
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




当谈及人工智能的巨大进步,大模型的崛起无疑是其中的一个重要里程碑。这些大模型,如GPT-3,已经展现出令人惊叹的语言生成和理解能力,但是为了让它们在特定任务上发挥最佳性能,大模型微调(Fine-tuning)是一种非常优秀的方法。微调是一种将预训练的大型模型进一步优化,以适应特定任务或领域的过程。但微调并不是很简单,今天吴恩达联合Lamini推出了全新的大模型微调短课《Finetuning Large Language Models》。


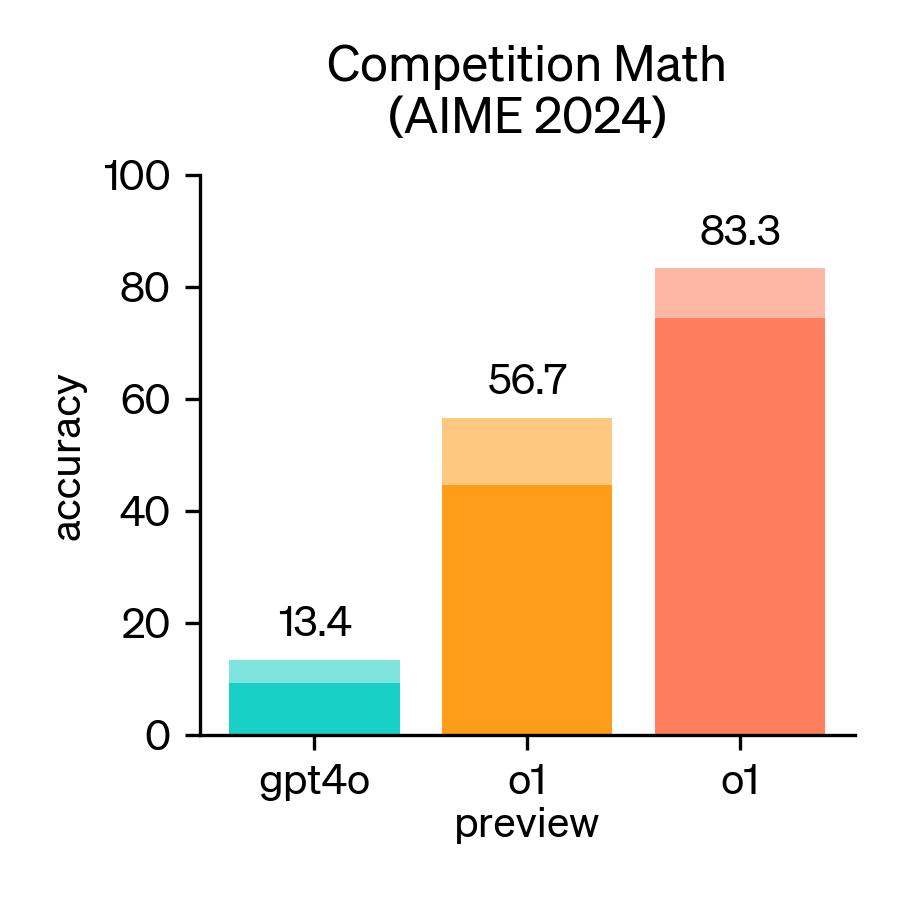
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。
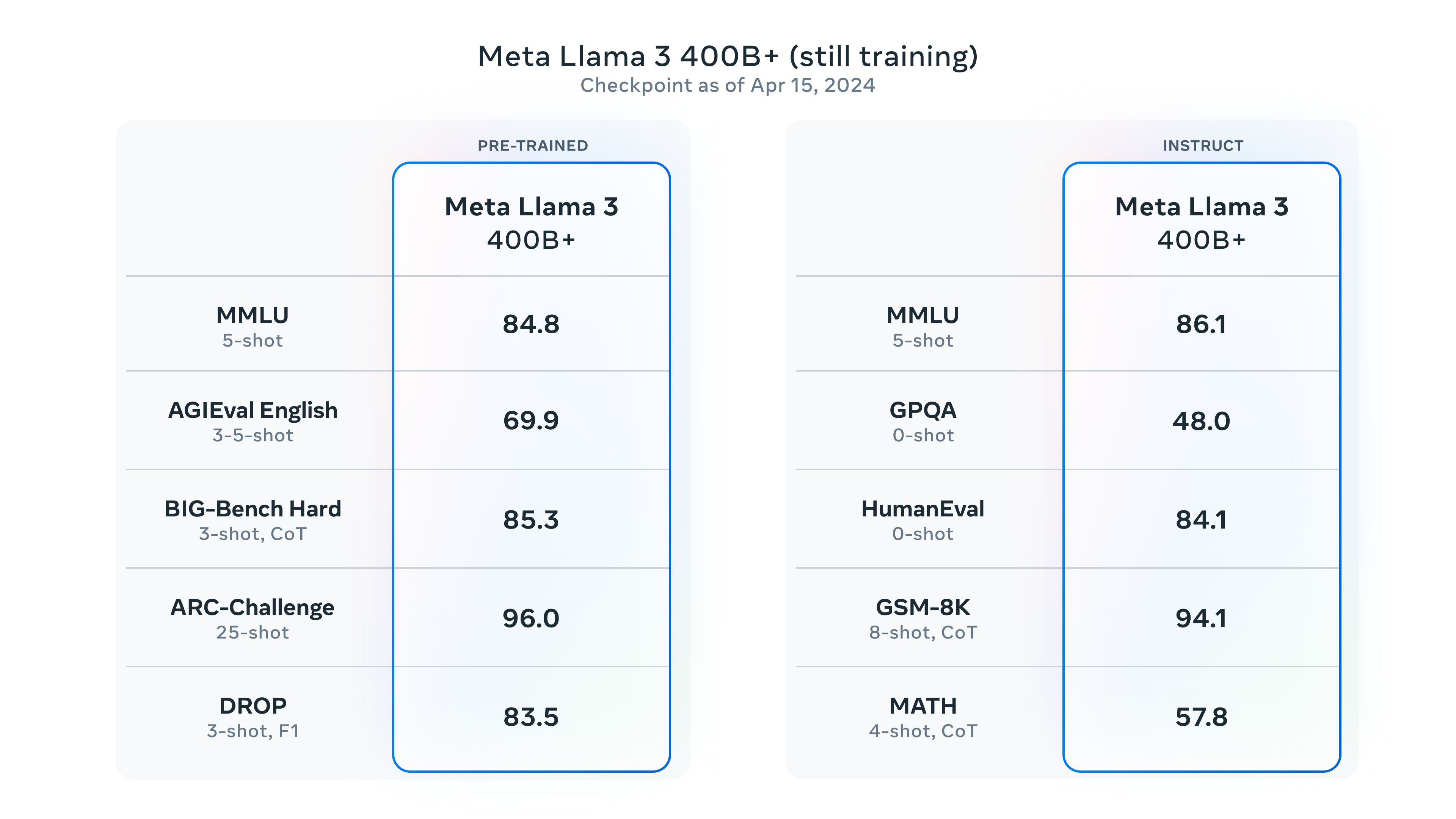
大语言模型开源领域最重要的一个模型就是MetaAI开源的Llama系列。当前,很多著名开源模型都是基于Llama系列进行预训练得到。就在刚才,MetaAI开源了第三代Llama3系列。官方透露的信息非常多,Llama3系列是目前为止最强的开源大语言模型,未来还有4000亿参数版本,支持多模态、超长上下文、多国语言!

Llama3是MetaAI开源的最新一代大语言模型。一发布就引起了全球AI大模型领域的广泛关注。这是MetaAI开源的第三代大语言模型,也是当前最强的开源模型。但相比较第一代和第二代的Llama模型,Llama3的升级之处有哪些?本文以图表的方式总结Llama3的升级之处。

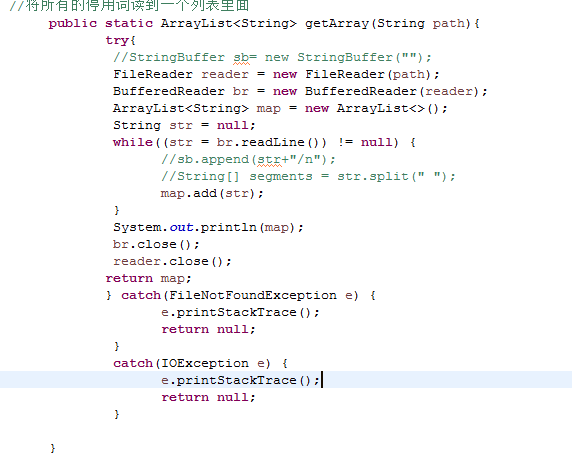
Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。
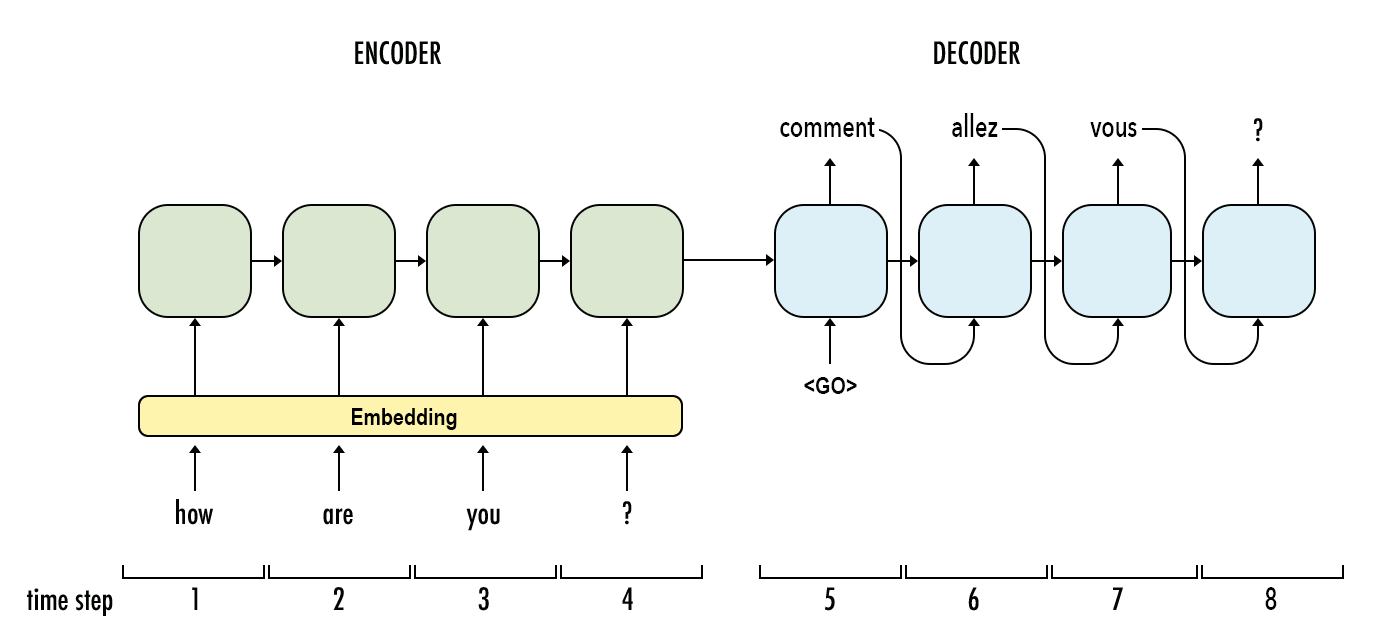
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。

机器学习相关的竞赛为大家学习使用算法提供了一个非常好的平台和机会。既能检验大家学习的算法的实际应用情况,也可以帮助我们学习到很多有用的技巧。很多竞赛也都产生了优秀的算法思想与经验。所以积极参加比赛是一种非常重要的学习方式。本文总结目前正在举办的比赛,各位可以根据自己的情况参与。