最新发布!截止目前最强大的最高支持65k输入的开源可商用AI大模型:MPT-7B!
昨天,开源AI模型领域迎来一个重磅玩家,MosaicML发布MPT-7B系列模型,根据官方宣布的测试结果,MPT-7B的水平与MetaAI发布的LLaMA-7B水平差不多,属于当前开源领域最强大的模型。最重要的是,MPT-7B系列中有一个可以支持最多65k上下文输入的开源模型,比GPT-4的32k还高!应该是目前最长的!
目前,MPT-7B模型系列包含4个,其中3个开源可商用,一个是非商用模型。不过,就在今天,因为MPT-7B训练数据的问题也引发了一些人对于它产权的质疑。

上述截图来自DataLearner官方的MPT-7B模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/MPT-7B
本文将介绍一下MPT-7B模型的信息,以及它受到的一个合规质疑。
MPT-7B简介
MPT全称是MosaicML Pretrained Transformer,是MosaicML发布的一系列大模型。尽管业界已经发布了很多大模型,但是这些模型通常都比较难以训练和部署。而MosaicML发布这样的大模型的目的就是为了解决上述限制,提供一个完全开源且可商用的一个大模型。MPT系列主要的特点是:
- 有商用许可
- 基于大量的数据训练
- 目标是解决长输入(最高支持65K的输入,84K的处理)
- 训练与推理速度的优化
- 高效的开源训练代码
从这些特点看,MPT真的是一个很优秀的开源大模型,且官方宣称它的评测结果与LLaMA-7B差不多。
注意,MPT-7B是MosaicML基于自己的平台重新训练的新的transformer模型,因此不受到之前任何模型的许可限制。
MPT-7B模型的训练细节
MPT-7B基于1万亿tokens的文本和代码数据训练得到。是一个decoder-style类型的transformer。
它的训练是基于MosaicML自己收集的数据进行的,主要使用的数据集如下图所示:
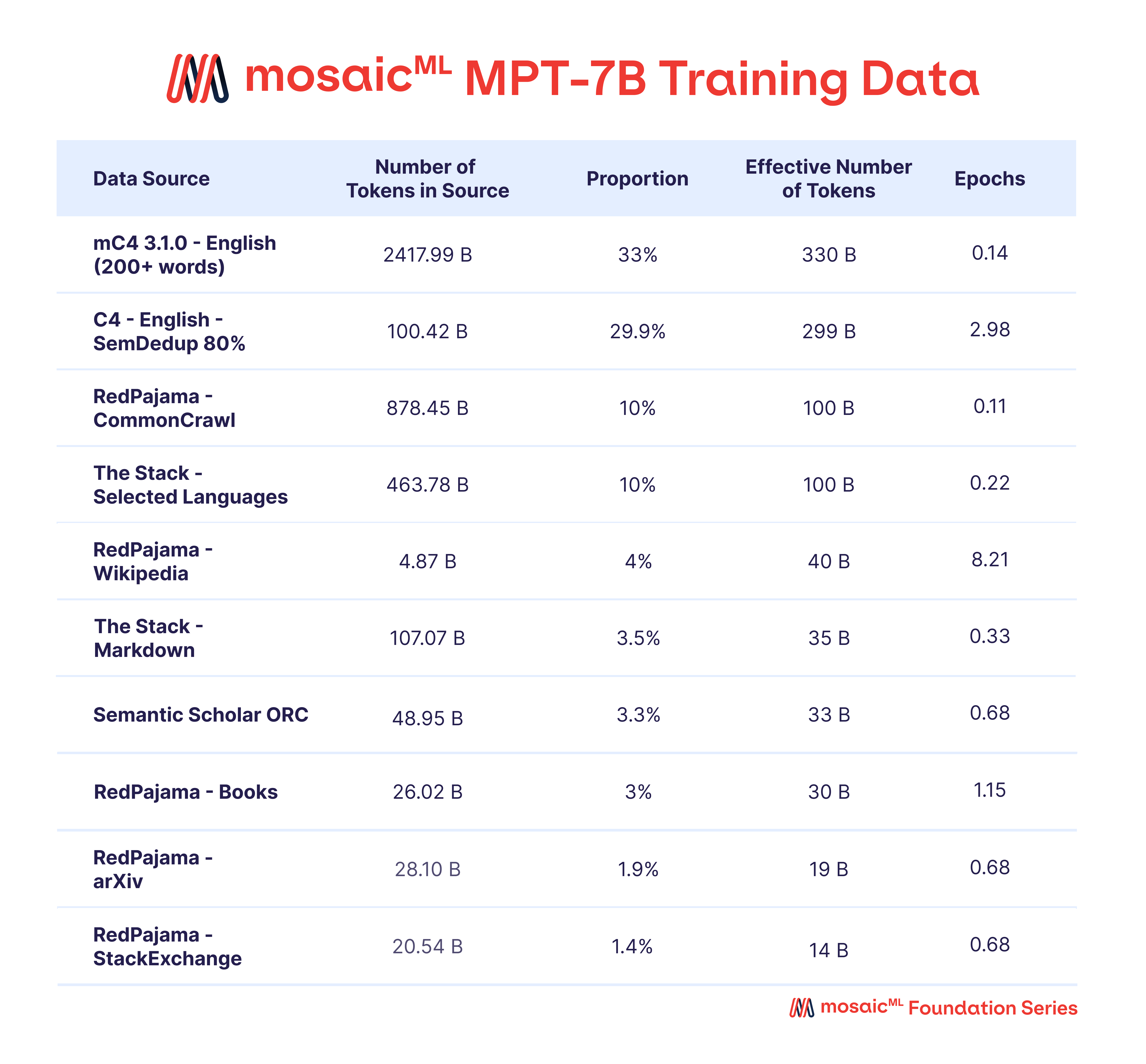
MosaicML训练使用的Tokenizer是EleutherAI发布的GPT-NeoX 20B tokenizer。原始的tokenizer的词汇表是50257,但是MPT模型设置的是50432,原因是50432正好是128的整数倍,可以提高MFU。另一个原因是官方希望留一些tokens可以用在后面的UL2训练中。
此外,MPT-7B的训练是基于MosaicML自己的平台做的,具体技术工具如下:
- 基于Oracle Cloud的A100-40GB和A100-80GB训练
- 架构使用MosaicML的MosaicML platform
- 数据集采用Oracle提供的OCI对象存储服务,和MosaicML的Streaming工具
- 训练软件:Composer、PyTorch FSDP和LLM Foundry
上述涉及的工具大家也可以去官方的GitHub查看详情,可以学习一下这个MPT相关的训练平台,毕竟它的效果很好。
MPT-7B的版本
MPT-7B此次发布的共4个版本,并不是每一个版本都是授权商用的。
如上图所示,除了基础版本外,还有三个基于基础版本微调的模型。分别针对不同的应用,其中比较有意思的是MPT-7B-StoryWriter-65k+。
大多数模型最多只能处理几千个tokens,但是这个模型最多可以处理65k的上下文信息。如下图所示:
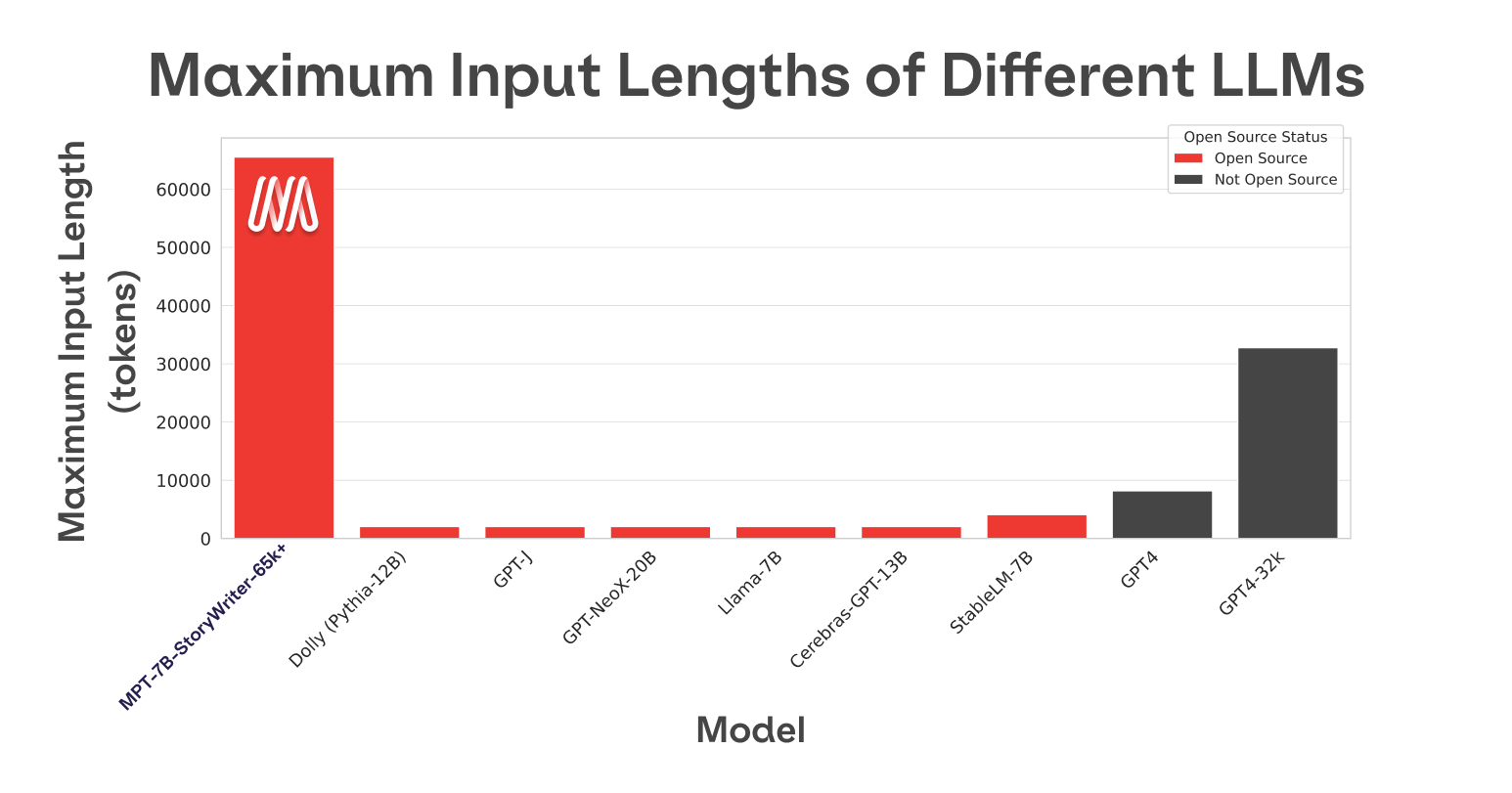
主要的原因是使用了一个关键的技术——ALiBi。
ALiBi是华盛顿大学和FacebookAI(那会还没改名)在2021年8月份联合发布的一个技术。全称是带线性偏差的注意力机制(Attention with Linear Biases,ALiBi)。ALiBi不会将位置嵌入添加到词嵌入中,而是通过一个与距离成比例的惩罚来调整Query-Value的注意力得分。详情:https://arxiv.org/abs/2108.12409。该方法可以将输入的长度extrapolate(原文的单词)到更长的情况,但是训练速度和内存使用都在降低!
官方演示了用这个模型阅读《了不起的盖茨比》(全文长度68k),然后生成了一个新的结尾(推理读取这个数据使用了约20秒)。生成的速度略慢,约每分钟105个单词。不过长输入的一个优点就是未来我们可以做更多的事情了,包括阅读论文,技术文档等。
MPT-7B的性能
官方放出了不同模型在不同任务上的对比结果:
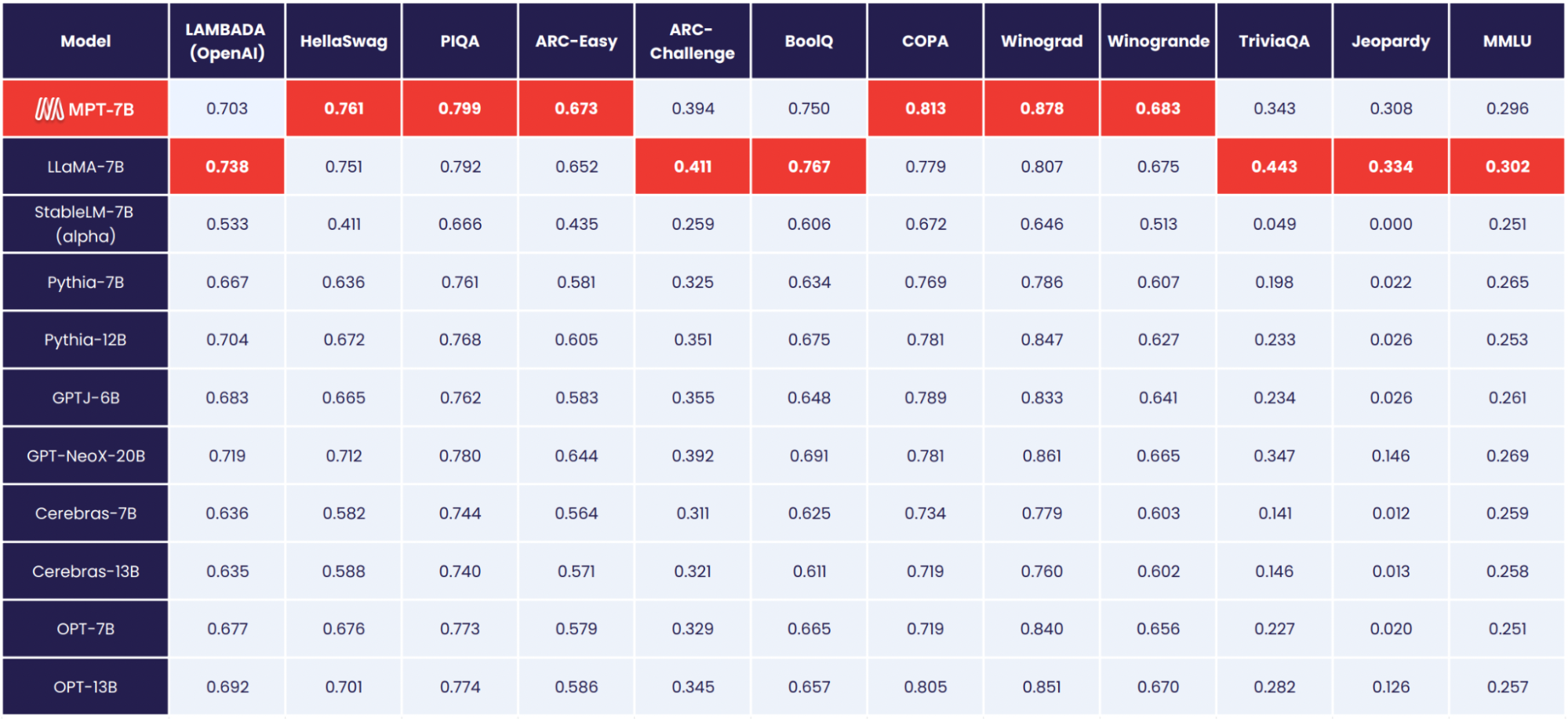
可以说,在70亿参数规模领域,MPT-7B算的上最优秀的一类了。不过我好奇,看这个样子,目前大多数模型都达不到LLaMA的效果啊~~
MPT-7B陷入了争议
不过,MPT-7B模型在今天早些时候也引发了一个问题:版权问题。
CreativeAI的创始人对MPT-7B的开源做了质疑。也是因为前面的这个65k输入的模型,MPT-7B-StoryWriter-65k+。这个模型为了取得更好的效果,使用了books3数据集的一个子集。这是EleutherAI开源的一个数据集,属于Pile数据集的一部分。该数据集包含197000本书的文本内容。不过它里面是有版权的。因此,他质疑首先MosaicML没有获得授权,也没有权力开源MPT-7B-StoryWriter-65k+。
另外,官方宣称MPT-7B-Chat不可以商用的原因是因为它与 ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, and Evol-Instruct等模型提供的数据集做了微调,因此为了避免法律问题他们选择开源但是不授权商用!这也被质疑是区别对待。
MPT-7B总结
尽管MPT-7B受到了一些质疑,但是总体来说,它依然是一个十分优秀的开源模型,甚至是70亿参数规模中最优秀的开源模型。而它的MPT-7B-StoryWriter-65k+更是打开了长输入的空间。难关谷歌自己人也焦虑,开源发展的确是太快了!
MPT-7B的模型的代码、预训练文件地址等信息请关注DataLearner模型卡:https://www.datalearner.com/ai-models/pretrained-models/MPT-7B
我们将会一直更新。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
