【转载】变分贝叶斯算法理解与推导
7,180 阅读
本文作者:huajh7 原文链接:http://blog.huajh7.com/2013/03/06/variational-bayes/ 转载已获授权
本文作者:huajh7 原文链接:http://blog.huajh7.com/2013/03/06/variational-bayes/ 转载已获授权
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送

上世纪90年代,变分推断在概率模型上得到迅速发展,在贝叶斯框架下一般的变分法由Attias的两篇文章给出。Matthew J.Beal的博士论文《Variational Algorithms for Approximate Bayesian Inference》中有比较充分地论述,作者将其应用于隐马尔科夫模型,混合因子分析,线性动力学,图模型等。变分贝叶斯是一类用于贝叶斯估计和机器学习领域中近似计算复杂(intractable)积分的技术。它主要应用于复杂的统计模型中,这种模型一般包括三类变量:观测变量(observed variables, data),未知参数(parameters)和潜变量(latent variables)。在贝叶斯推断中,参数和潜变量统称为不可观测变量(unobserved variables)。变分贝叶斯方法主要是两个目的:
对于第一个目的,蒙特卡洛模拟,特别是用Gibbs取样的MCMC方法,可以近似计算复杂的后验分布,能很好地应用到贝叶斯统计推断。此方法通过大量的样本估计真实的后验,因而近似结果带有一定的随机性。与此不同的是,变分贝叶斯方法提供一种局部最优,但具有确定解的近似后验方法。
从某种角度看,变分贝叶斯可以看做是EM算法的扩展,因为它也是采用极大后验估计(MAP),即用单个最有可能的参数值来代替完全贝叶斯估计。另外,变分贝叶斯也通过一组相互依然(mutually dependent)的等式进行不断的迭代来获得最优解。
重新考虑一个问题:1)有一组观测数据DD,并且已知模型的形式,求参数与潜变量(或不可观测变量)$Z={Z_1,...,Z_n}$的后验分布:$P(Z|D)$。
正如上文所描述的后验概率的形式通常是很复杂(Intractable)的,对于一种算法如果不能在多项式时间内求解,往往不是我们所考虑的。因而我们想能不能在误差允许的范围内,用更简单、容易理解(tractable)的数学形式$Q(Z)$来近似$P(Z|D)$,即 $P(Z|D)\approx Q(Z)$。
由此引出如下两个问题:
1、假设存在这样的$Q(Z)$,那么如何度量$Q(Z)$与$P(Z|D)$之间的差异性 (dissimilarity). 2、如何得到简单的$Q(Z)$?
对于问题一,幸运的是,我们不需要重新定义一个度量指标。在信息论中,已经存在描述两个随机分布之间距离的度量,即相对熵,或者称为Kullback-Leibler散度。
对于问题二,显然我们可以自主决定$Q(Z)$的分布,只要它足够简单,且与$P(Z|D)$接近。然而不可能每次都手工给出一个与$P(Z|D)$接近且简单的$Q(Z)$,其方法本身已经不具备可操作性。所以需要一种通用的形式帮助简化问题。那么数学形式复杂的原因是什么?在“模型的选择”部分,曾提到Occam’s razor,认为一个模型的参数个数越多,那么模型复杂的概率越大;此外,如果参数之间具有相互依赖关系(mutually dependent),那么通常很难对参数的边缘概率精确求解。
幸运的是,统计物理学界很早就关注了高维概率函数与它的简单形式,并发展了平均场理论。简单讲就是:系统中个体的局部相互作用可以产生宏观层面较为稳定的行为。于是我们可以作出后验条件独立(posterior independence)的假设。即
\forall _{i}p(Z|D)=p(Z_i|D)p(Z_{-i}|D)
在统计学中,相对熵对应的是似然比的对数期望,相对熵 $D(p||q)$ 度量当真实分布为 P而假定分布为Q时的无效性。
定义 两个概率密度函数为$p(x)$和$q(x)$之间的相对熵定义为
D_{KL}(p||q)=\sum_xp(x)log \frac{p(x)}{q(x)}
KL散度有如下性质:
D_{KL}(p||q)\neq D_{KL}(q||p)
D_{KL}(Q||P)=\sum_ZQ(Z)log \frac{Q(Z)}{P(Z|D)}=\sum_ZQ(Z)log\frac{Q(Z)}{P(Z,D)}+logP(D)
或者
\log P(D)=D_{KL}(Q||P)-\sum_ZQ(Z)\log \frac{Q(Z)}{P(Z,D)}=D_{KL}(Q||P)+L(Q).
由于对数证据$\log P(D)$被相应的Q所固定,为了使KL散度最小,则只要极大化$L(Q)$。通过选择合适的Q,使$L(Q)$便于计算和求极值。这样就可以得到后验$P(Z|D)$的近似解析表达式和证据(log evidence)的下界$L(Q)$,又称为变分自由能(variational free energy):
L(Q)=\sum_ZQ(Z)logP(Z,D)-\sum_Z Q(Z)\log Q(Z)=E_Q[\log P(Z,D)]+H(Q)

数学上说,平均场的适用范围只能是完全图,或者说系统结构是well-mixed,在这种情况下,系统中的任何一个个体以等可能接触其他个体。反观物理,平均场与其说是一种方法,不如说是一种思想。其实统计物理的研究目的就是期望对宏观的热力学现象给予合理的微观理论。物理学家坚信,即便不满足完全图的假设,但既然这种“局部”到“整体”的作用得以实现,那么个体之间的局部作用相较于“全局”的作用是可以忽略不计的。
根据平均场理论,变分分布Q(Z)可以通过参数和潜在变量的划分(partition)因式分解,比如将ZZ划分为Z1…ZM
Q(Z) = \prod\limits_{i = 1}^M {q(Z_i \vert D)}
注意这里并非一个不可观测变量一个划分,而应该根据实际情况做决定。当然你也可以这么做,但是有时候,将几个潜变量放在一起会更容易处理。
在量子多体问题中,用一个(单体)有效场来代替电子所受到的其他电子的库仑相互作用。这个有效场包含所有其他电受到的其他电子的库仑相互作用。这个有效场包含了所有其他电子对该电子的相互作用。利用有效场取代电子之间的库仑相互作用之后,每一个电子在一个有效场中运动,电子与电子之间的运动是独立的(除了需要考虑泡利不相容原理),原来的多体问题转化为单体问题。
同样在变分分布Q(Z)这个系统中,我们也可以将每一个潜变量划分看成是一个单体,其他划分对其的影响都可以用一个看做是其自身的作用。采用的办法是迭代(Iterative VB(IVB) algorithm)。这是由于当变分自由能取得最大值的时候,划分$Z_i$与它的互斥集$Z_-i$(或者更进一步,马尔科夫毯(Markov blanket),$mb(Zi))$具有一个简单的关系:
Q(Z_i) \propto \frac{1}{C}\exp {\left\langle {\ln P(Z_i,{Z_{-i}},D)} \right\rangle _{Q({Z_{-i}}) or Q(mb(Z_i))}}
(为保持文章的连贯性,此处先不证明,下文将详细说明)
于是,对于某个划分$Z_i$,我们可以先保持其他划分$Z_-i$不变,然后用以上关系式更新$Z_i$。相同步骤应用于其他划分的更新,使得每个划分之间充分相互作用,最终达到稳定值。
具体更新边缘概率(VB-marginal)步骤如下:
1、初始化${Q^{(0)}}(Z_i)$,可随机取; 2、在第k步,计算Z−iZ−i的边缘密度$Q^{[k]}({Z_{-i}} \vert D) \propto \exp \int\limits_{Z_i^*} Q^{[k - 1]}(Z_i \vert D) \log P(Z_i,Z_{-i},D)dZ_i$ 3、计算ZiZi的边缘密度$Q^{[k]}(Z_i \vert D) \propto \exp \int\limits_{Z_{-i}^*} Q^{[k]}({Z_{-i}} \vert D) \log P(Z_i,{Z_{-i}},D)d{Z_{-i}}$ 4、理论上${Q^{[\infty ]}}(Z_i \vert D)$将会收敛,则反复执行(2), (3)直到Q(Zi)Q(Zi),Q(Z−i)Q(Z−i)稳定,或稳定在某个小范围内。 5、最后,得$Q(Z) = Q(Z_i \vert D)Q({Z_{-i}} \vert D)$
注意到$Q(Z)$估计的是联合概率密度,而对于每一个$Q_i(Z_i)$,其与真实的边缘概率密度$P_i(Z_i)$的差别可能是很大的。不应该用Qi(Zi)Qi(Zi)来估计真实的边缘密度,比如在一个贝叶斯网络中,你不应该用它来推测某个节点的状态。而这其实是很糟糕的,相比于其他能够使用节点状态信息来进行局部推测的算法,变分贝叶斯方法更不利于调试。
比如一个标准的高斯联合分布$P(\mu,x)$和最优的平均场高斯估计$Q(\mu,x)$。Q选择了在它自己作用域中的高斯分布,因而变得很窄。此时边缘密度$Q_x(x)$变得非常小,完全与$P_x(x)$不同。

上文已经提到我们要找到一个更加简单的函数D(Z)D(Z)来近似P(Z|D)P(Z|D),同时问题转化为求解证据logP(Z)logP(Z)的下界L(Q)L(Q),或者L(Q(Z))L(Q(Z))。应该注意到L(Q)L(Q)并非普通的函数,而是以整个函数为自变量的函数,这便是泛函。我们先介绍一下什么是泛函,以及泛函取得极值的必要条件。
设对于(某一函数集合内的)任意一个函数$y(x)$,有另一个数$J[y]$与之对应,则称$J[y]$为$y(x)$的泛函。泛函可以看成是函数概念的推广。 这里的函数集合,即泛函的定义域,通常要求y(x)y(x) 满足一定的边界条件,并且具有连续的二阶导数.这样的$y(x)$称为可取函数。
泛函不同于复合函数,
例如$g=g(f(x))$; 对于后者,给定一个$x$值,仍然是有一个gg值与之对应; 对于前者,则必须给出某一区间上的函数$y(x)$,才能得到一个泛函值$J[y]$。(定义在同一区间上的)函数不同,泛函值当然不同, 为了强调泛函值$J[y]$与函数$y(x)$之间的依赖关系,常常又把函数$y(x)$称为变量函数。 泛函的形式多种多样,通常可以积分形式:$J[y] = \int_{x_0}^{x_1}F(x,y,y`)dx$
“当变量函数为$y(x)$时,泛函$J[y]$取极大值”的含义就是:对于极值函数$y(x)$及其“附近”的变量函数$y(x) + \delta y(x)$,恒有$J\left[ {y + \delta y} \right] \le J[y]$;
所谓函数$y(x) + \delta y(x)$在另一个函数$y(x)$的“附近”,指的是:
$\vert \delta y(x) \vert < \varepsilon $; 有时还要求$\vert (\delta y)` (x) \vert < \varepsilon $. 这里的$\delta y(x)$称为函数$y(x)$的变分。
可以仿造函数极值必要条件的导出办法,导出泛函取极值的必要条件,这里不做严格的证明,直接给出。 泛函J[y]J[y]取到极大值的必要条件是一级变分δJ[y]δJ[y]为0,其微分形式一般为二阶常微分方程,即Euler-Largange方程:
\frac{\partial F}\partial y - \frac{d}dx\frac{\partial F}\partial y' = 0
在约束条件 下求函数J[y]J[y]的极值,可以引入Largange乘子λλ,从而定义一个新的泛函, J~[y]=J[y]−λJ0[y]J~[y]=J[y]−λJ0[y]。仍将δyδy看成是独立的,则泛函J~[y]J~[y]在边界条件下取极值的必要条件就是,
(\frac{\partial}{\partial y} - \frac{d}{dx} \frac{\partial}{\partial y'})
(F - \lambda G) = 0
对于$L(Q(Z)) = {E_Q(Z)}[\ln P(Z,D)] + H(Q(Z))$,将右式第一项定义为能量(Energy),第二项看做是信息熵(Shannon entropy)。我们只考虑自然对数的形式,因为对于任何底数的对数总是可以通过换底公式将其写成自然对数与一个常量的乘积形式。另外根据平均场假设可以得到如下积分形式,
L(Q(Z)) = \int {(\prod\limits_i {Q_i(Z_i)})} \ln P(Z,D)dZ - \int {(\prod\limits_k {Q_k({Z_k})} )} \sum\limits_i {\ln Q_i(Z_i)} dZ
其中$Q(Z)=\prod_i {Q_i(Z_i)}$,且满足 $\forall i$, $\int {Q_i(Z_i)} dZ_i = 1$ 考虑划分$Z=\{Z_i,{Z_{-i}}\}$,其中$Z_{-i} = Z\backslash Z_i$,先考虑能量项(Energy)(第一项),
\begin{aligned}
{E_Q(Z)}[\ln P(Z,D)] & = \int {(\prod\limits_i {Q_i(Z_i)} )} \ln P(Z, D)dZ\\
& =\int Q_i(Z_i)dZ_i\int Q_{-i}({Z_{-i}})\ln P(Z, D)d{Z_{-i}}\\
& =\int Q_i(Z_i){\left\langle \ln P(Z, D) \right\rangle }_{Q_{-i}(Z_{-i})}dZ_i\\
& =\int Q_i(Z_i)\ln \exp { \left\langle {\ln P(Z,D)} \right\rangle }_{Q_{-i}({Z_{-i}})} dZ_i \\
& =\int Q_i(Z_i) \ln Q_i^*(Z_i) dZ_i + \ln C \\
\end{aligned}
其中定义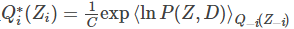
\begin{aligned}
H(Q(Z))
& = -\sum\limits_i {\int {(\prod\limits_k {Q_k({Z_k})} )} \ln Q_i(Z_i)dZ} \\
& =-\sum\limits_i {\int {\int {Q_i(Z_i)Q_{-i}({Z_{-i}})\ln Q_i(Z_i dZ_id{Z_{-i}}} } }\\
& =-{\sum\limits_i {\left\langle {\int {Q_i(Z_i)\ln Q_i(Z_i)dZ_i} } \right\rangle } _{Q_{-i}({Z_{-i}})}} \\
& =-\sum\limits_i \int Q_i(Z_i)\ln Q_i(Z_i)dZ_i
\end{aligned}
此时得到泛函,
\begin{aligned}
L(Q(Z))&=\int Q_i(Z_i)\ln Q_i^*(Z_i) dZ_i-\sum_i \int Q_i(Z_i) \ln Q_i(Z_i)dZ_i + \ln C \\
& = (\int Q_i(Z_i)\ln Q_i^*(Z_i) dZ_i - \int Q_i(Z_i)\ln Q_i(Z_i)dZ_i )-\sum_{k \neq i} \int Q_k({Z_k})\ln Q_k({Z_k})d{Z_k} + \ln C\\
& =\int Q_i(Z_i)\ln \frac{Q_i^*(Z_i)}{Q_i(Z_i)} dZ_i-\sum\limits_{k \ne i} \int Q_k({Z_k})\ln Q_k({Z_k})d{Z_k} +\ln C\\
& = - {D_{KL}}(Q_i(Z_i) \vert \vert Q_i^*(Z_i)) + H[Q_{-i}({Z_{-i}})] + \ln C
\end{aligned}
注意到$L(Q(Z))$并非只有一个等式,如果不可观测变量有M个划分。 那么将有M个方程。 为了使得$L(Q(Z))$达到最大值, 同时注意到约束条件, 根据泛函求条件极值的必要条件, 得,
\forall i. \frac{\partial}{\partial Q_i(Z_i)} \{- {D_{KL}}[Q_i(Z_i) \vert \vert Q_i^*(Z_i)] - {\lambda _i}(\int {Q_i(Z_i)} dZ_i - 1)\} : = 0
直接求解将得到Gibbs分布,略显复杂;实际上,注意到KL散度,我们可以直接得到KL散度等于0的时候,L(D)L(D)达到最大值,最终得到
Q_i(Z_i) = Q_i^*(Z_i) = \frac{1}{C}\exp \left\langle \ln P(Z_i,{Z_{-i}},D) \right\rangle _{Q_{-i}({Z_{-i}})}
$C$为归一化常数$C = \int \exp \left\langle {\ln (Z_i,{Z_{-i}},D)} \right\rangle_{Q_{-i}({Z_{-i}})} d Z_{-i}$为联合概率函数在除ZiZi本身外的其他划分下的对数期望。又可以写为 $\ln Q_i(Z_i) = {\left\langle {\ln P(Z_i,{Z_{-i}},D)} \right\rangle_{Q_{-i}({Z_{-i}})}} + const$.
[1] Smídl, Václav, and Anthony Quinn. The variational Bayes method in signal processing. Springer, 2006.
[2] Beal, Matthew James. Variational algorithms for approximate Bayesian inference. Diss. University of London, 2003.
[3] Fox, Charles W., and Stephen J. Roberts. “A tutorial on variational Bayesian inference.” Artificial Intelligence Review 38.2 (2012): 85-95.
[4] Attias, Hagai. “Inferring parameters and structure of latent variable models by variational Bayes.” Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 1999.
[5] Attias, Hagai. “A variational Bayesian framework for graphical models.”Advances in neural information processing systems 12.1-2 (2000): 209-215.