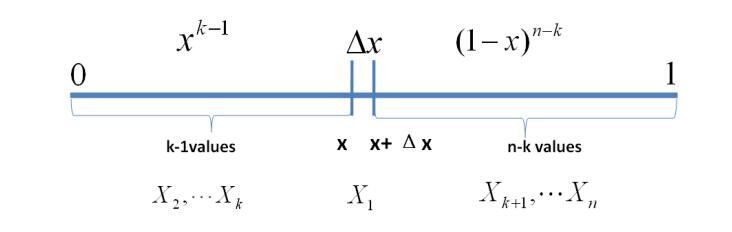
Dirichlet Distribution(狄利克雷分布)与Dirichlet Process(狄利克雷过程)
Dirichlet过程是一个随机过程,在非参数贝叶斯模型中有广泛运用,最常见的应用是Dirichlet过程混合模型
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Dirichlet过程是一个随机过程,在非参数贝叶斯模型中有广泛运用,最常见的应用是Dirichlet过程混合模型

在回归模型中加入交互项是一种非常常见的处理方式。它可以极大的拓展回归模型对变量之间的依赖的解释。本篇博客将简要介绍这个交互项。
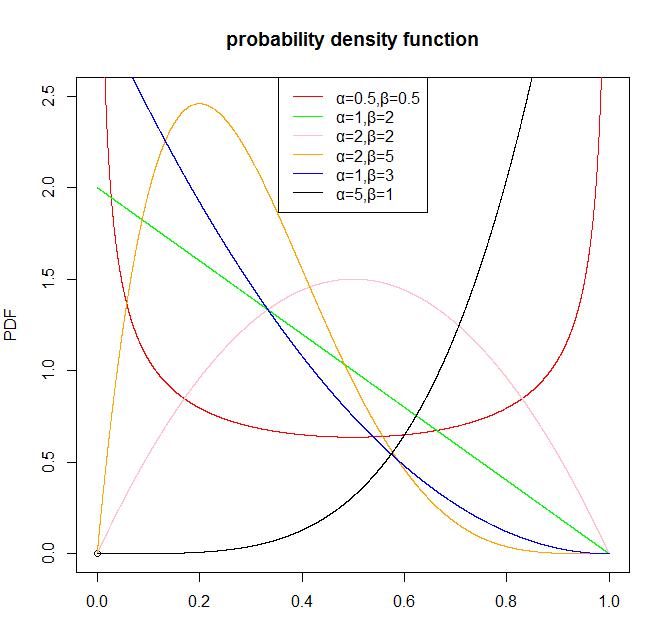
贝塔分布(Beta Distribution)是一个连续的概率分布,它只有两个参数。它最重要的应用是为某项实验的成功概率建模。在本篇博客中,我们使用Beta分布作为描述。
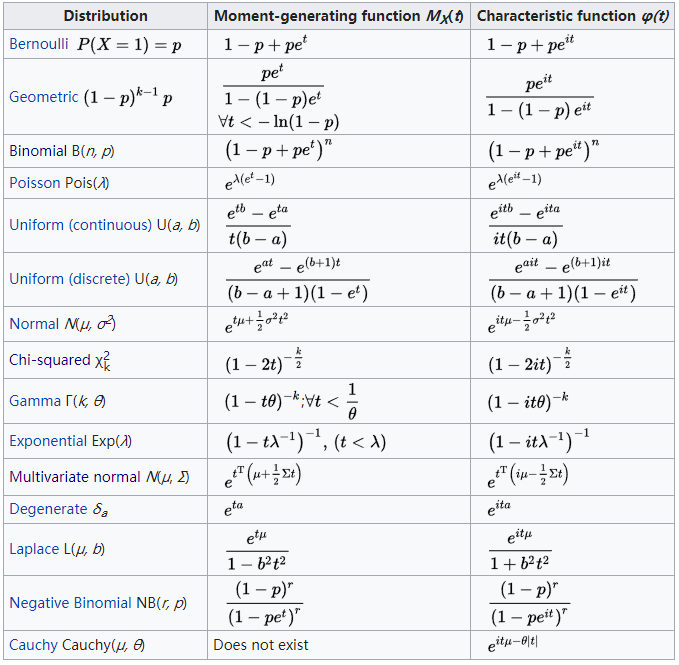
在统计学中,矩母函数是一个关于随机变量的实值函数,它可以替代密度函数来描述分布。也就是说,出了概率密度函数外,我们也可以通过矩母函数来描述分布。
在统计学中,普通最小二乘法(OLS)是一种用于在线性回归模型中估计未知参数的线性最小二乘法。这篇博客将简要描述其参数的求解过程。
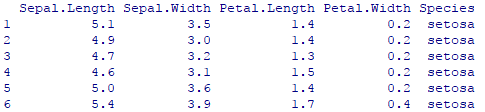
R语言进行数据分析非常简单方便,在这篇博客中,我们将描述如何使用R语言进行K-means聚类分析,并分析结果。

当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能(generalization performance,即可以很好地拟合数据)。但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。早停法就是一种防止深度学习网络模型过拟合的方法。
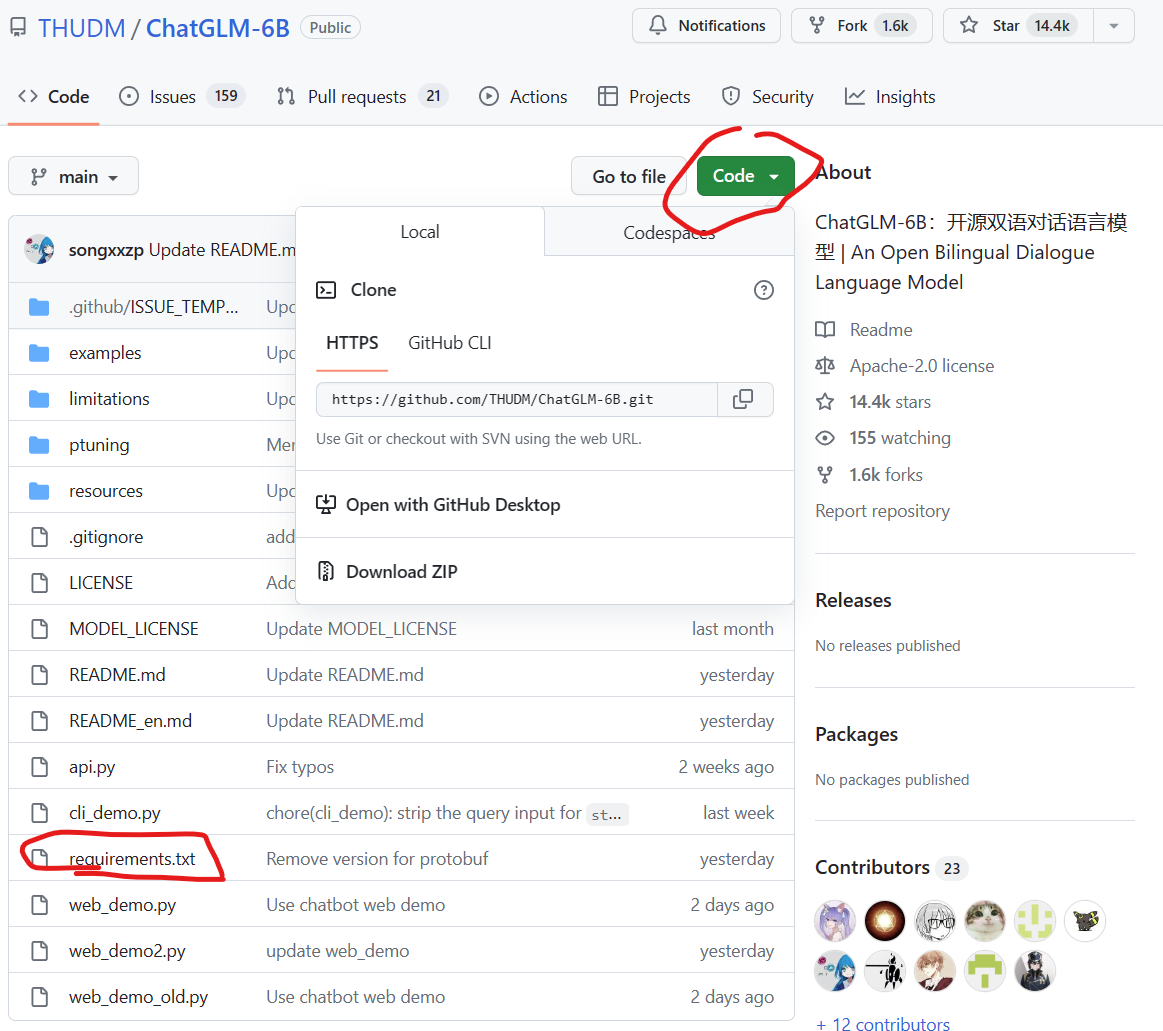
ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个类似ChatGPT的开源对话机器人,由于该模型是经过约1T标识符的中英文训练,且大部分都是中文,因此十分适合国内使用。本文将详细记录如何在Windows环境下基于GPU和CPU两种方式部署使用ChatGLM-6B,并说明如何规避其中的问题。
Wishart分布在多元高斯的贝叶斯推断中非常重要。它通常作为正态分布的协方差矩阵的逆矩阵的共轭先验存在。这篇博客将详细讲述Wishart分布及其作用。
stata 输出回归结果
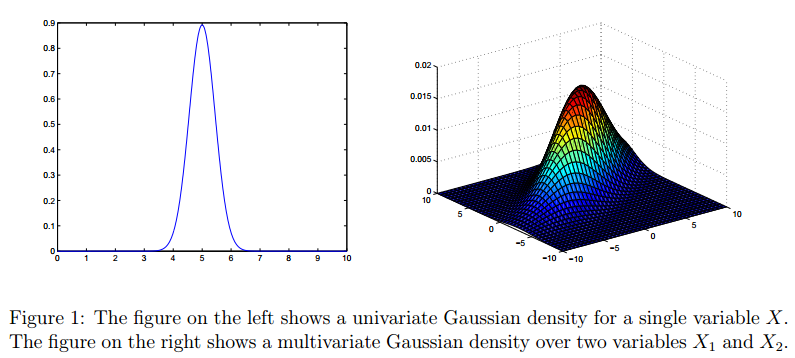
高斯分布是一种非常常见的分布,对于一元高斯分布我们比较熟悉,对于高斯分布的多元形式有很多人不太理解。这篇博客的材料主要来源Andrew Ng在斯坦福机器学习课的材料。
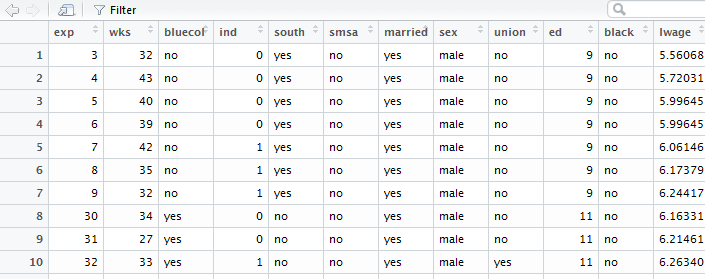
面板数据,即Panel Data,也叫“平行数据”,是指在时间序列上取多个截面,本文介绍了一个R语言处理面板数据的案例
今天发现另一个可以替代官方API的接口网站,OpenRouter。尽管OpenAI和Anthropic的模型非常好,但是开发者使用需要申请API,但是,这两个服务的API申请非常麻烦。而OpenRouter目前提供了这些接口的付费调用,价格与官网完全一致,十分良心!
在大模型领域,GGUF是一个非常常见的词语,也是非常常见的大模型预训练结果命名方式。很多人都有疑问gguf是什么格式?很多模型模型,如Yi-34B、Llama2-70B等模型都有对应的GGUF版本,这些版本都模型除了文件名多了GGUF外,其它与原有的模型名称完全一致。那么,GGUF大模型文件格式是什么意思?为什么会有这样的大模型文件,与它一同出现对比的是GGML格式文件,二者的区别是啥?
您刚刚经历了一个耗时的过程,将一堆数据加载到python对象中。 也许你从数千个网站上爬取了数据。也许你计算了pi的数值。如果您的笔记本电脑电池耗尽或python崩溃,您的信息将丢失。 Pickling允许您将python对象保存为硬盘驱动器上的二进制文件。 在你pickle你的对象后,你可以结束你的python会话,重新启动你的计算机,然后再次将你的对象加载到python中。

狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)是一种非参数贝叶斯模型,它可以理解为一种聚类方法,但是不需要指定类别数量,它可以从数据中推断簇的数量。这篇博客将描述该模型及其求解过程。

这几年在机器学习领域最亮最火最耀眼的新思想就是生成对抗网络了。这一思想不光催生了很多篇理论论文,也带来了层出不穷的实际应用。Yann LeCun 本人也曾毫不吝啬地称赞过:这是这几年最棒的想法!
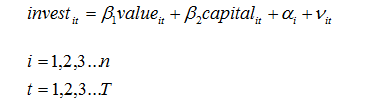
R语言,面板数据,动态回归
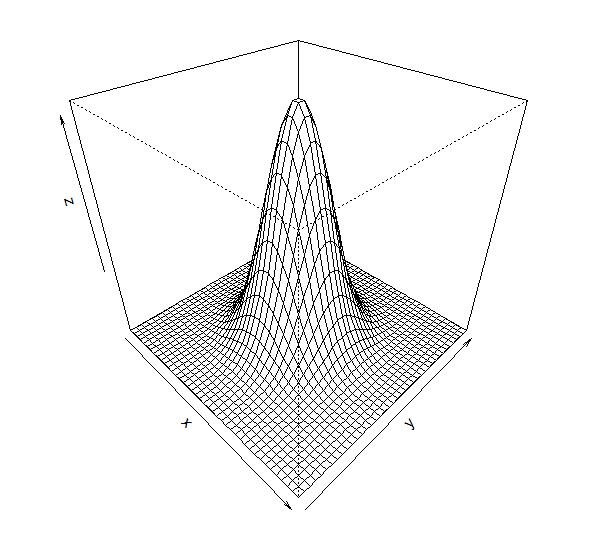
关于高斯过程,其实网上已经有很多中文博客的介绍了。但是很多中文博客排版实在是太难看了,而且很多内容介绍也不太全面,搞得有点云里雾里的。因此,我想自己发表一个相关的内容,大多数内容来自于英文维基百科和几篇文章。
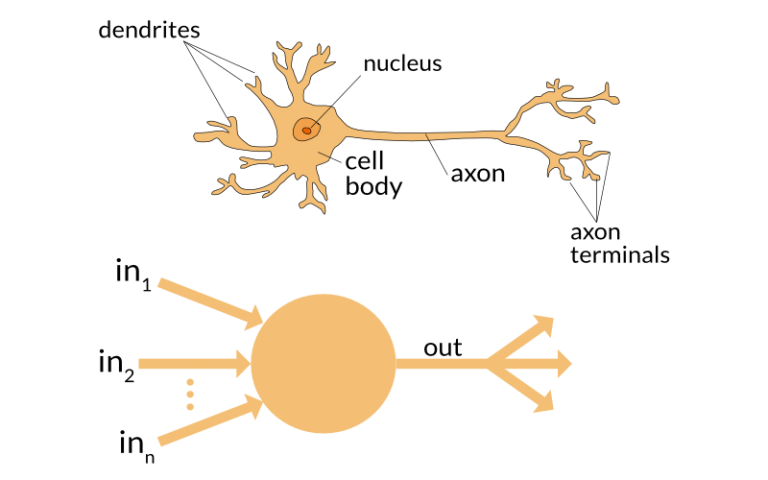
这篇博客是来自Analytics Vidhya的一篇文章。写的很不错。
R与java调用

本文简要介绍了SCI/SCI-E/SSCI的区别以及相关期刊验证查询方法