基于GPU的机器学习Python库——RAPIDS简介及其使用方法
随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。
然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。如果需要使用传统机器学习方法处理大规模的数据,这是非常值得使用的库。这里列举的只是少部分功能,它的强大远远超过你的想象。
目前,RAPIDS提供三个模块处理数据:cuDF相当于Pandas,cuML相当于scikit-learn,cuGraph则是处理图数据的(如PageRank算法)。由于它的兼容性很好,我们可以把RAPIDS与深度学习框架结合,用cuDF来利用GPU加速处理数据,然后使用PyTorch的深度学习模型处理任务。这也是可以的。所以,它非常灵活而且强大。
RAPIDS在Medium上也有博客,介绍了很多使用RAPIDS处理任务的技巧,如使用RAPIDS处理金融数据、使用cuDF加速协同过滤等。链接可以看参考一章。
一、为什么使用GPU
相比较CPU而言,GPU是由很多个简单的核组成的计算单元,它可以并行处理很多个任务(而CPU是有较少的复杂的核心组成,执行序列任务,只能同时执行很少的线程)。同时,GPU也比CPU有更好的带宽优化。而深度学习的基本算子则是矩阵乘法、向量加减和单值运算,它的特点是基本算子计算简单,但是对算力的需求较高。这正好与GPU的特点相结合。因此,GPU是目前加速深度学习最合适的硬件。
当然,这里不得不提到的是CUDA。CUDA是一个直接运行在GPU上的并行计算平台和编程模型。它是由Nvidia开发的,目的是为了充分利用Nvidia家的GPU计算能力。虽然基于GPU的并行计算平台和编程框架还有很多,如OpenCL等。但是,CUDA是目前应用最广泛的一个。
在CUDA之上,我们可以使用C、C++和Fortran编程语言,但这类语言的入门门槛较高,所以很多框架都在此之上提供了Python的用户编程入口。如TensorFlow,它的底层就是使用C语言编写,可以运行在CUDA上,因而可以充分利用GPU的并行计算能力。下图是TensorFlow的架构:
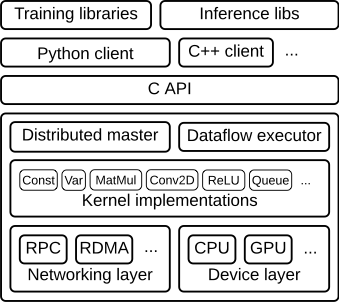
尽管如此,目前只有深度学习框架比较充分利用了GPU的加速功能。而很多传统机器学习算法大多数只能运行在CPU上,为了加速传统机器学习算法的运行速度,现在也有一些组织开始提供类似的框架了。而RAPIDS就是其中非常优秀的一个。
二、RAPIDS简介
RAPIDS是一个开源的库,它提供了端到端的数据科学和分析流程,以及一些传统的经典机器学习算法,可以完全运行在GPU上。它与一些主流的库完美兼容,如Pandas等,因此,入门不高。
与TensorFlow类似,RAPIDS的底层使用C语言编写,并利用NVIDIA的CUDA平台进行GPU的加速。在上层则提供Python的编程接口。RAPIDS架构如下:
RAPIDS起源于Apache Arrow和GoAi项目。目前包括了三个项目:
- cuDF
- cuML
- cuGraph
我们分别简单介绍一下。
2.1、cuDF
cuDF是基于Apache Arrow构造(这是一种基于内存的数据处理的跨语言平台),但是一种GPU的DataFrame库。可以用来加载、过滤、表征数据。cuDF提供了类似Pandas的编程接口。上手非常容易。
如下面的官方示例:
import cudf
tips_df = cudf.read_csv(file)
tips_df['tip_percentage'] = tips_df['tip']/tips_df['total_bill']*100
可以看到,它与Pandas的处理方式几乎一模一样。
2.2、cuML
cuML是RAPIDS项目中实现机器学习算法和数学计算的库。它可以让我们在GPU上运行传统的机器学习算法。为了方便大家使用,cuML还提供了与scikit-learn像似的算法接口。
与在CPU上运行相比,cuML运行在GPU上要快10-50倍。下图给出了RAPIDS数据处理到算法运算的速度对比:
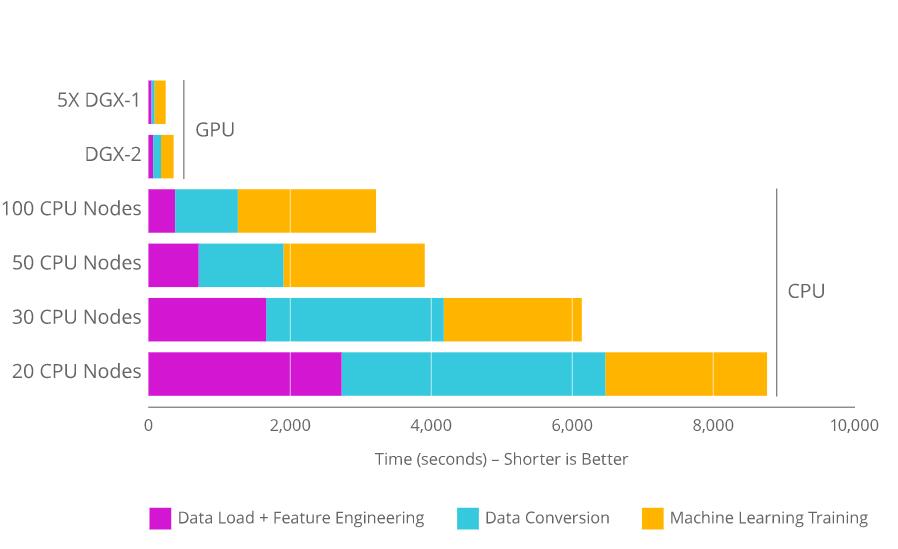
可以看到,RAPIDS的速度要比运行在CPU上的sklearn算法速度快很多。
2.3、cuGraph
cuGraph是一个用来处理图形数据的库,主要吹cuDF在GPU上的数据。它期望提供类似NetworkX接口的工具,可以帮助大家处理图挖掘问题。目前支持的算法包括PageRank、BSF等。
三、使用方法
RAPIDS依赖一些其他的基本库。因此,使用RAPIDS之前需要安装一些依赖的库。目前,RAPIDS需要的东西:
- GPU: NVIDIA Pascal及更好的GPU,兼容6.0以上版本
- OS:Ubuntu 16.04/18.04或者CentOS7(需要gcc5.4和7.3)
- Docker: Docker CE v18+和NVIDIA-docker v2+
- CUDA:9.2且驱动是v396.37以上,或者10.0驱动v410.48以上
cuDF的使用和Pandas基本一致,cuML的使用和sklearn的方法基本一致。所以上手非常简单。我们看一下官网运行DBSCAN的例子即可:
import cudf
from cuml.cluster import DBSCAN
# Create and populate a GPU DataFrame
gdf_float = cudf.DataFrame()
gdf_float['0'] = [1.0, 2.0, 5.0]
gdf_float['1'] = [4.0, 2.0, 1.0]
gdf_float['2'] = [4.0, 2.0, 1.0]
# Setup and fit clusters
dbscan_float = DBSCAN(eps=1.0, min_samples=1)
dbscan_float.fit(gdf_float)
print(dbscan_float.labels_)
输出的结果是:
0 0
1 1
2 2
dtype: int32
参考: https://medium.com/shachishah.ce/do-we-really-need-gpu-for-deep-learning-47042c02efe2
https://towardsdatascience.com/heres-how-you-can-accelerate-your-data-science-on-gpu-4ecf99db3430
