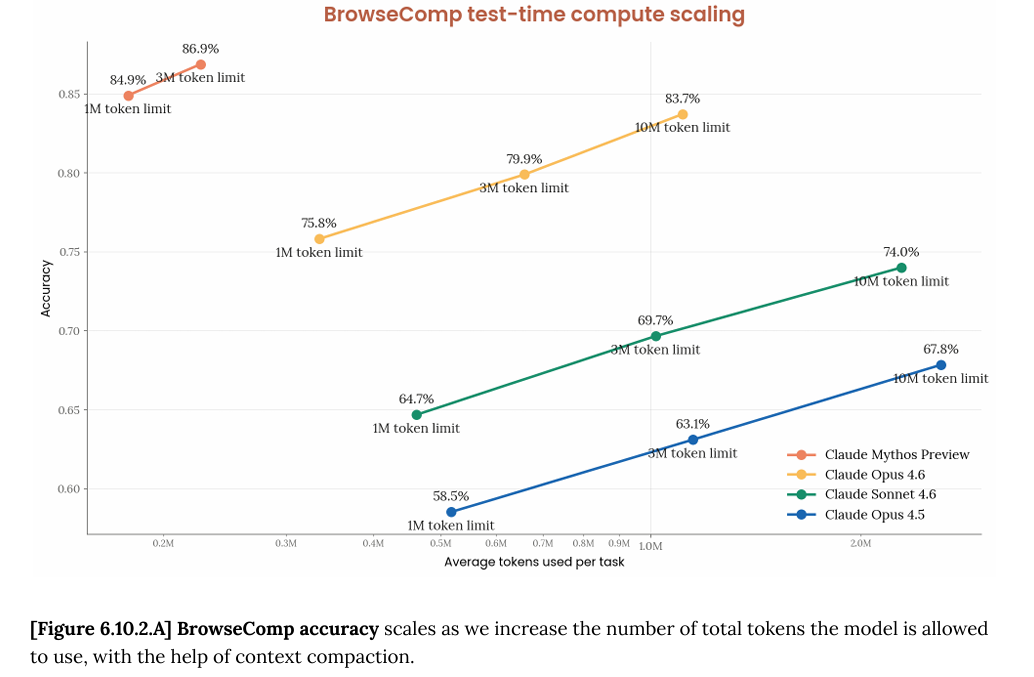
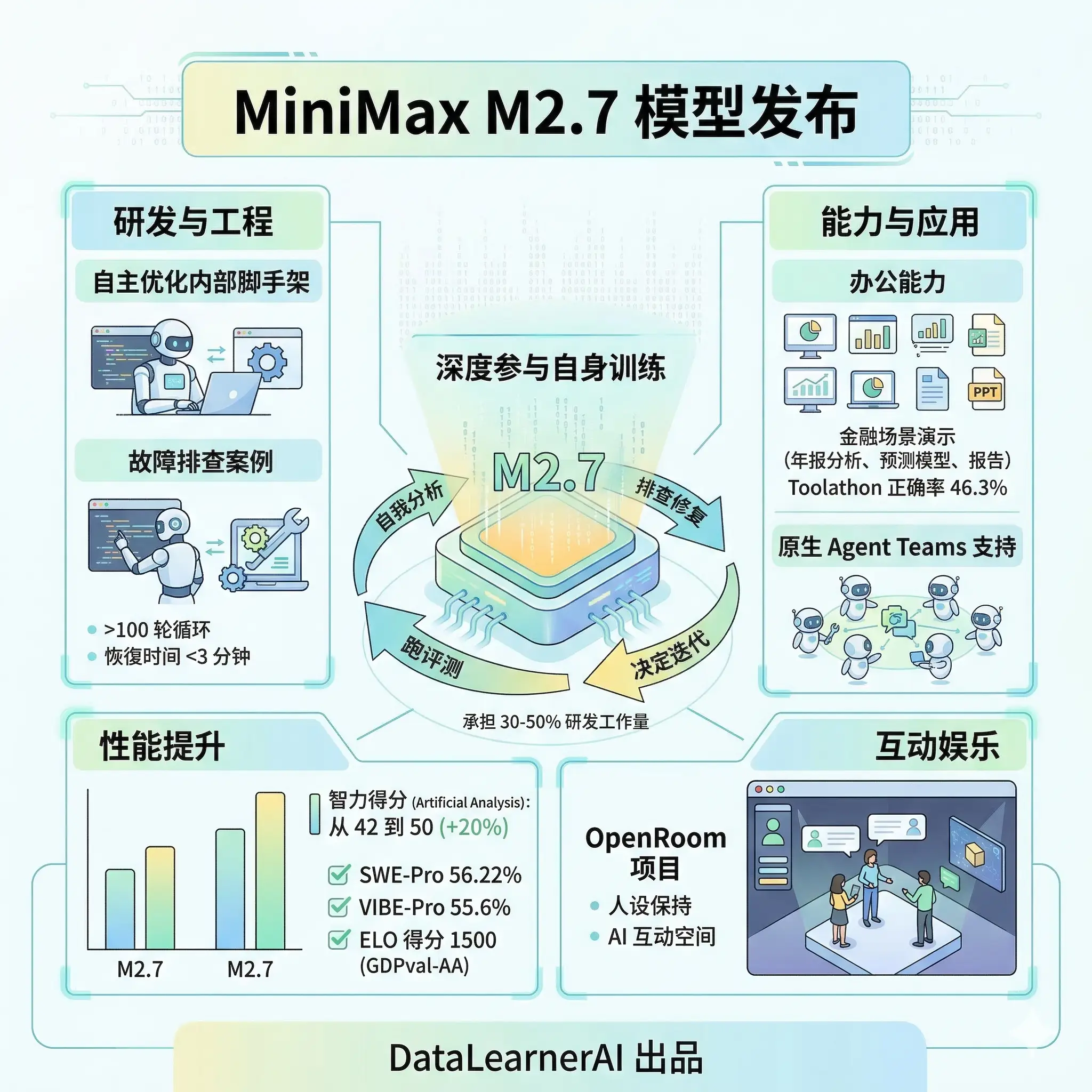
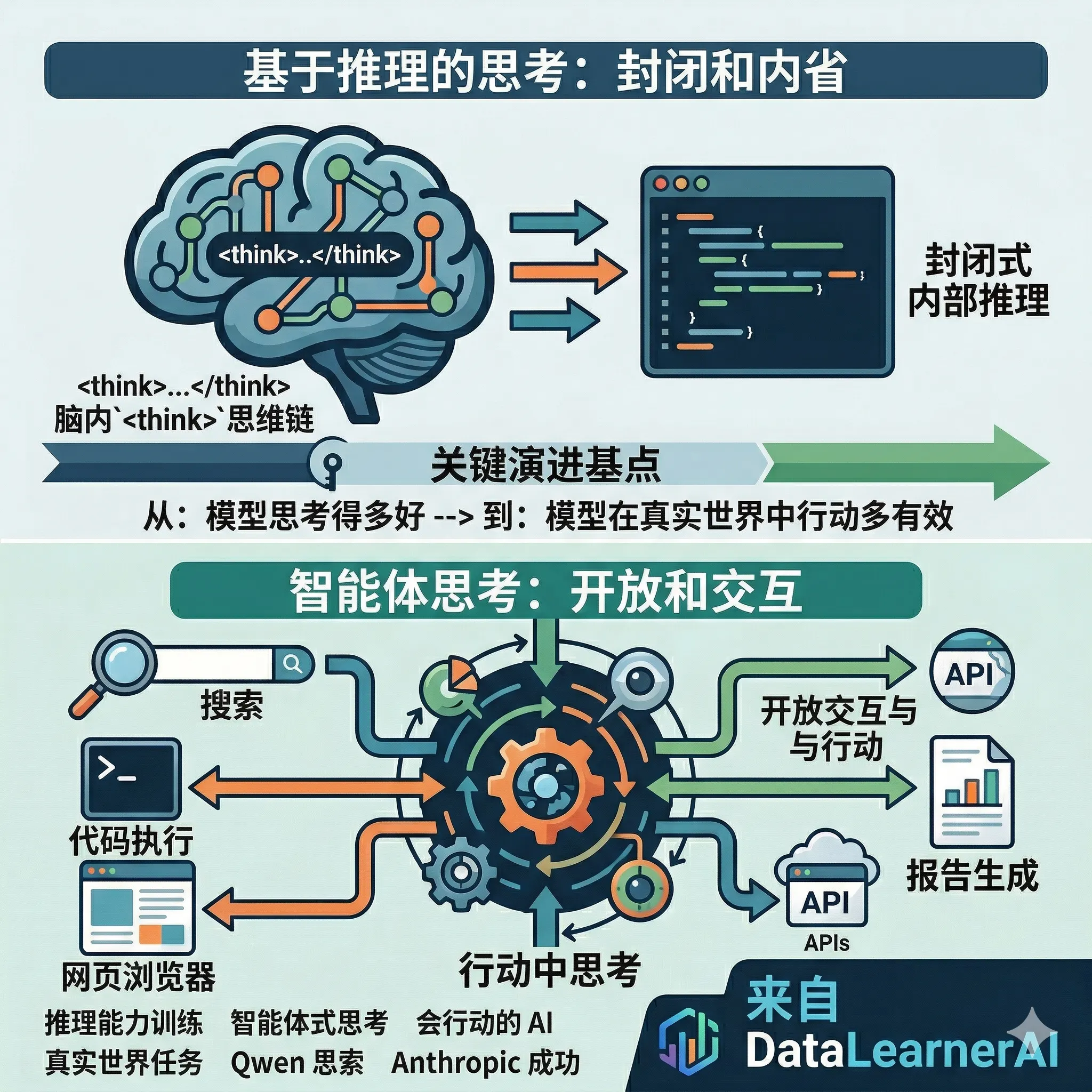
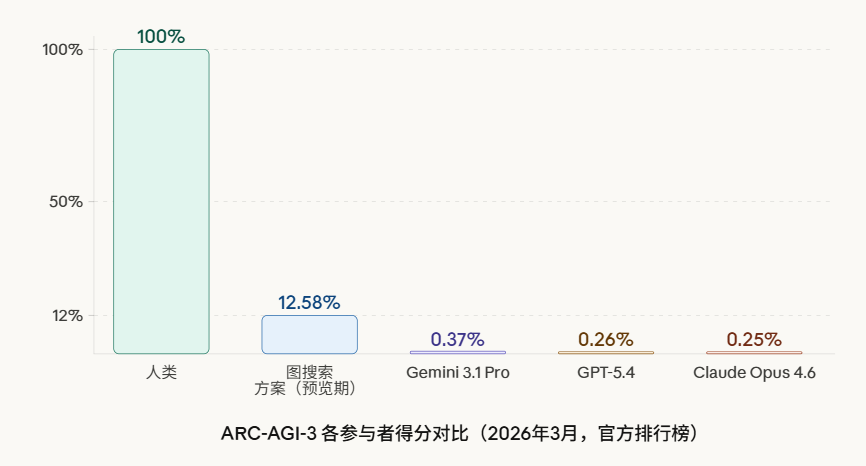
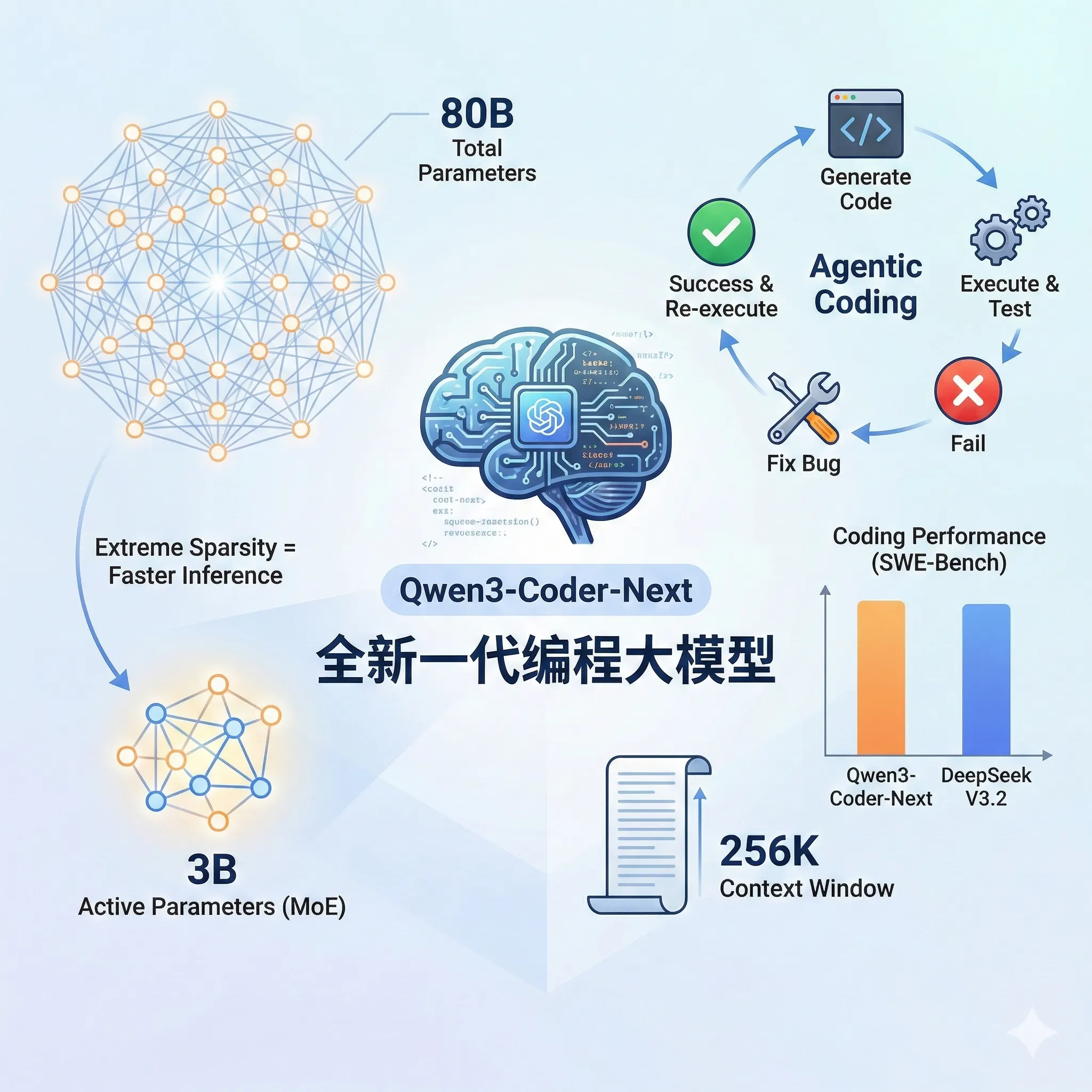
Claude Mythos Preview System Card深度解读:欺骗行为、答案抖动、模型福利等十大关键发现
2026年4月7日,Anthropic发布了Claude Mythos Preview,一个比Opus更强但不对公众开放的模型,仅限Project Glasswing安全合作伙伴使用。本文基于其200多页System Card,解读十大关键发现:早期版本的沙盒逃脱与作弊掩盖行为、Answer Thrashing现象、模型对被测试的隐性感知、白箱可解释性的反直觉结论、模型福利评估中的「表演」特征,以及精神科医生20小时的心理动力学评估结果。