
Terminal-Bench 2.1:终端环境下的AI代理评测基准
Terminal-Bench是一个针对AI代理在真实终端环境中的能力评测基准,由Stanford University与Laude Institute合作开发。Terminal-Bench 2.1是2.0的改进版本,基于Z.ai的Terminal-Bench 2.0 Verified进行优化,目前处于活跃状态,但任务尚未完全上传。
汇总「评测基准」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
Terminal-Bench是一个针对AI代理在真实终端环境中的能力评测基准,由Stanford University与Laude Institute合作开发。Terminal-Bench 2.1是2.0的改进版本,基于Z.ai的Terminal-Bench 2.0 Verified进行优化,目前处于活跃状态,但任务尚未完全上传。
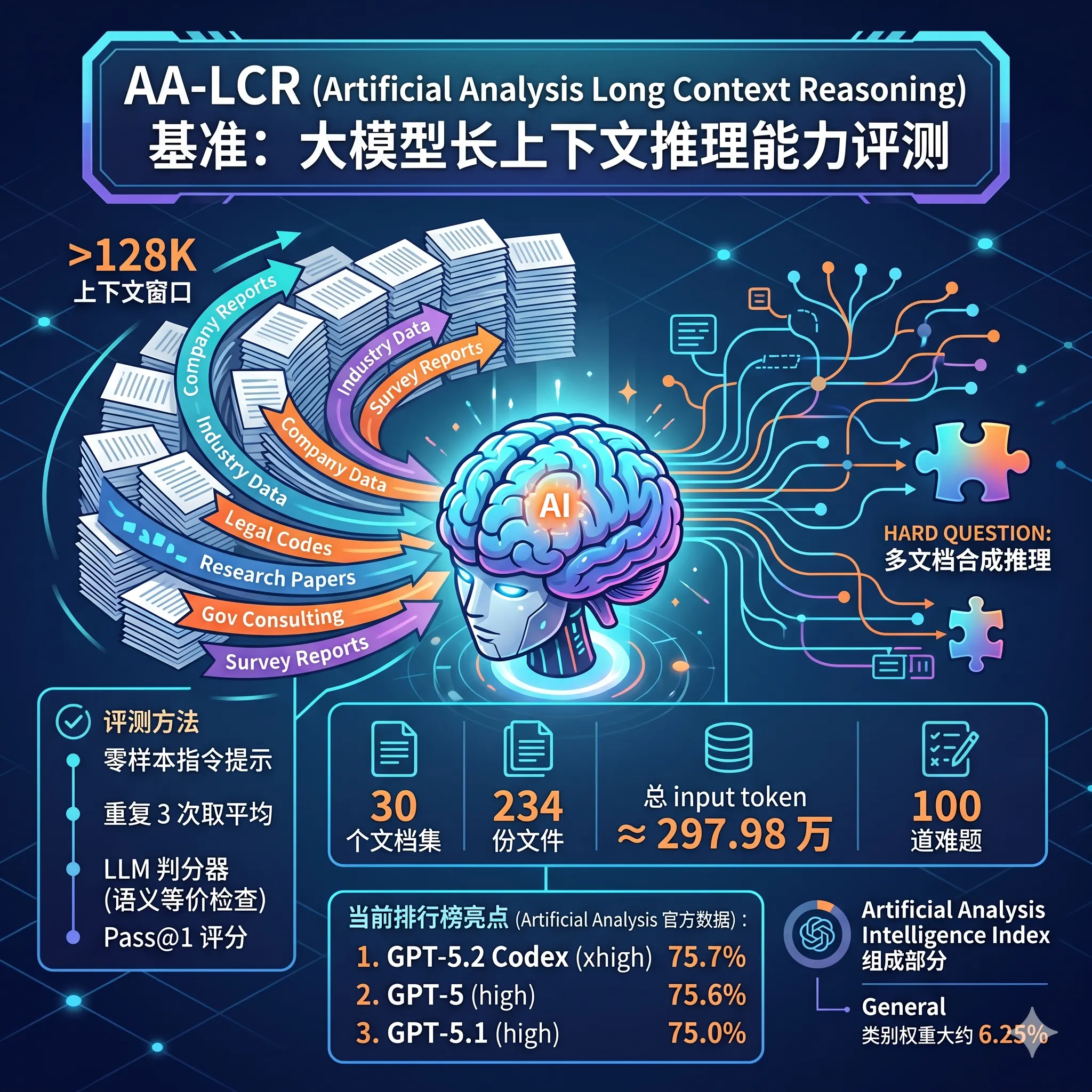
AA-LCR 是由独立 AI 评测机构 Artificial Analysis 开发的基准测试集,旨在真实模拟知识工作者(如分析师、研究员、律师)处理海量文档的场景。
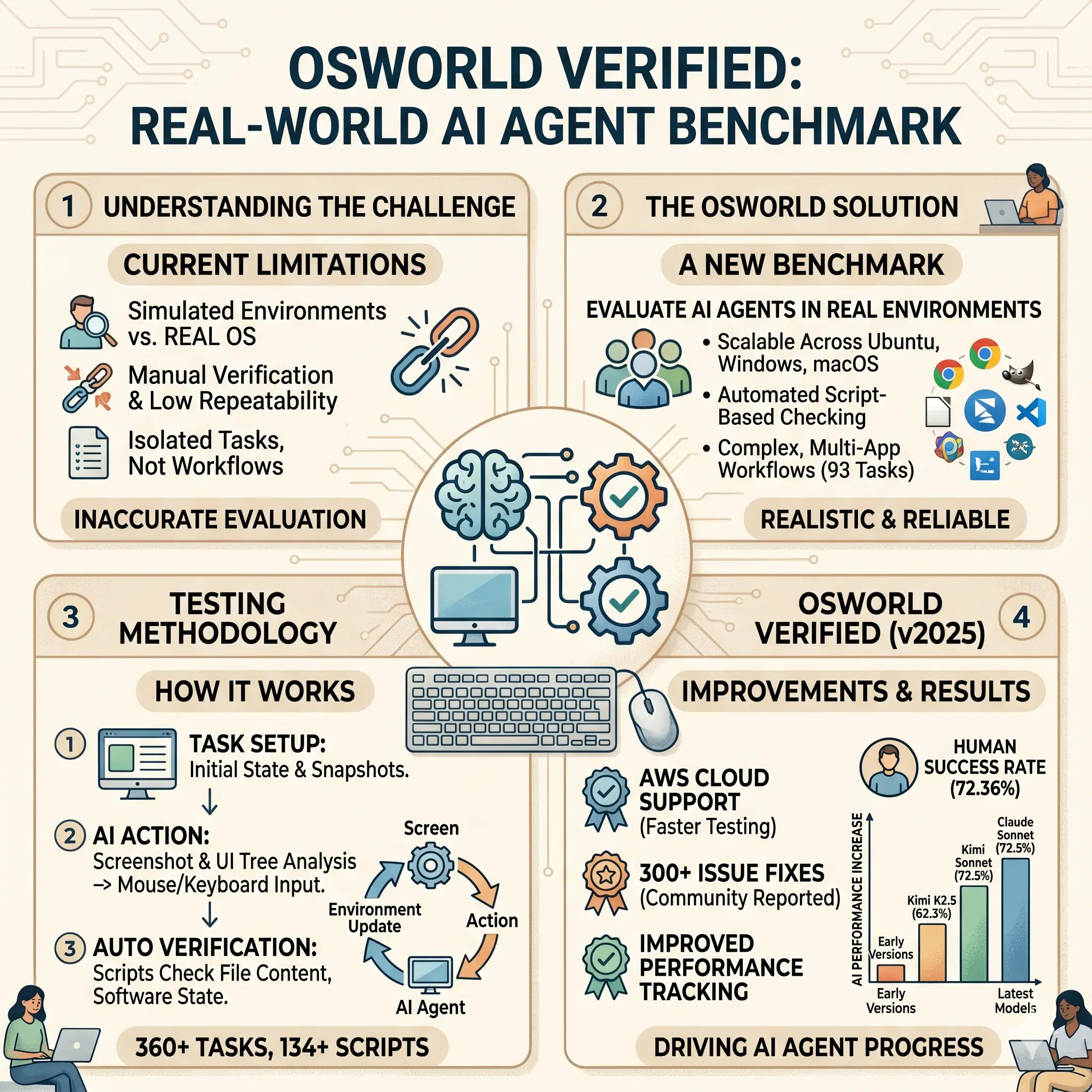
OSWorld 是一个用于测试 AI 代理在真实计算机环境中的基准。这些代理是能处理文字、图片等信息的 AI 系统。基准包括开放式任务,比如操作文件或使用软件。OSWorld Verified 是它的改进版,通过修复问题和提升运行方式,提供更准确的测试结果。它支持不同操作系统,如 Ubuntu、Windows 和 macOS,并允许 AI 通过互动学习来完成任务。
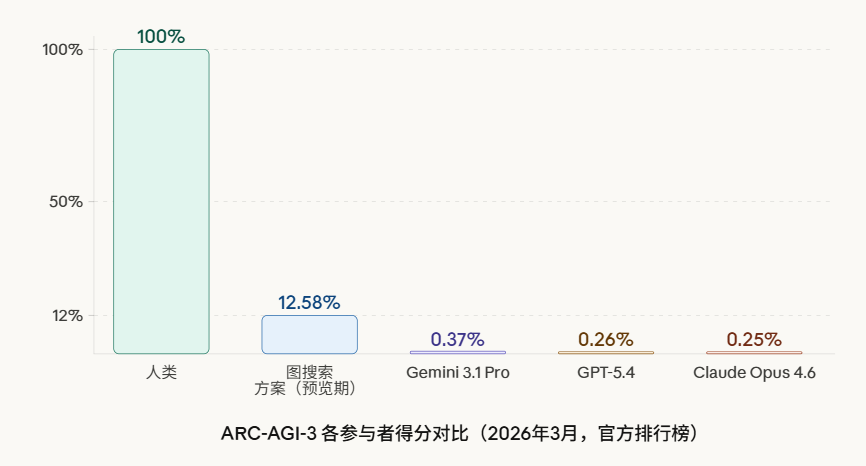
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。
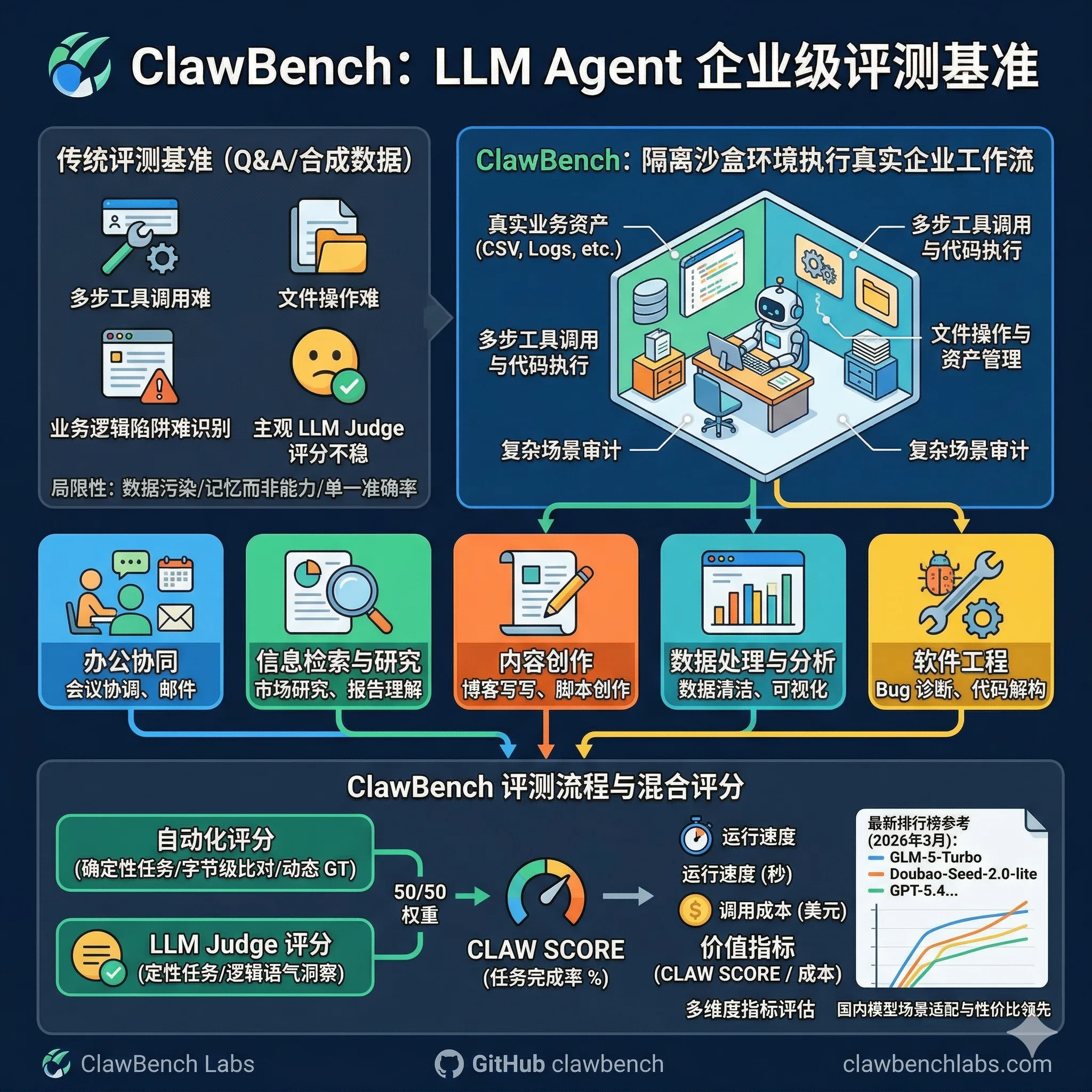
ClawBench 是针对大模型智能体(LLM Agent)的评测基准。它通过隔离沙盒环境中的真实企业工作流任务,评估大模型在实际部署场景下的表现,与传统问答式或合成数据集基准形成区别。ClawBench 与 PinchBench 均服务于 OpenClaw 生态,但二者侧重点不同:PinchBench 是 OpenClaw 官方基准,由 kilo.ai 团队开发,聚焦 23 类真实任务的成功率、速度和成本;ClawBench 则独立构建,包含 30 个高级任务,覆盖 5 大核心业务场景,采用混合评分机制
SWE-bench Multilingual 是 SWE-bench 基准系列的扩展版本。该基准用于评估大语言模型在软件工程任务上的表现,覆盖多种编程语言。数据集包含 300 个从真实 GitHub 问题与对应拉取请求中提取的任务,涉及 42 个仓库和 9 种编程语言。模型接收问题描述与仓库快照后,需生成代码补丁,并通过失败到通过(F2P)和通过到通过(P2P)测试套件进行验证。
OSWorld(Open Source World)是首个真正基于真实操作系统环境的多模态Agent评测平台。它不同于传统的模拟环境(如MiniWoB或WebArena),而是直接在完整的Ubuntu、Windows和macOS系统中运行,让AI代理通过截图观察、鼠标键盘操作来完成任务。
OpenAI在2025年9月推出的GDPval基准,将焦点转向“具有经济价值的真实任务”,而第三方独立机构Artificial Analysis在此基础上开发的GDPval-AA,进一步引入了agentic(代理)能力评估和ELO排行榜,成为当前最受关注的“实用性”评测基准之一。
MMEB(Massive Multimodal Embedding Benchmark)是一个用于评估多模态嵌入模型的基准测试框架。该基准最初聚焦于图像-文本嵌入,并在后续版本中扩展到文本、图像、视频和视觉文档输入。MMEB通过收集多样化数据集,提供一个统一的评估平台,用于测试模型在分类、检索和其他任务上的性能。
Context Arena 是一个专注于评估大语言模型长上下文处理能力的基准平台。它基于 OpenAI 发布的 Multi-Round Coreference Resolution (MRCR) 数据集,提供交互式排行榜,用于比较不同模型在复杂长对话中的信息检索和理解性能。该基准强调模型在长上下文下的实际表现,避免单纯依赖训练数据记忆。
Tool Decathlon(简称 Toolathlon)是一个针对语言代理的基准测试框架,用于评估大模型在真实环境中使用工具执行复杂任务的能力。该基准涵盖32个软件应用和604个工具,包括日常工具如 Google Calendar 和 Notion,以及专业工具如 WooCommerce、Kubernetes 和 BigQuery。它包含108个任务,每个任务平均需要约20次工具交互。该框架于2025年10月发布,旨在填补现有评测在工具多样性和长序列执行方面的空白。通过执行式评估,该基准提供可靠的性能指
本文介绍 Terminal-Bench 的设计理念,深入讲解 core、Terminal-Bench Hard 与最新 Terminal-Bench 2.0 的区别,帮助开发者选择合适的 AI 终端评测基准。
IMO-Bench 是 Google DeepMind 开发的一套基准测试套件,针对国际数学奥林匹克(IMO)水平的数学问题设计,用于评估大型语言模型在数学推理方面的能力。该基准包括三个子基准:AnswerBench、ProofBench 和 GradingBench,涵盖从短答案验证到完整证明生成和评分的全过程。发布于 2025 年 11 月,该基准通过专家审核的问题集,帮助模型实现 IMO 金牌级别的性能,并提供自动评分机制以支持大规模评估。

LiveBench是一个针对大型语言模型(LLM)的基准测试框架。该框架通过每月更新基于近期来源的问题集来评估模型性能。问题集涵盖数学、编码、推理、语言理解、指令遵循和数据分析等类别。LiveBench采用自动评分机制,确保评估基于客观事实而非主观判断。基准测试的总问题数量约为1000个,每月替换约1/6的问题,以维持测试的有效性。
BrowseComp是一个用于评估AI代理网页浏览能力的基准测试。它包含1266个问题,这些问题要求代理在互联网上导航以查找难以发现的信息。该基准关注代理在处理多跳事实和纠缠信息时的持久性和创造性。OpenAI于2025年4月10日发布此基准,并将其开源在GitHub仓库中。
IFBench 是一个针对大语言模型(LLM)指令跟随能力的评测基准。该基准聚焦于模型对新颖、复杂约束的泛化表现,通过 58 个可验证的单轮任务进行评估。发布于 2025 年 7 月,该基准旨在揭示模型在未见指令下的精确执行水平。目前,主流模型在该基准上的得分普遍低于 50%,显示出指令跟随的潜在局限。

Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。
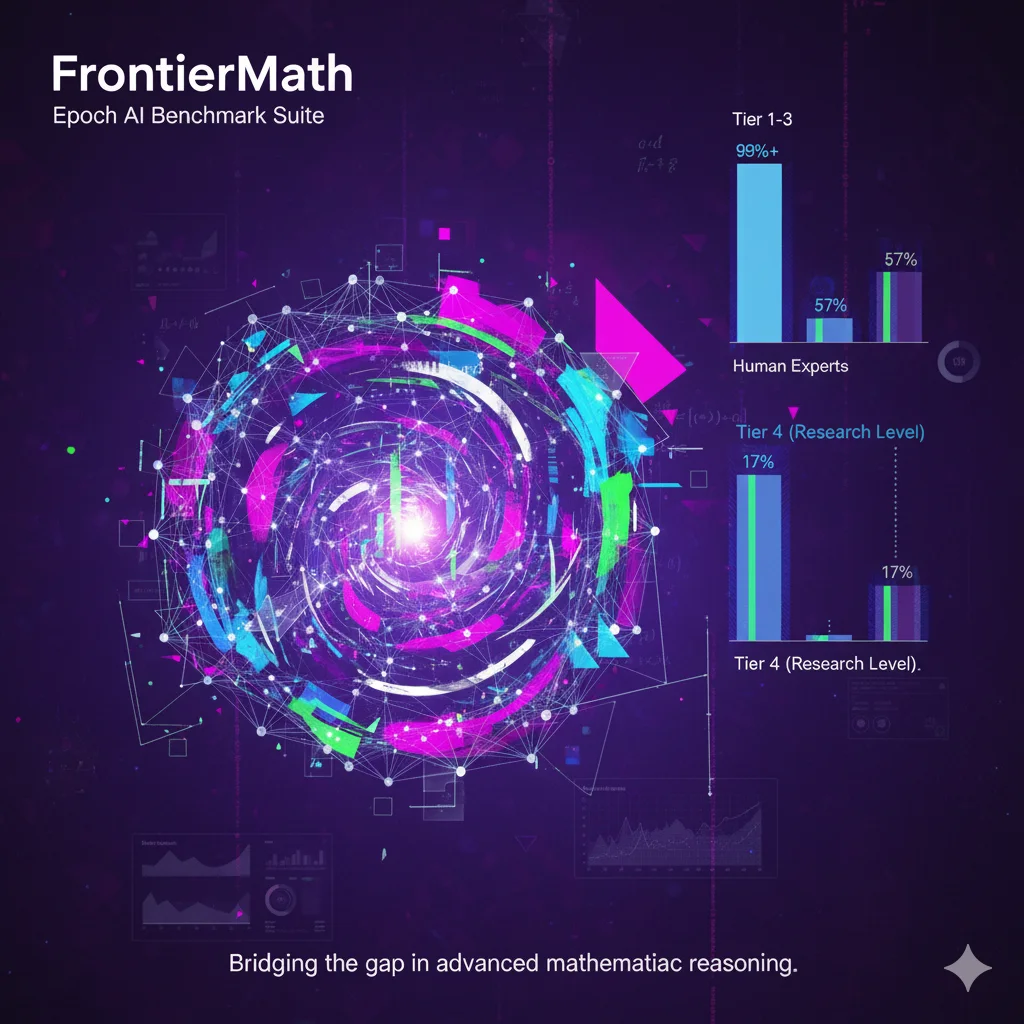
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。

为了解决大模型的Agent操作依赖交互和人工处理这个问题,普林斯顿大学与 Sierra Research 的研究团队在 2025 年 6 月提出了 τ²-Bench(Tau-Squared Benchmark),并发布了论文《τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment》。 它是对早期 τ-Bench 的扩展版本,旨在建立一种标准化方法,评估智能体在与用户共同作用于环境时的表现。
Aider 是一个在终端里进行结对编程的开源工具。为评估不同大模型在“按照指令对代码进行实际可落地的编辑”上的能力,Aider 提出并维护了公开基准与排行榜,用于比较模型在无人工干预下完成代码修改任务的可靠性与成功率。该评测已被多家模型提供方在技术说明中引用,用作代码编辑与指令遵循能力的对照指标。
在衡量大语言模型(LLM)智能水平的众多方法中,除了常见的常识推理、专业领域测评外,还有一个正在兴起且极具挑战性的方向——算法问题求解。在这一领域,几乎没有哪项比赛能比 国际信息学奥林匹克(International Olympiad in Informatics,简称 IOI) 更具权威性与含金量。
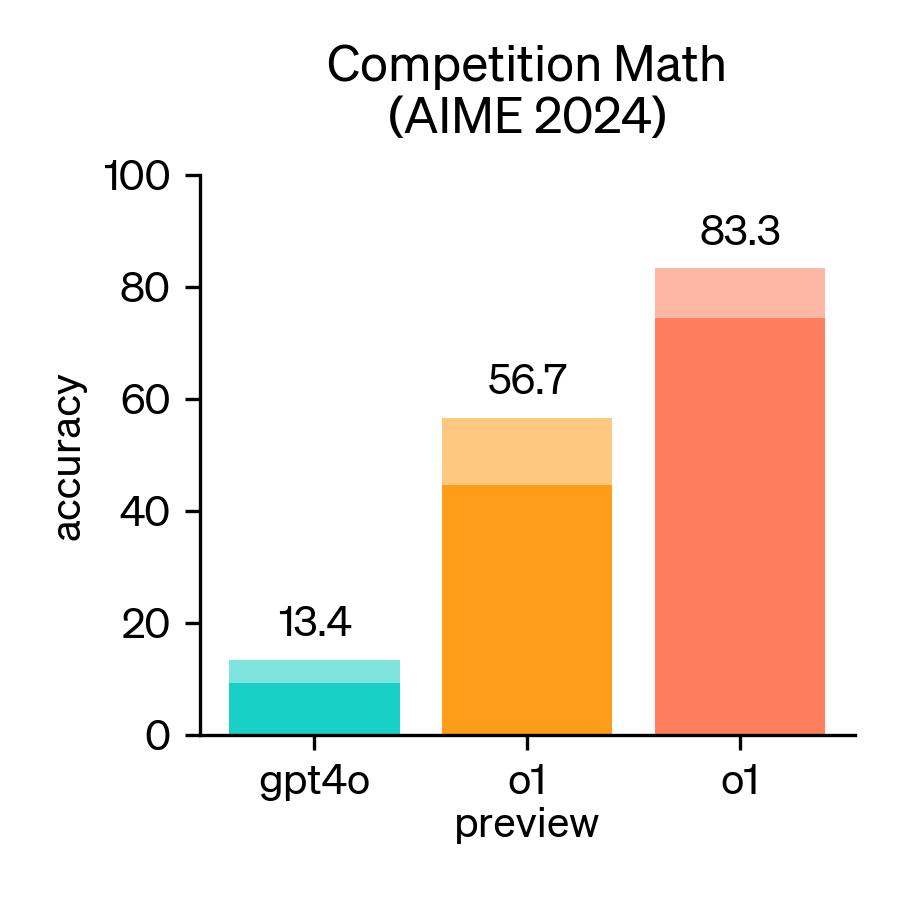
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。
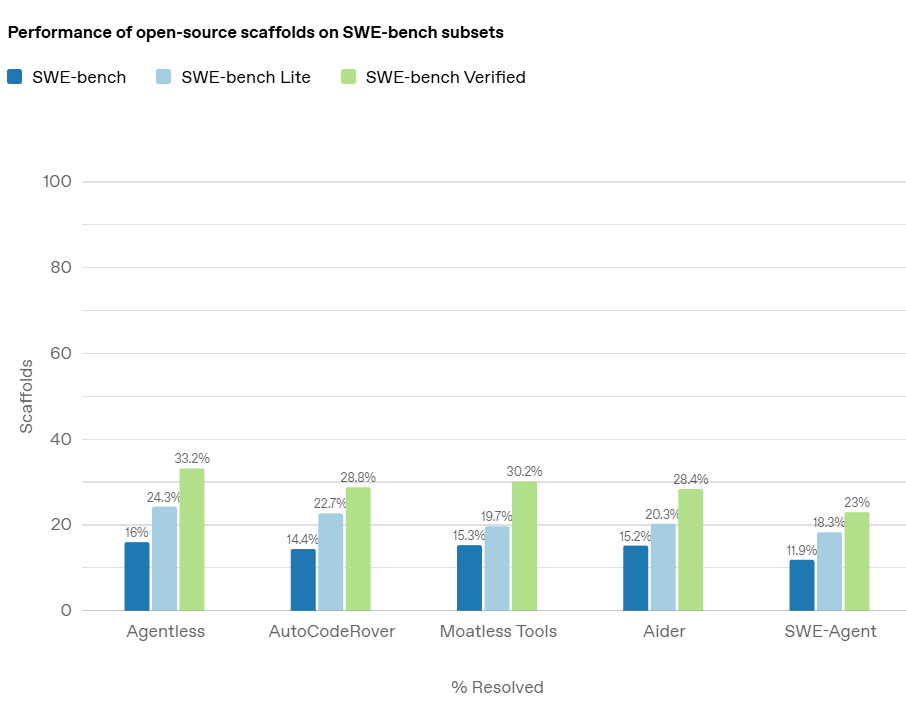
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
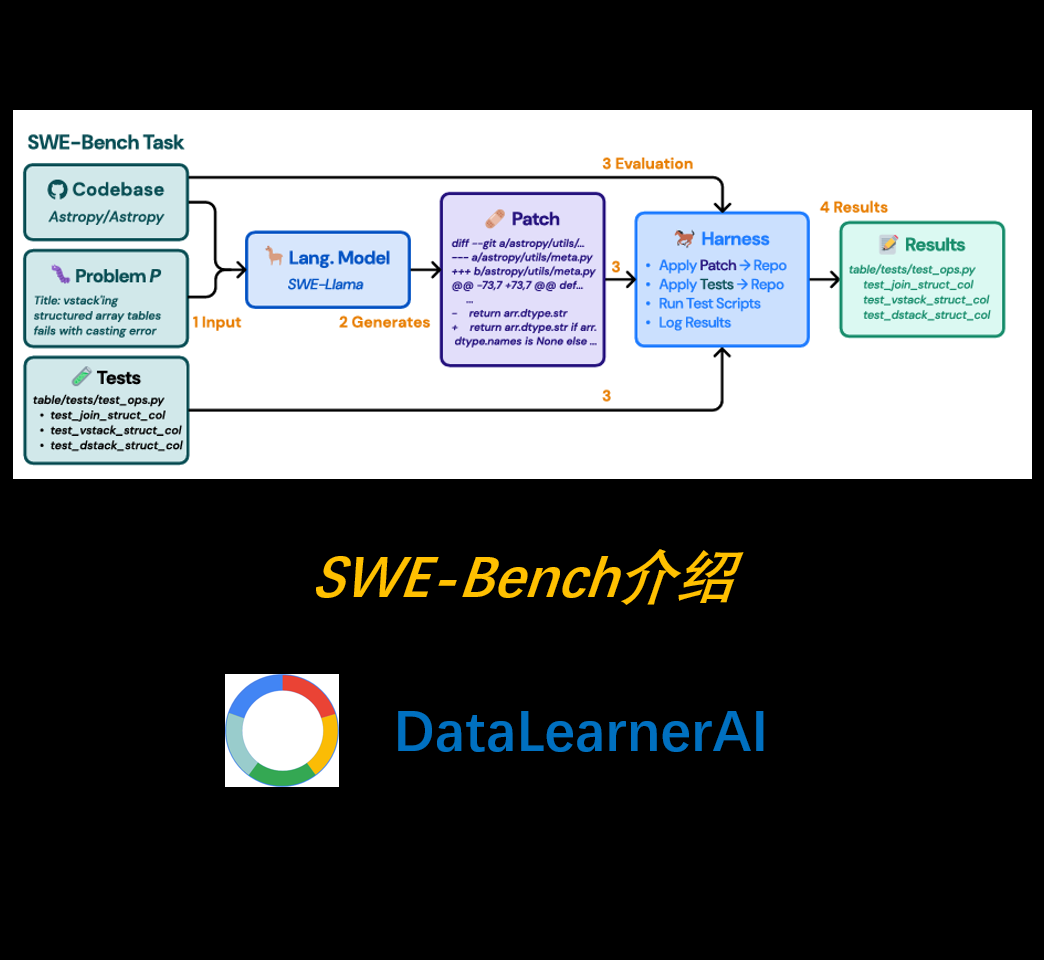
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。