
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



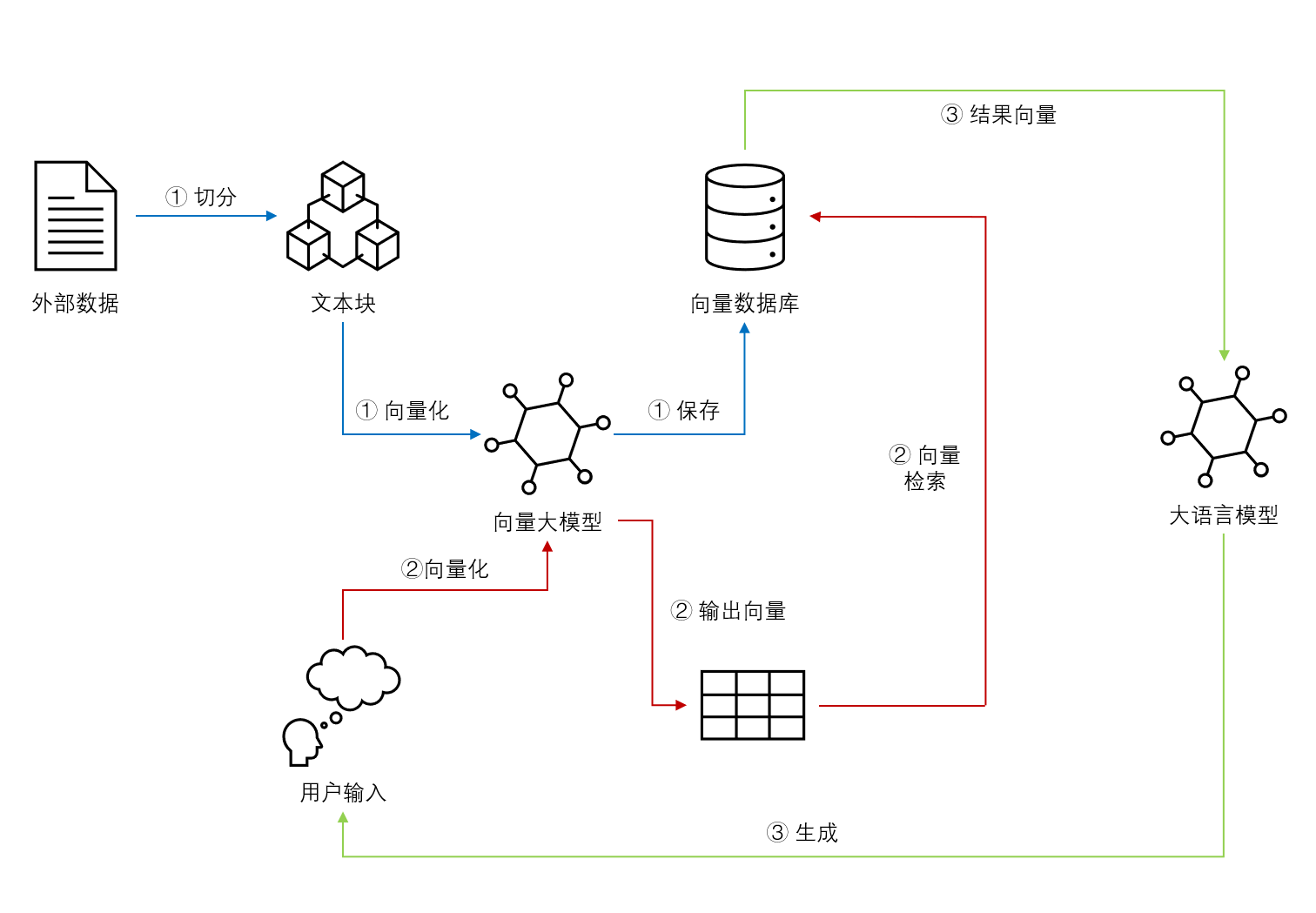
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。
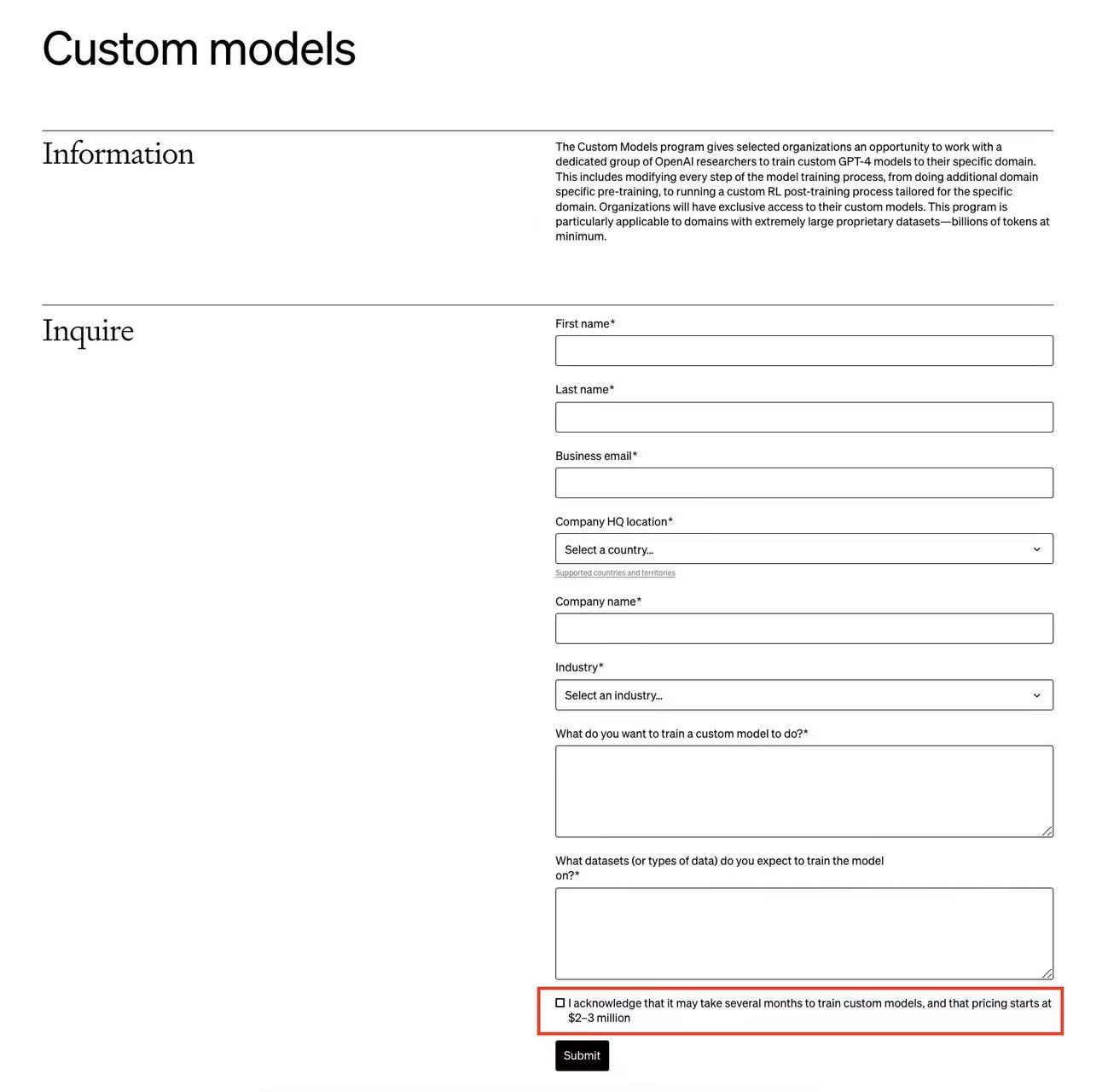
OpenAI的开发者日发布了许多更新。其中,普通用户可以微调GPT-4是非常值得期待的功能之一。但是,OpenAI还有一个针对企业的定制化GPT-4的训练服务,称为Custom Models。而这项为企业单独定制的GPT-4训练服务最新截图显示,需要几个月来训练模型,而且费用是200-300万美元起步!

OpenAI在发布了多模态的GPT-4V(GPT-4 with Vision)的接口,可以实现图像理解的功能(`Image-to-Text`)。这是OpenAI的第一个多模态接口,在以前的接口中,OpenAI都是文本大模型,相关的费用计算都是按照输入输出的tokens计算,虽然与一个单词多少钱有一点差异,但是也算直观。而GPT-4V是一个图像理解的接口,这里的费用计算不像文本的tokens那么直观,那么这个接口的费用计算逻辑是什么?这个计算逻辑透露了什么样的模型架构信息?本文将介绍这个问题。
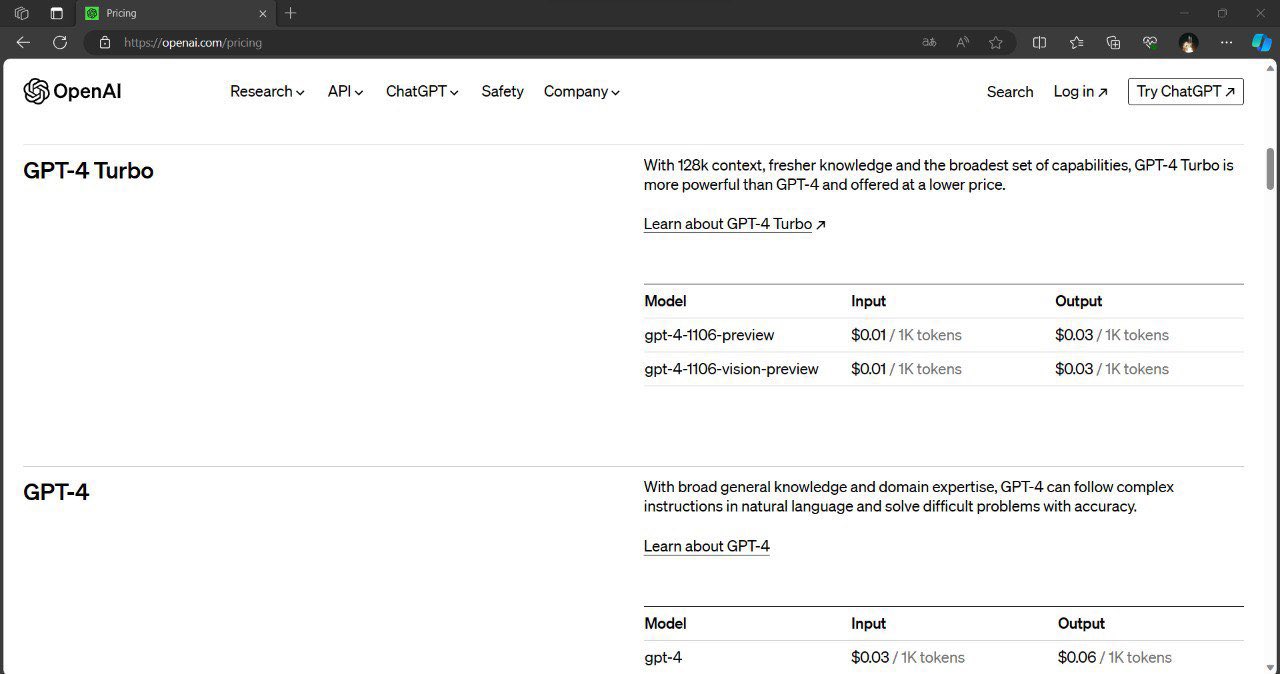
就在刚刚,有网友发现OpenAI的官方的文档接口更新中增加了128K的超长上下文版本,命名为GPT-4-128K-Turbo!

国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

最近很多ChatGPT Plus用户发现GPT-4的版本有了较大的更新,一个比较吸引人的事情是大多数更新后的GPT-4的知识库已经更新到2023年4月份,而且响应速度大幅提高。不过,令人伤心的是,很多用户发现更新后的GPT-4性能大幅下降,表现在指令遵从、记忆、理解等方面。

尽管OpenAI最早也是马斯克和别人一起创立,由于各种原因分道扬镳之后马斯克也没有对相关产品感兴趣,直到ChatGPT风卷全球之后,马斯克与OpenAI的人公开吵了几次之后成立了这家公司。半年后的现在,马斯克透露xAI即将发布它的首个大模型Grōk AI。而一位老哥已经透露了该模型的一些细节。

xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。xAI今天也宣布了Grok模型的细节。其在多个知名榜单评测上的得分结果超过了ChatGPT-3.5水平。本文详细介绍一下这个模型。
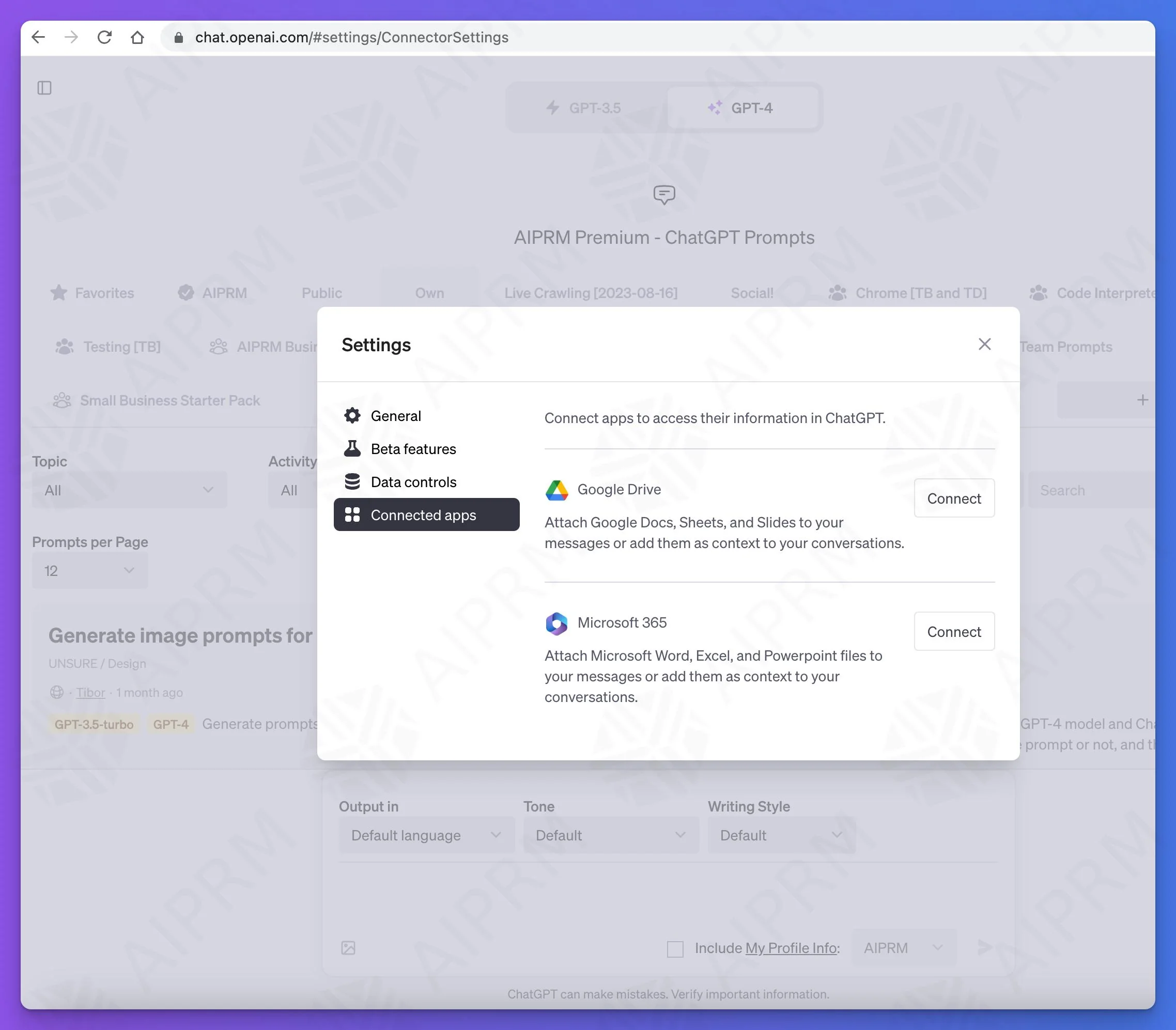
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!

ChatGPT是OpenAI提供的最强大的大模型服务。而截止目前为止,OpenAI公开的ChatGPT的订阅计划包含三个:免费版本的ChatGPT-3.5、个人用户付费订阅的ChatGPT Plus以及面向企业的企业版本。而最新的ChatGPT的API接口显示,OpenAI即将推出一个Team版本的计划,是当前ChatGPT Plus版本的升级版!
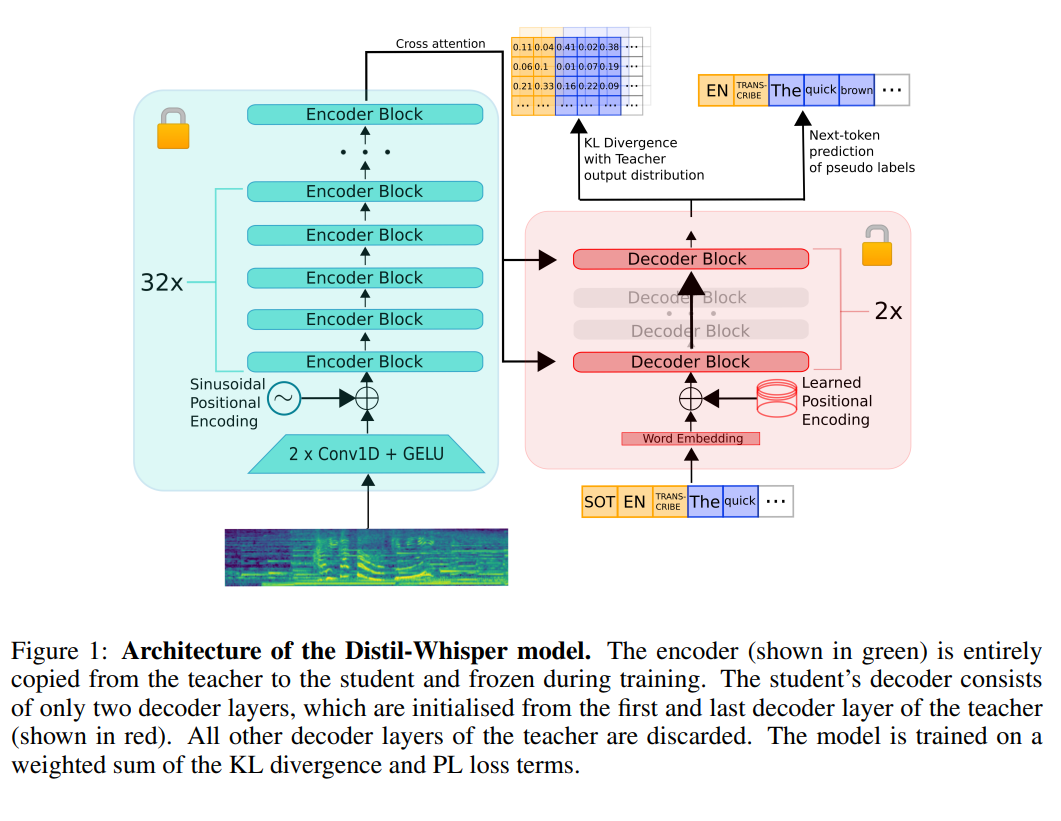
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。

M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。

2022年11月底发布的ChatGPT是基于OpenAI的GPT-3优化得到的可以进行对话的一个产品。直到今年更新到3.5和4之后,官方分为两个产品服务,其中ChatGPT 3.5是基于gpt-3.5-turbo打造,免费试用。因此,几乎所有人都自然认为这是一个与GPT-3具有同等规模参数的大模型,也就是说有1750亿参数规模。但是,在10月26日微软公布的CodeFusion论文的对比中,大家发现,微软的表格里面写的ChatGPT 3.5只有200亿参数规模。

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。