深度学习之LSTM模型
9,748 阅读
加载中...
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送

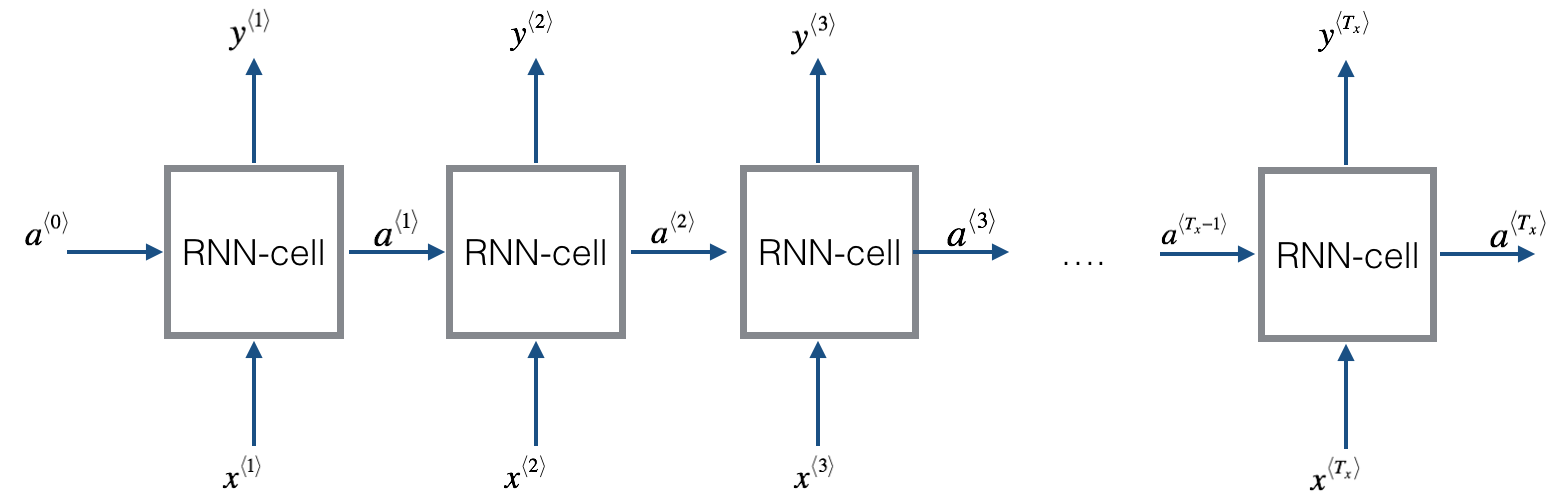
RNN模型中CELL的计算:
a^{< t>} = g(W_a [a^{< t-1>},x^{< t>}] + b_a)
\hat{y}^{< t>} = g(W_y a^{< t>} + b_y)
而GRU网络中CELL的计算如下:
\tilde{c}^{< t>} = \text{tanh}(W_c[\Gamma_r\times c^{< t-1>},x^{< t>}] + b_c)
\Gamma_u = \sigma(W_u[c^{< t-1>},x^{< t>}] + b_u)
\Gamma_r = \sigma(W_r[c^{< t-1>},x^{< t>}] + b_r)
c^{< t>} = \Gamma_u \times \tilde{c}^{< t>} + (1-\Gamma_u)
\times c^{< t-1>}
\hat{y}^{< t>} = g(W_y c^{< t>} + b_y)
注意到,GRU的状态变量$c^{< t>}=a^{< t>}$,这两个是一样的。GRU模型中包含了两个门,一个是更新门$\Gamma_u$,一个是重置门$\Gamma_r$,他们共同决定了状态变量是重新计算还是使用前一阶段的结果。
而LSTM模型比GRU参数更多,它包含了三个门,即“更新门”、“遗忘门”和“输出门”,其计算如下:
\tilde{c}^{< t>} = \text{tanh}(W_c[\Gamma_r\times a^{< t-1>},x^{< t>}] + b_c)
\Gamma_u = \sigma(W_u[a^{< t-1>},x^{< t>}] + b_u)
\Gamma_f = \sigma(W_r[a^{< t-1>},x^{< t>}] + b_f)
\Gamma_o = \sigma(W_r[a^{< t-1>},x^{< t>}] + b_o)
c^{< t>} = \Gamma_u \times \tilde{c}^{< t>} + \Gamma_f
\times c^{< t-1>}
a^{< t>} = \Gamma_o \times \text{tanh}\space\space c^{< t>}
\hat{y}^{< t>} = g(W_y a^{< t>} + b_y)
可以看到,LSTM多了一个状态变量$c^{< t>}$,GRU中$c^{< t>}=a^{< t>}$,而LSTM中$c^{< t>}$是由更新门$\Gamma_u$和遗忘门$\Gamma_f$决定,它的结果和输出门$\Gamma_o$一起,决定了最终的状态变量的输出。
LSTM的网络示意图如下:

可以看到,LSTM内部的参数更多,因此也更加强大。在深度学习历史中,LSTM模型比GRU出来的更早,GRU是LSTM的一个简化版本。在某些任务中,GRU也取得了和LSTM类似的效果,但是LSTM要更好点。尽管如此,GRU的参数更少,运算速度更快,因此容易构造更大的网络。现实中,首选LSTM模型的人要多一些。