Unifying Language Learning Paradigms——谷歌的一个模型打天下
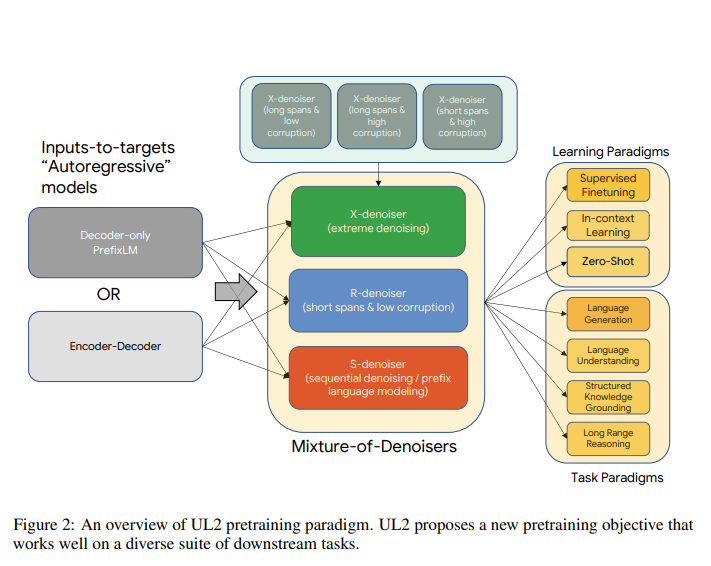
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。