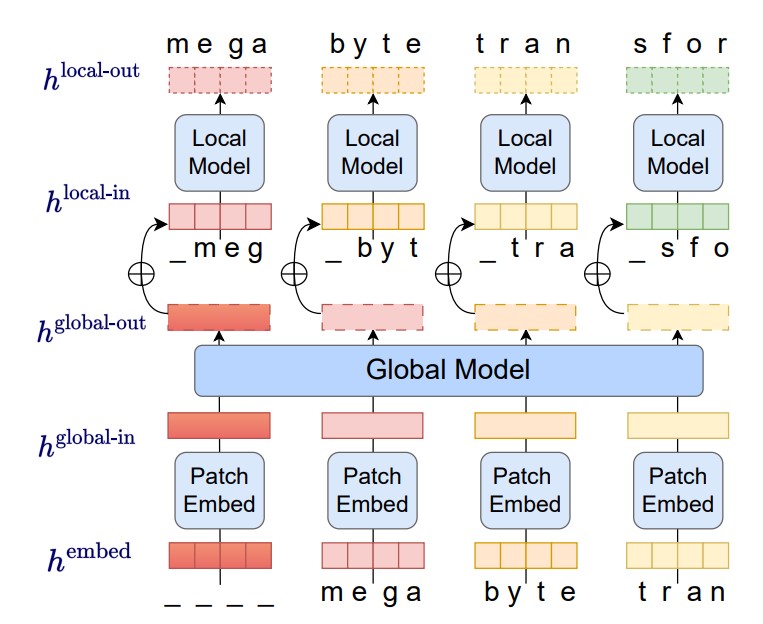
解决大语言模型的长输入限制:MetaAI发布MegaByte最高支持几百万上下文输入!
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!
汇总「长输入」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!
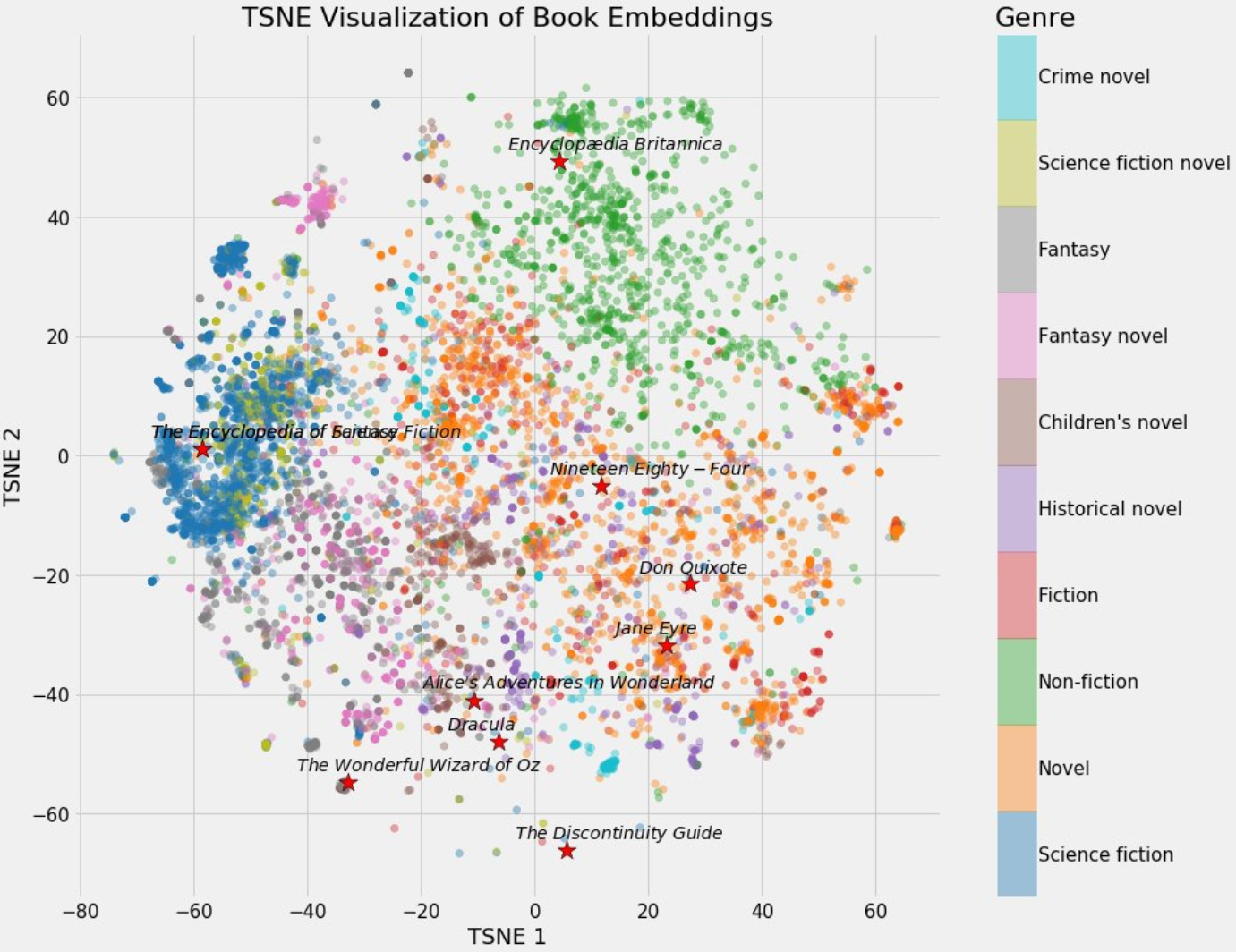
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。