亚马逊最新发布Feature Store简介
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。
Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。
Feature Store的提出我也没找到来源,但是Jim Dowling是Feature Store的最积极的推动者之一。这位同志是英国皇家理工学院的Associate Professor,在2016年创办了Logical Clocks,目的是将AI与数据智能从学术界带到企业界。Logical Clocks最主要的产品就是Hopworks,是一个企业级的Feature Store。
那么,Feature Store是什么?它与传统的数据仓库的区别是什么?本文将一一介绍。
一、什么是Feature Store?
机器学习或者人工智能算法的输入是数据,但是一般情况下都需要对数据做处理,并计算成特征之后才能被算法所使用。例如NLP和CV中,原始的文本与图像通常可能需要变成Embedding才能作为Deep Learning算法的输入。然而创建特征的过程是一项非常耗费精力的过程,但是创建的特征在分割的系统中却通常无法被重复使用。这就导致一些资源浪费了。而Feature Store的创立就是为了保存大量的数据特征并供不同的应用使用。
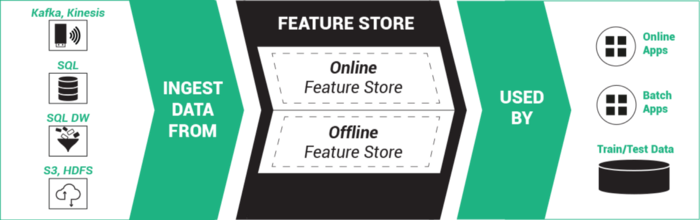
Feature Store通常解决如下问题:
- 为不同的项目构建可重复使用的特征库
- 提供低延迟特征访问服务
- 保证模型训练与服务所需要的特征的一致性
- 提供特征的版本管理(因为特征需要经常更新,因此,模型使用的特征可能未必是最新的,如果需要查询模型训练和服务使用的特征,那么就需要找到相应的特征版本)
二、为什么需要Feature Store?
其实前面一部分我们已经说明了使用Feature Store的原因,这里我们进一步来说明一下。
如下图所示,是一个非常简单但是通用的AI应用系统。

在一般的企业业务中,都会存在多个不同的业务系统,需要各种不同的算法支撑。每一种算法都会从原始的数据开始处理计算,并得到最终的训练数据,进行算法的训练与应用。例如,企业可能有针对消费者的推荐系统,需要利用用户数据、项目数据与用户的点击历史来构造推荐系统的训练数据,这里可能会使用用户的偏好特征,转成用户的偏好向量作为输入。而另一个应用,例如广告预测,可能也会用到这个用户的偏好向量。在现有的AI系统中,这两个业务可能会各自构建自己的机器学习的过程,从读取原始数据开始,做特征工程,再到最后进行算法的训练。但其实,他们用到的用户偏好向量都是同一个。显然这里的特征是可以被重复利用的。
在一个多任务的AI系统中,很多应用所需要的特征都是重复的,各自构建自己的流水线进行特征工程浪费了大量的资源,如果能构造一个统一的特征库,使用的时候选择读取特征进行训练,那么会大大提高系统的开发效率。这就是Feature Store被需要的原因。
三、Feature Store与数据仓库的区别

从刚才的分析看可能有童鞋会想,这玩意和数据仓库很像啊,大家都把数据给数据仓库(或者最近很火的数据湖),然后数据仓库提供高可用的数据访问服务,减少重复工作,提高工作效率。那么Feature Store与数据仓库有什么区别呢?
区别主要是是存储的内容不同。数据仓库是将企业的数据构建在一个统一的平台中,提供给不同的对象访问。业务再使用Tableau或者Power BI工具访问,得到业务洞察结果。而Feature Store是提供给数据科学家使用的一种中心化保存数据特征的数据仓库,也就是把所有数据科学家能用到的特征放到统一的平台进行计算构建,重复使用。而这里说的特征通常是根据数据仓库中的数据计算得到并可以被机器学习算法所直接使用的东西。也就是说数据仓库可以理解为Feature Store的输入。

上图是Hopsworks官网的一个图,非常形象的描述了Feature Store的定位,也就是说数据仓库的数据经过特征工程的处理之后就可以得到Feature Store了。
下图是Jim Dowling对二者的一个详细比较:

总结一句话就是数据仓库管理的对象是数据,它不会针对机器学习等应用进行计算或者转化。通常情况下,机器学习的业务需要自己构建特征工程来根据数据仓库中的数据计算所需的特征。而Feature Store则是计算好了所有的特征,让数据科学家可以直接使用这些特征,关注算法本身即可。
四、Feature Store的系统结构
尽管Feature Store的功能说起来很简单,但其实它本身作为一个企业的系统需要考虑的工程问题却很多。
- Feature Store系统的设计目标主要包括:
- 不同的项目之间可以共享特征
- 模型的训练与服务之间的特征需要保证一致性
- 将特征工程从算法和模型中分离出来
- 提供特征的在线和离线的访问
因此,一个强大的Feature Store需要考虑特征的存储、计算与服务等各个方面。
由于不同的模型和算法对特征的访问是不同的,因此Feature Store考虑特征的离线访问与在线访问的问题,主要包括高效的内部存储,快速的访问,需要支持批次读取或者流式读取等。
五、各大厂商的Feature Store产品
各大厂商在这两年都陆续发布了很多相关的产品,这里做个简单的列举。以后有时间我们再对比一下这些厂家Feature Store的差异。
Hopsworks https://www.hopsworks.ai/
Amazon SageMaker Feature Store https://aws.amazon.com/cn/sagemaker/feature-store/

Google Feast https://feast.dev/

参考文献: https://medium.com/data-for-ai/what-is-a-feature-store-for-ml-29b62580af5d https://www.bmc.com/blogs/feature-stores/ https://www.hopsworks.ai
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
