
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




大模型的发展一个重要的基础条件是底层硬件计算能力的大幅提高,特别是GPU的发展,与transformer架构的大模型训练非常契合。当前全球最大的GPU供应商英伟达系列的显卡几乎垄断了大模型训练与推理的所有GPU芯片市场。除了英伟达显卡本身算力强悍外,基于英伟达GPU之上构建的CUDA、PyTorch等平台软件生态也是非常重要的一环。而最新的PyTorch2.1版本发布的一个beta特性中包含了对华为昇腾芯片的原生支持,这也是大模型生态多样性发展的一个很重要的信号。

前段时间,OpenAI的CEO Sam Altman与二十多位开发者一起聊了很多关于OpenAI的API和产品的规划问题。Sam Altman透露了一些非常重要的OpenAI的发展方向,包括GPT产品功能的未来规划等。目前这份原始博客内容已经应OpenAI的要求被删除,这里我们简单总结一下这些内容。

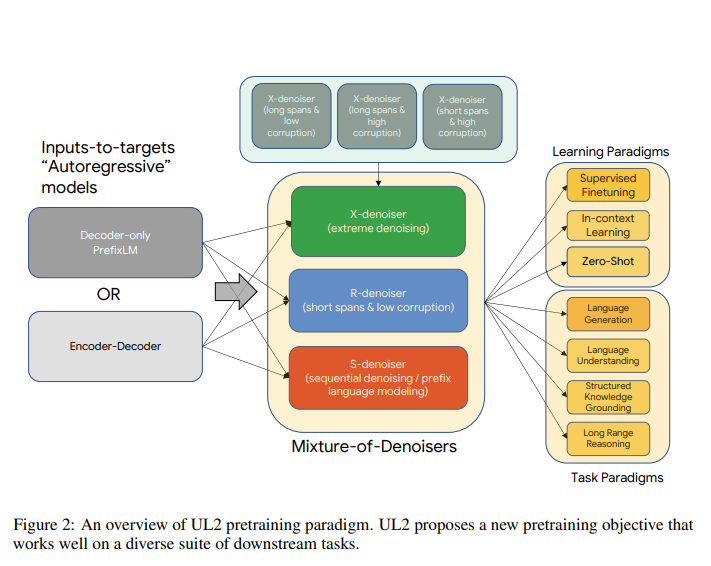
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。

对于刚接触使用Python的同学来说,Python强大的生态与优秀的开源工具应该印象十分深刻。同时对于一些已经在使用Python解决问题的童鞋来说,使用pip来安装一些别人提供的工具应该已经熟悉了。当然,也有一些同学应该也听说可以使用conda来安装一些第三方的开源包。那么,python的包管理工具pip是一个什么样的东西?conda作为一个替代者或者补充,与pip有什么区别,二者分布适合什么情况下使用呢?本文将根据我的个人经验与观点为大家做一个简单的说明。

Prompt技巧一直是提升ChatGPT等大语言模型使用效率的最重要方法之一。为此,OpenAI官方也在不断地分享官方的Prompt技巧。2023年的8月31日,OpenAI官方最新分享了一个教室使用的Prompt来帮助老师授课的案例。尽管这是针对老师的Prompt教程,但是其中的设计思路其实也可以广泛运用在客服、问答系统、编程等领域。


Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。
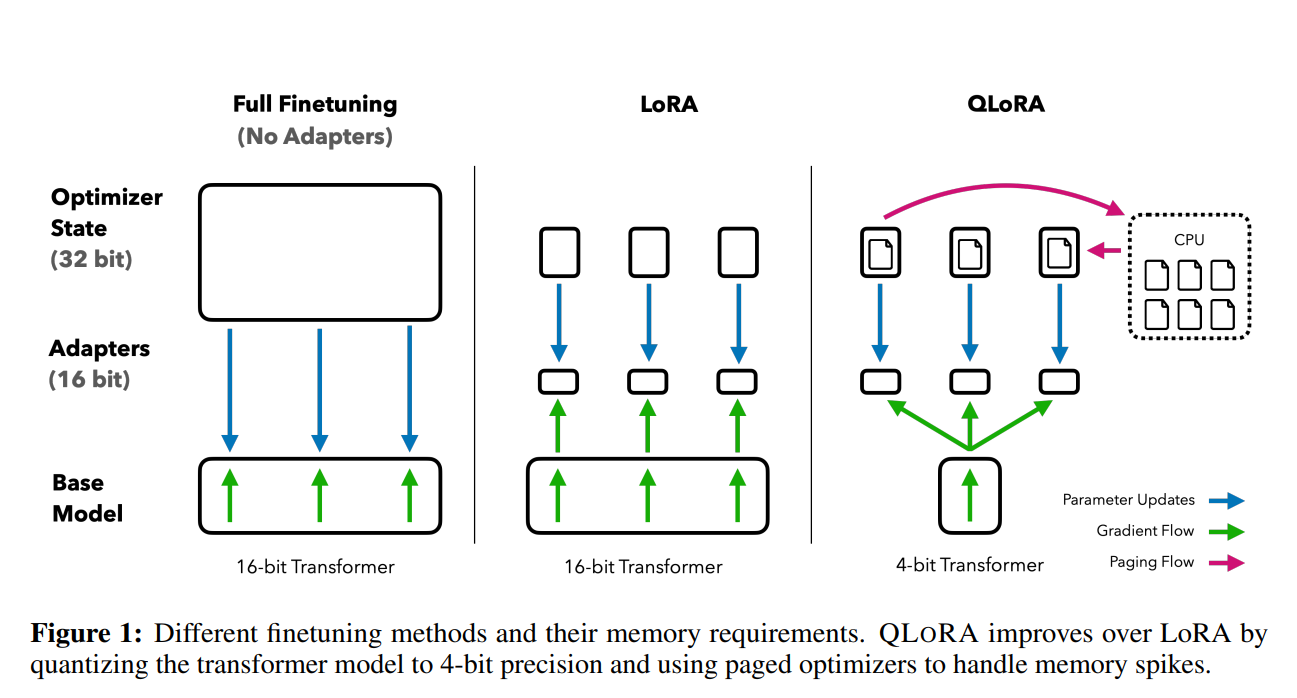
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
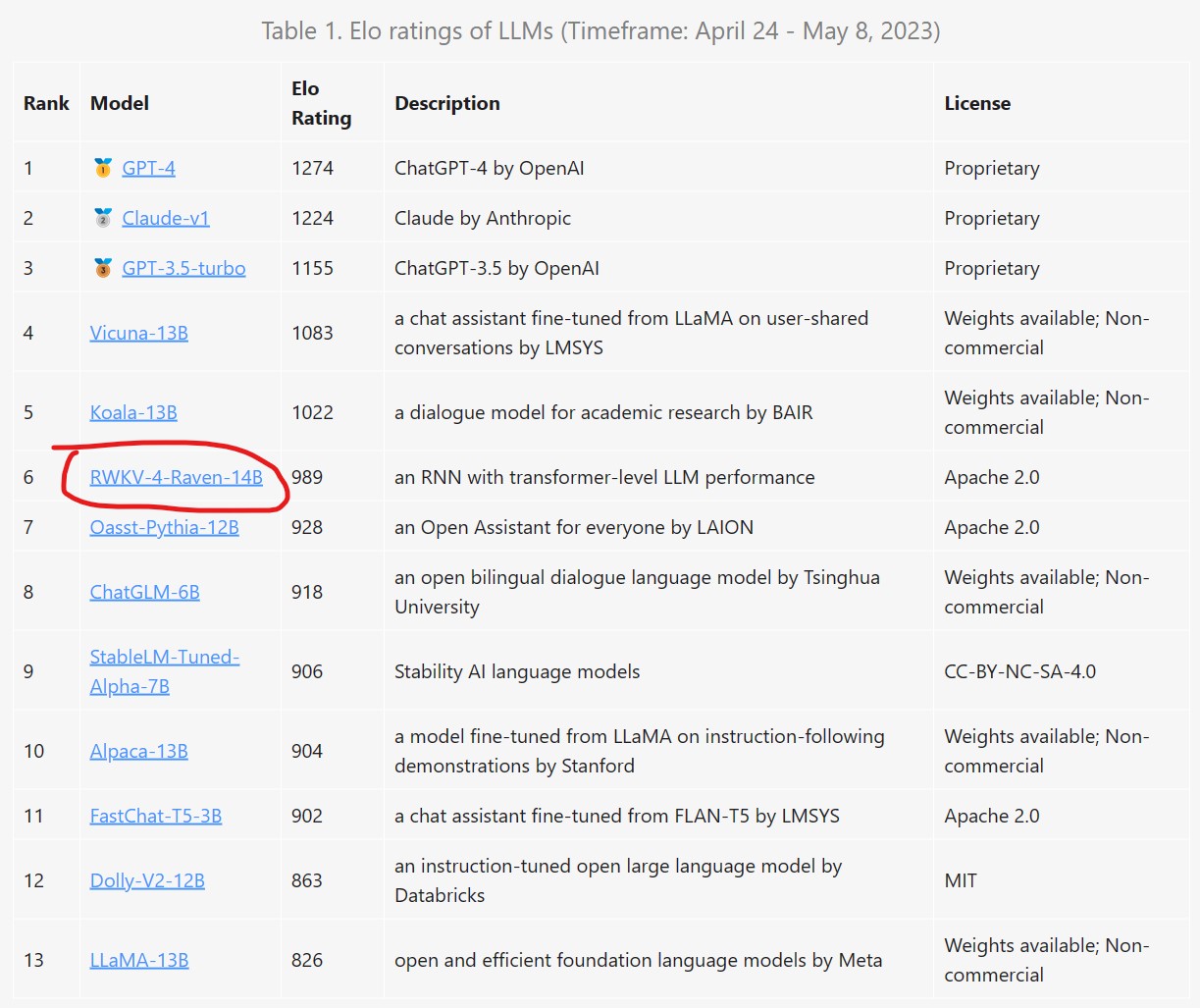
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。
今日推荐
SWE-bench Verified:提升 AI 模型在软件工程任务评估中的可靠性
重磅!谷歌宣布发布Gemini 1.5 Pro,距离Gemini发布仅仅一个半月!最高支持1000万上下文长度,GSM8K评测全球第一
Author Topic Model[ATM理解及公式推导]
支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3
月之暗面开源了一个全新的160亿参数规模的MoE大语言模型Moonlight-16B:其训练算力仅需业界主流的一半
Claude Artifacts的复制?OpenAI发布ChatGPT协作新组件:Canvas,让你与ChatGPT共同处理写作与编程问题!