隐马尔科夫模型及其在NLP中的应用指南
本篇博客解释了隐马尔科夫模型以及其实现方式,原文来自analyticsindiamag.com的博客。本篇属于翻译内容。
隐马尔可夫模型(HMM)是一种统计模型,也用于机器学习。它可以用来描述取决于内部因素的可观察事件的演变,而这些因素是无法直接观察到的。这是一类概率图形模型,允许我们从一组观察到的变量中预测一串未知的变量。在这篇文章中,我们将详细讨论隐马尔可夫模型。我们将了解它可以使用的背景,我们也将讨论它的不同应用。我们还将讨论HMM在PoS标签中的使用和python的实现。文章中所涉及的主要内容如下。
隐马尔科夫模型
隐马尔科夫模型是一种概率模型,用于解释或推导任何随机过程的概率特征。它基本上说,一个观察到的事件不会与它的步骤状态相对应,而是与一组概率分布相关。让我们假设一个被建模的系统被假定为马尔可夫链,在这个过程中,有一些隐藏状态。在这种情况下,我们可以说,隐藏状态是一个取决于主马尔可夫过程/链的过程。
HMM的主要目标是通过观察马尔可夫链的隐藏状态来了解它。考虑到一个带有隐藏状态Y的马尔可夫过程,HMM证实了对于每个时间戳,Y的概率分布必须不依赖于根据该时间的X的历史。
隐马尔科夫模型与实例
为了进一步解释它,我们可以举两个朋友的例子,Rahul和Ashok。现在拉胡尔根据天气情况完成他的日常生活工作。拉胡尔完成的主要三项活动是:慢跑、去办公室和打扫他的住所。拉胡尔今天做什么取决于拉胡尔是否告诉阿肖克,阿肖克没有关于天气的适当信息,但阿肖克可以根据拉胡尔的工作情况来判断天气状况。
阿肖克认为,天气是一个离散的马尔可夫链,在这个链中只有两种状态,即天气是下雨还是晴天。阿肖克无法观察到天气的状况,这里的天气状况对阿肖克来说是隐藏的。在每一天,鲍勃都有一定的机会从以下活动集合{"慢跑"、"工作"、"清洁"}中执行一项活动,这取决于天气情况。由于Rahul告诉Ashok他做了什么,这些就是观察结果。整个系统是一个隐马尔可夫模型(HMM)。
这里我们可以说HMM的参数对阿肖克来说是已知的,因为他有关于天气的一般信息,他也知道拉胡尔平均喜欢做什么。
因此,让我们考虑有一天,Rahul给Ashok打电话,告诉他他已经打扫了他的住所。在这种情况下,Ashok会认为下雨天的机会更多,我们可以说Ashok的信念是HMM的起始概率,就像下面这样。
这些状态和观察结果如下:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
初始概率为:
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
现在,概率的分布在美国本土的雨天有更大的权重,所以我们可以说,有一天会有更多的机会再次下雨,第二天的天气状态的概率如下:
transition_probability = {
'Rainy': {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny': {'Rainy': 0.4, 'Sunny': 0.6},
}
从上面我们可以说,一天的概率变化是输出概率,根据输出概率,Rahul将执行的工作概率的结果是
emission_probability = {
'Rainy': {'jog': 0.1, 'work': 0.4, 'clean': 0.5},
'Sunny': {'jog': 0.6, 'work: 0.3, 'clean': 0.1},
}
这个概率可以被看作是输出概率。使用输出概率,Ashok可以预测天气的状态,或者使用输出概率,Ashok可以预测Rahul第二天要做的工作。
下面的图片显示了HMM创建概率的过程:
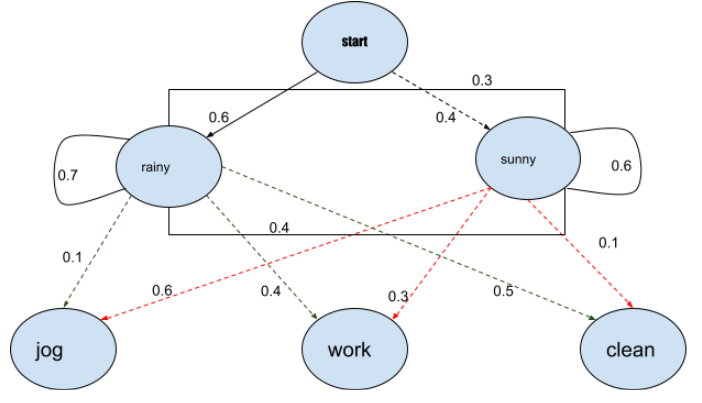
所以在这里,从上面的直觉和例子中我们可以理解我们如何使用这个概率模型来进行预测。现在我们就来讨论一下可以使用它的应用。
隐马尔可夫模型的应用
使用HMM的应用旨在恢复数据序列,其中下一个数据序列不能立即被观察到,但下一个数据取决于旧的序列。考虑到上述直觉,HMM可用于以下应用。
- 计算金融
- 速度分析
- 语音识别
- 语音合成
- 语音部分标记
- 扫描解决方案中的文件分离
- 机器翻译
- 手写识别
- 时间序列分析
- 活动识别
- 序列分类
- 运输预测
隐马尔可夫模型在NLP中的应用
从以上HMM的应用中,我们可以了解到,可以使用HMM的应用有连续的数据,如时间序列数据、音频和视频数据,以及文本数据或NLP数据。在这篇文章中,我们主要关注的是NLP的那些应用,在这些应用中,我们可以使用HMM来提高模型的性能,在上面给出的列表中,我们可以看到HMM的应用之一是我们可以将其用于语料部分标记。在接下来的文章中,我们将看到我们如何使用HMM进行POS标记。
什么是POS标记?
我们在学校的时候就已经知道,语篇表示任何一个词的功能,比如它在任何一个句子中的含义。通常有九个语篇;名词、代词、动词、副词、冠词、形容词、介词、连词、感叹词,一个词需要被纳入适当的语篇才能在句子中产生意义。
POS标签是NLP中文本预处理的一个非常有用的部分,因为我们知道NLP是一项任务,我们使机器能够与人类或不同的机器沟通。因此,对机器来说,理解语篇是必须的。
将单词按其语篇进行分类,并根据其语篇提供标签,这叫做语篇标签或POS标签或POST。 因此,标签/标记的集合被称为标签集。在这篇文章中,我们已经看到了如何使用NLTK在初级阶段实现语音部分,其中NLTK的标签集包帮助我们为我们的文档提供语音部分标签。
用隐马尔可夫模型进行POS标记
我们可以说,在HMM的情况下,是一种用于POS标签的随机技术。让我们举个例子来更清楚地说明HMM是如何帮助为一个句子选择一个准确的POS标签的。
正如我们在POS标签的HMM过程的例子中所看到的,过渡概率是任何序列的可能性,例如,一个名词出现在任何情态词之后,一个情态词出现在动词之后,一个动词出现在名词之后的可能性有多大。
让我们来看看 "Rahul将吃食物 "这个句子,Rahul是一个名词,will是一个情态词,eat是一个动词,food也是一个名词,所以一个词出现在一个特定的语篇类别中的概率被称为Emission概率。
让我们来看看如何计算一组句子的这两个概率。
- 玛丽-简可以看到将
- 斑会看到玛丽
- 简会发现玛丽吗?
- 玛丽会拍打斑点
下表是一个带有语篇类型的单词的计数表:

让我们把每个词的出现次数除以这组句子中每个语篇的总次数。

在这个表中,我们可以看到每个词的输出概率。
现在,我们已经讨论过,过渡概率是序列的概率,我们可以根据语篇的顺序为上述一组句子定义一个表格。

现在在表格中,我们需要检查说话部分的组合,以计算出过渡概率。例如,我们可以看到在这组句子中,动词前的语气词出现了3次,名词前出现了1次。这意味着它在这组句子中出现了4次,在任何动词前出现语气词的概率为3/4,在名词前出现的概率为1/4。同样地,对表中的每一个实体都这样做。

这里,表中的上述数值是给定的一组句子各自的过渡值。
让我们从这组句子中取出 "简会发现玛丽吗?",现在我们可以用上述计算方法来计算每个语篇的概率。

在上图中,我们可以看到,垂直线中给出了句子中单词的排放概率,水平线代表所有的过渡概率。
现在,POS标签的正确性是由所有这些概率的乘积来衡量的。概率的乘积代表序列正确的可能性。
让我们来检查一下POS标记的正确性。
1/4 × 3/4 × 3/4 × 2/9 × 1/1 × 1/4 × 1/9 × 4/9 × 4/9 = 0.0001714678
在这里我们可以看到,乘积大于零,这意味着我们所进行的POS标记是正确的,如果结果是零,那么所进行的标记将是不正确的。
所以在这里我们看到了HMM算法是如何为句子提供POS标签的,但这个例子很小,我们只有3种POS标签,但有81种不同的POS标签可用。当涉及到从一个小的数据集中寻找组合的数量时,可以用较小的努力来完成,但当涉及到对较大的句子进行标记并找到所有81种标签的正确序列时,组合的数量就会成指数增长。计算可能会造成较大的影响,但更多的POS标签数量会带来更多的准确性。
为了优化用于POS标签的HMM的实现,我们可以使用维特比算法,这是一种动态编程算法。使用这种算法,我们可以获得最可能的隐藏状态序列的最大后验概率估计。特别是在HMM的背景下。关于该算法的更多细节,你可以在这个链接上查看。
用Python实现
考虑到文章的篇幅,我只发布了我使用维特比算法实现和优化HMM的结果和步骤。读者可以通过这个链接获取代码。
为了实现,我使用了NLTK提供的Treebank数据集,并使用NLTK的universal_tagset包对其进行了标记。
下面的图片是数据集中带有标签的词的表示。

在我们使用的数据中,我们有12个独特的标签。就像下面的图片。

下面的图片代表了过渡概率表。

在表中我们可以看到,我们几乎没有零值。通过这一点,我们可以说对数据的标记几乎是正确的,我们也可以用维特比算法来优化它。

上面给出的图片是数据集的10个句子的结果,我们可以看到我们几乎得到了94%的准确率。这已经足够好了,这意味着在这之后我们可以进行我们项目的下一步了。由于我所使用的数据集可以被认为是已经处理过的理想数据。在任何现实生活中,为了获得更多的准确性,我们可以对数据进行更多的修改,比如提供更多的规则,这样就可以通过在数据上实施更多的标签来更准确地完成标记程序。
最后的话
在这篇文章中,我们已经看到了隐马尔科夫模型的定义和解释。这个模型可以有多种应用。作为隐马尔科夫模型的直觉,我们可以说它主要应用于数据连续的领域,考虑到这一点,我们已经看到它如何在部分语音标签中为我们带来好处,这在任何NLP项目中都起着至关重要的作用,我们可以很容易地准确执行它。
原文地址:https://analyticsindiamag.com/a-guide-to-hidden-markov-model-and-its-applications-in-nlp/
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
