
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




最近很多ChatGPT Plus用户发现GPT-4的版本有了较大的更新,一个比较吸引人的事情是大多数更新后的GPT-4的知识库已经更新到2023年4月份,而且响应速度大幅提高。不过,令人伤心的是,很多用户发现更新后的GPT-4性能大幅下降,表现在指令遵从、记忆、理解等方面。

OpenAI的Sora模型是最近两天最火热的模型。它生成的视频无论是清晰度、连贯性和时间上都有非常好的结果。在Sora之前,业界已经有了很多视频生成工具和平台。但为什么Sora可以引起如此大的关注?Sora生成的视频与此前其它平台生成的视频到底有哪些区别?有很多童鞋似乎对这些问题依然有疑问,本文将以通俗的语言解释Sora的独特之处。
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。

CVPR2022的一篇论文带来了一个39亿参数的自回归图像模型公开了他们的代码和论文。
昨天,Meta的Zuckerberg宣布,将PyTorch由Meta AI移交给Linux Foundation托管。这意味着PyTorch从今天起从Meta独立,并作为Linux Foundation下的一个项目。

今天下午,百度发布了文心一言大模型。这是一次对百度来说十分重要的发布会,也几乎是国内当前唯一一家将大模型作为一种大规模的服务推向市场的公司。本文主要介绍刚刚发布的文心一眼相关的能力。
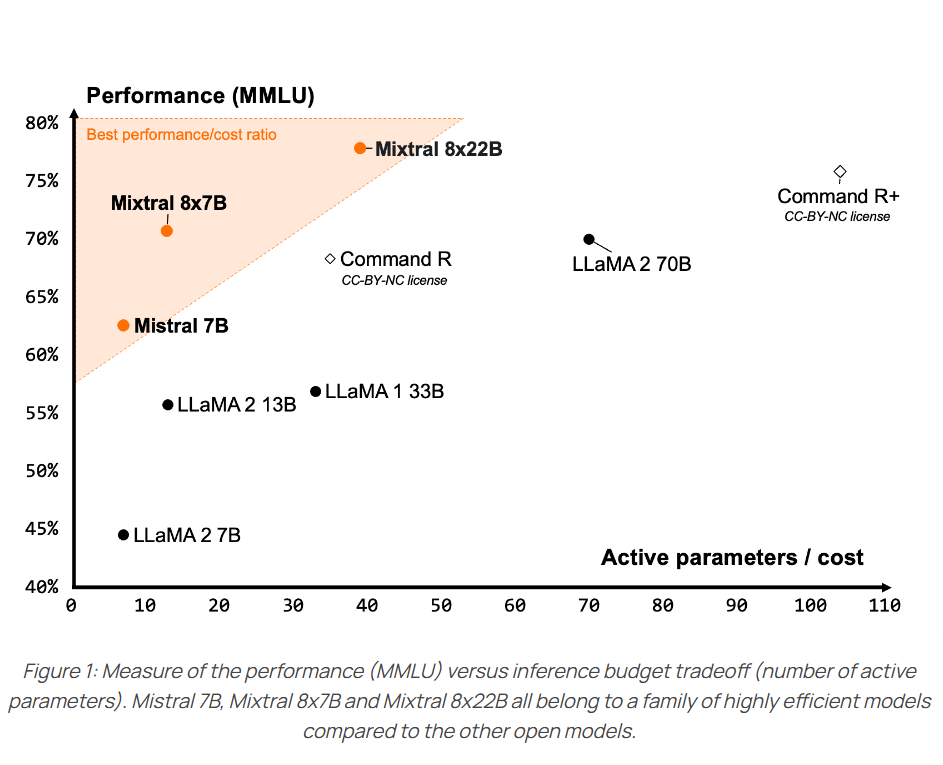
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
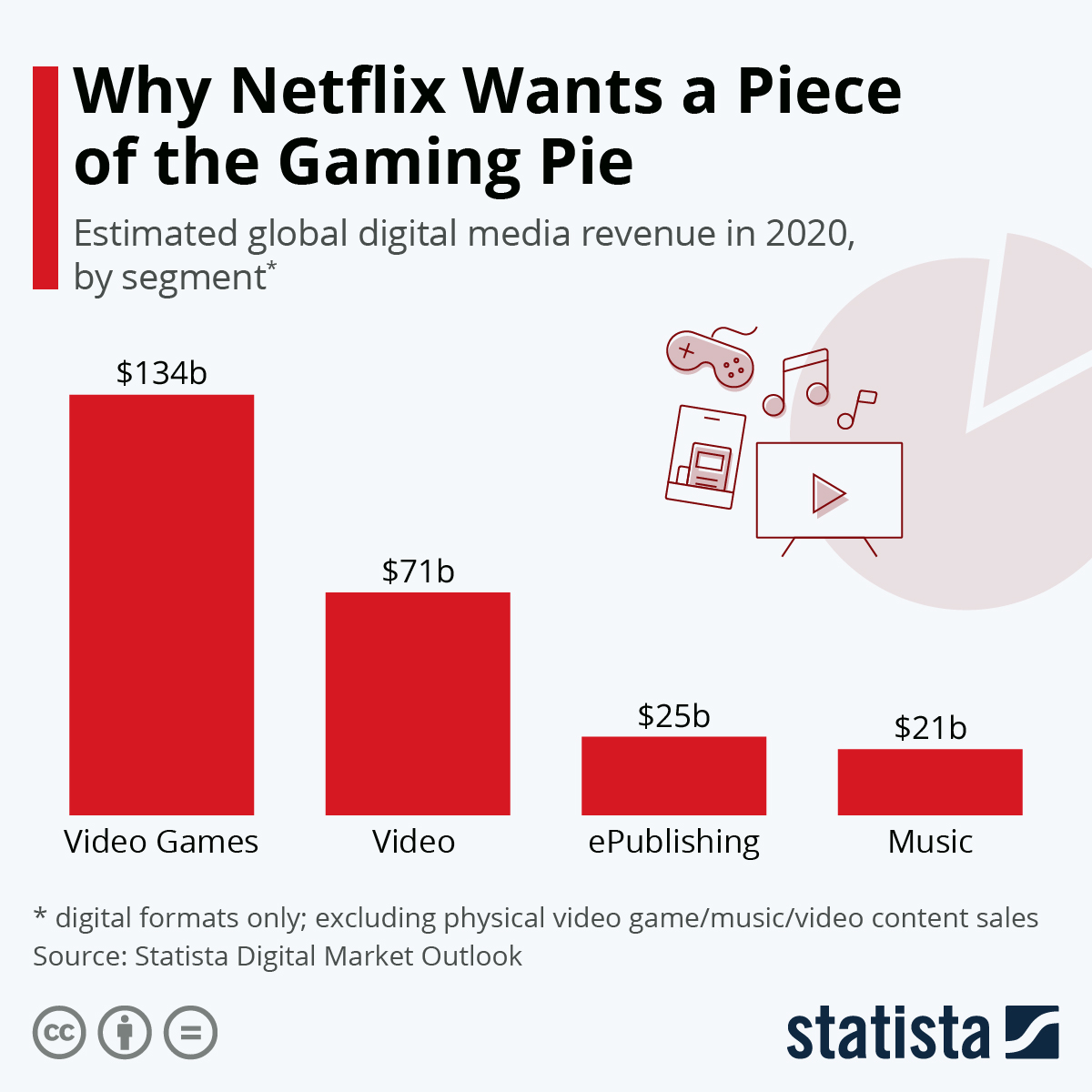
Netflix是一家网络视频服务公司,国内的爱奇艺、腾讯视频都与此类似。前几年大火的《纸牌屋》也就是这家公司提供的。当时最热吵的就是说Netflix凭借大数据选择的剧本形式与演员,让搞数据科学的人风光了好一阵。最近很火的《鱿鱼游戏》也是在Netflix全球独家播出。那么,网络视频搞得这么火热的Netflix为啥要开始搞游戏呢?这里有几个统计数据图可以解释Netflix这样做的原因。
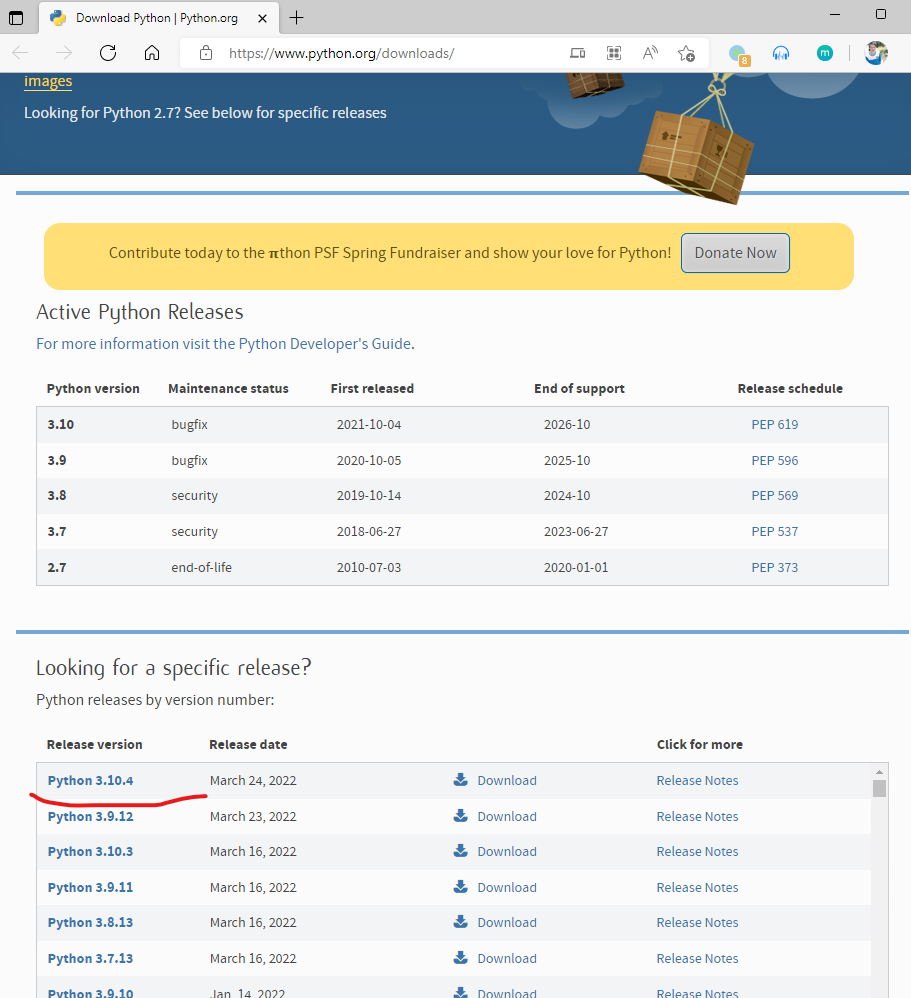
Python作为目前最流行的编程语言,因为其易用性以及丰富的库成为很多人的工具。它不仅是程序员的编程语言,也是各行各业提升工作效率的工具。本篇博客作为一篇针对完全小白的python语言搭建环境,不会为python语言本身做介绍,完全只考虑搭建python编程环境,目的是让你动手在电脑上写下第一行python程序,并成功运行,为广大童鞋提供一个入门参考。
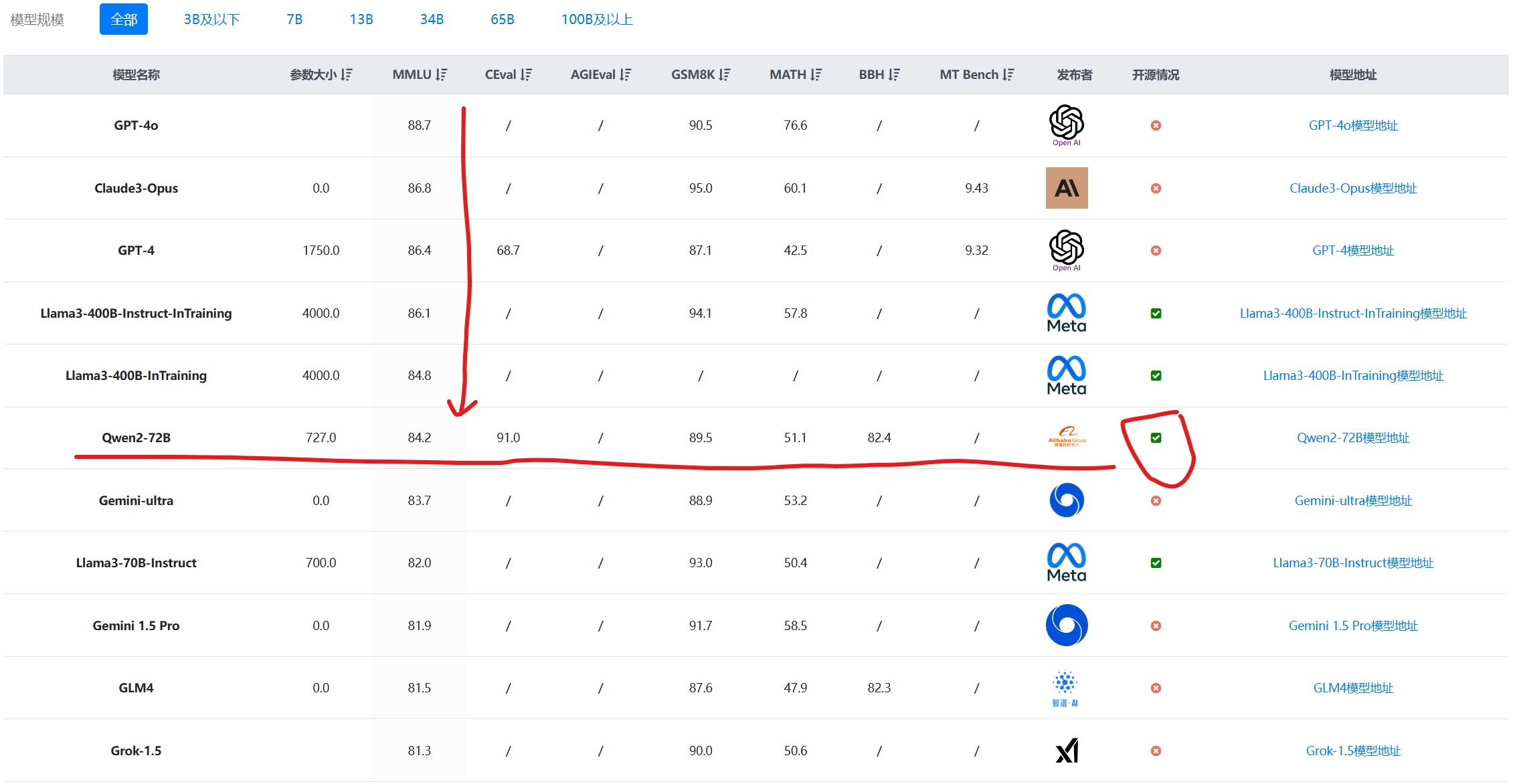
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。
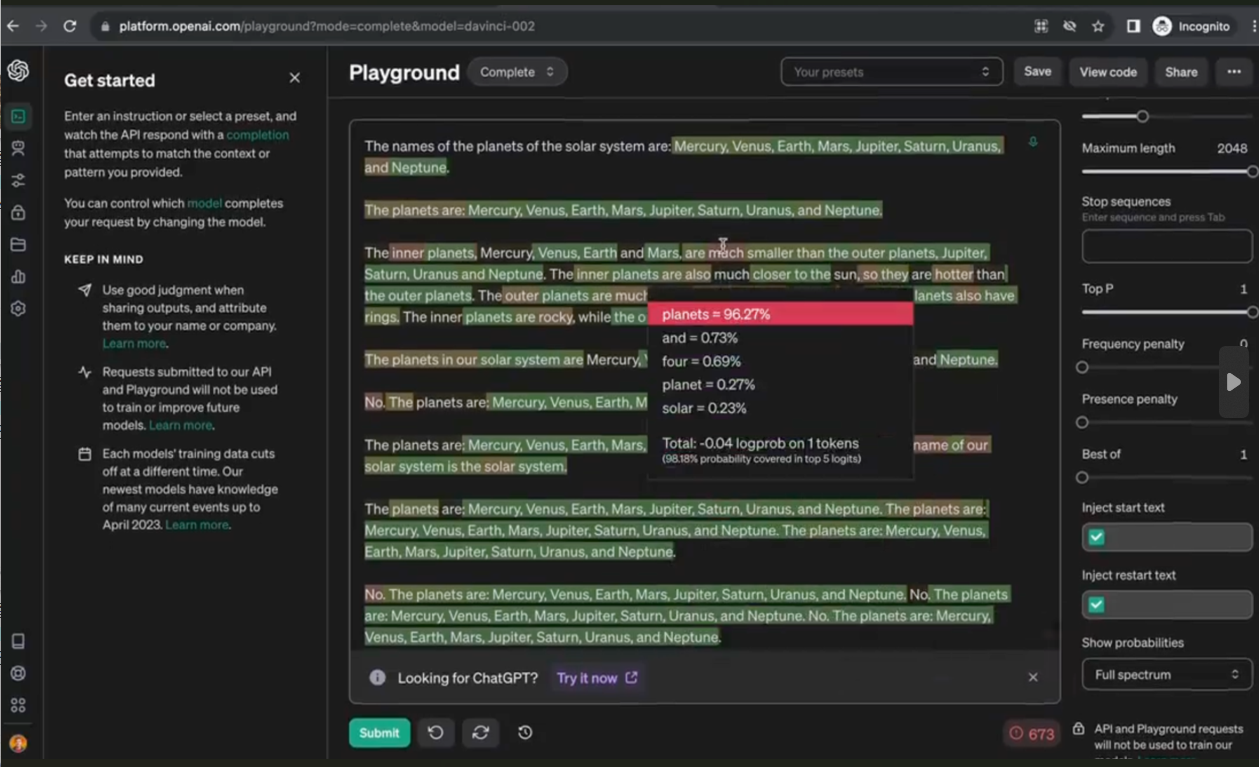
在最新的OpenAI官方接口文档中,新增了top_logprobs和logprobs这2个参数。这2个参数是一起配合使用的。后者是一个布尔类型,表明模型的返回结果中是否增加输出每个token的概率,而top_logprobs参数是一个整数类型,取值范围是0-5之间。如果top_logprobs设置为true,那么模型会根据top_logprobs的设置结果,返回输出结果中每个token及其后续的n个单词的概率。
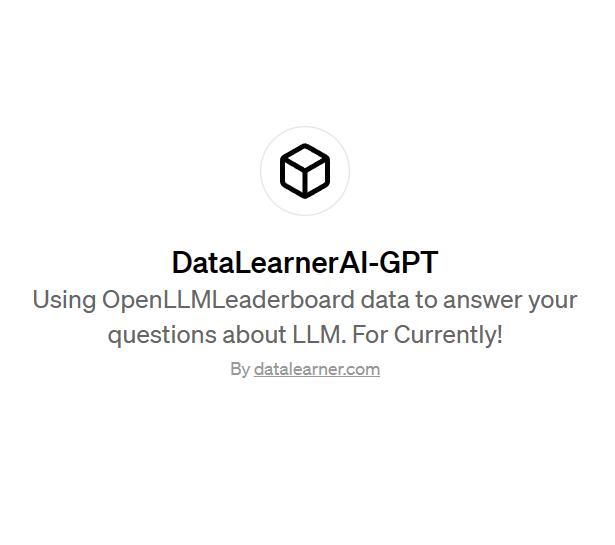
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。

最近,初创企业Pika引起了全球的目光。这家公司发布的Pika 1.0产品可以基于生成式AI技术来创建3D动画视频或者电影级别的视频。由于其逼真的效果,引起了很多人的关注。本文则介绍一个由上海人工智能实验室开源的文本生成视频大模型LaVie。这个模型可以根据文本生成高质量的视频内容。

RedPajama模型是TOGETHER发布的一个开源可商用的大模型。2023年6月6日,TOGETHER在官方宣布该模型完成训练,经过测试,该模型目前超过所有7B规模的大模型,比LLaMA-7B和Falcon-7B的效果还要好!
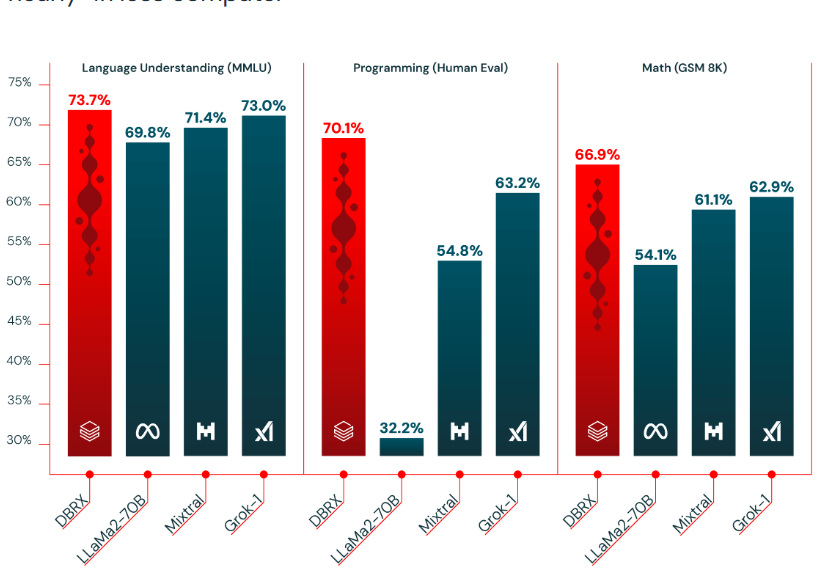
基于混合专家技术的大语言模型是当前大语言模型的一个重要方向。去年MistralAI开源了全球最有影响力的Mixtal-8×7B-MoE模型,吸引了很多关注。在2024年3月27日的今天,Databricks宣布开源一个全新的1320亿参数的混合专家大语言模型DBRX。