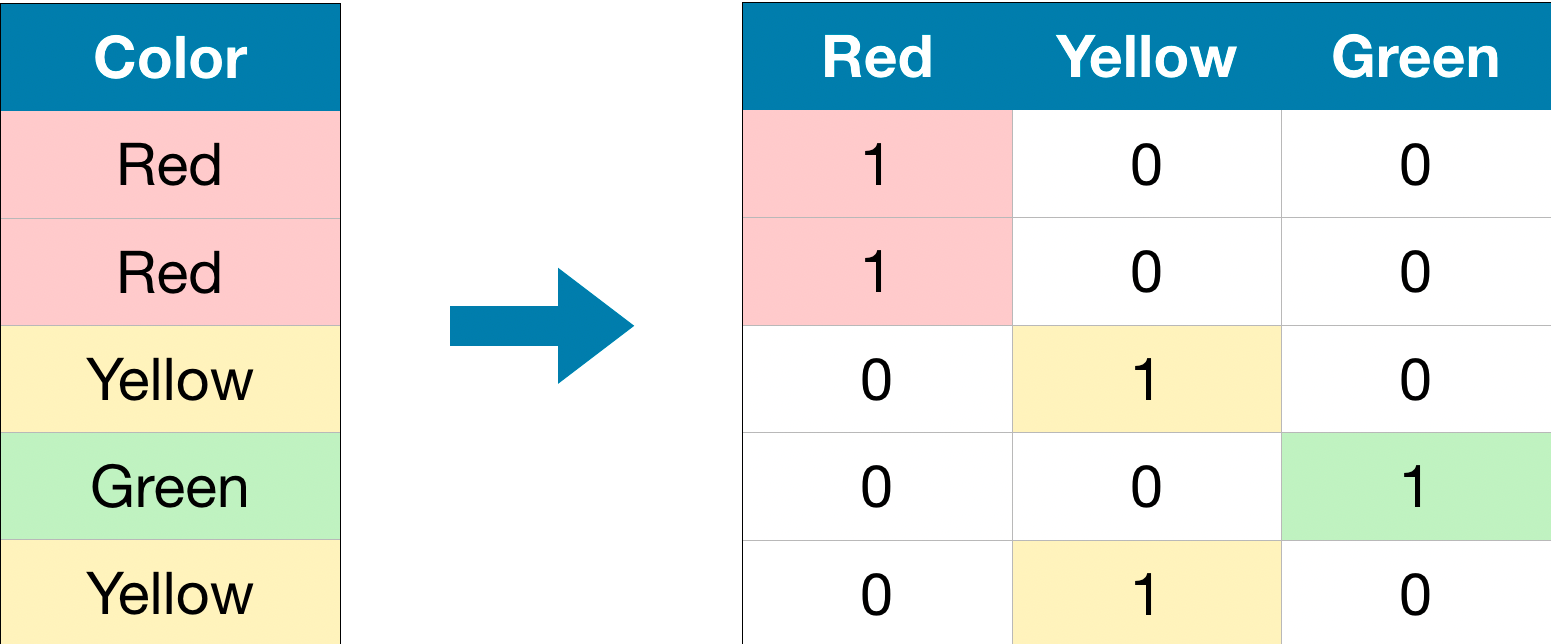
对于分类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。

MistralAI是一家法国的大模型初创企业,其2023年9月份发布的Mistral-7B模型声称是70亿参数规模模型中最强大的模型,并且由于其商用友好的开源协议,吸引了很多的关注。在昨晚,MistralAI突然在推特上公布了一个磁力下载链接,而下载之后大家发现这是一个基于混合专家的大模型这是由8个70亿参数规模专家网络组成的混合模型(Mixture of Experts,MoE,混合专家网络)。

就在儿童节前一天,Hugging Face发布了一个最新的深度学习模型评估库Evaluate。对于机器学习模型而言,评估是最重要的一个方面。但是Hugging Face认为当前模型评估方面非常分散且没有很好的文档。导致评估十分困难。因此,Hugging Face发布了这样一个Python的库,用以简化大家评估的步骤与时间。
今日推荐
Dask concat throws ValueError: Shape of passed values is (xxx, xxx), indices imply (xxx, xxx)
当前业界最优秀的8个编程大模型简介:从最早的DeepMind的AlphaCode到最新的StarCoder全解析~
重磅!Meta发布LLaMA2,最高700亿参数,在2万亿tokens上训练,各项得分远超第一代LLaMA~完全免费可商用!
如何用7.7亿参数的蒸馏模型超过5400亿的大语言模型——Google提出新的模型蒸馏方法:逐步蒸馏(Distilling step-by-step)详解
三年后OpenAI再次发布自动语音识别和语音合成大模型(替换Whisper系列):不开源,仅提供API,英文错字率已经下降到2.46%
可能是过去三十年来编程语言最大的革新:新的面向AI的编程语言Mojo发布~
Java爬虫入门简介(三) —— Jsoup解析HTML页面
UWMadison前统计学教授详解大模型训练最重要的方法RLHF,RLHF原理、LLaMA2的RLHF详解以及RLHF替代方法