最流行的用于预测的机器学习算法简介及其优缺点说明
6,994 阅读
预测问题一直是机器学习领域最重要的问题之一。很多算法包括回归、决策树等都是用来解决预测的常用算法。预测问题的核心是基于已有的有标签的数据来判断新数据的标签。一般来说,根据预测标签是离散的还是连续的可以分成分类问题和回归问题。注意,本篇博客主要是快速回顾描述各个模型的优缺点,因此不会对模型有很深的介绍。

本文主要总结一下常见的六种预测算法,每一类算法都会简要的描述其概念及其优缺点。
一、线性回归(Linear Regression)
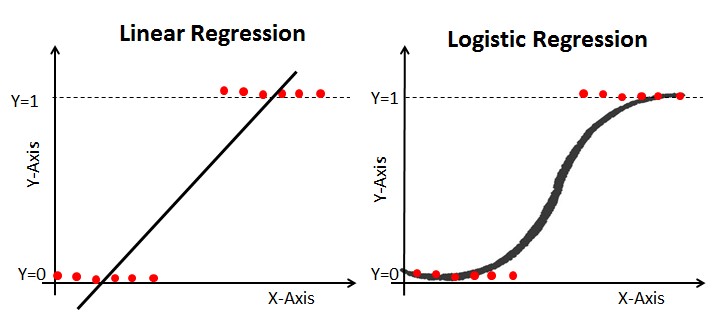
描述:线性回归是一种统计的方法,它尝试使用一个线性方程来拟合两个变量之间的关系。其中一个变量是解释变量,另一个是因变量。在线性回归中,使用线性预测函数对关系进行建模,其未知的模型参数是根据数据估计的。
:1、易于理解;2、可以看到哪个变量对模型影响最大。 :1、对于复杂的变量关系难以捕捉;2、容易过拟合。
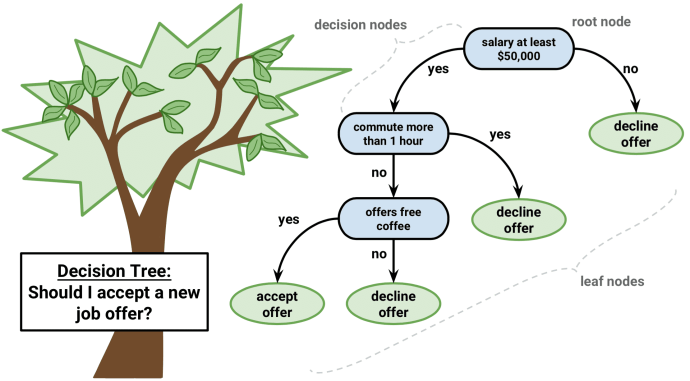
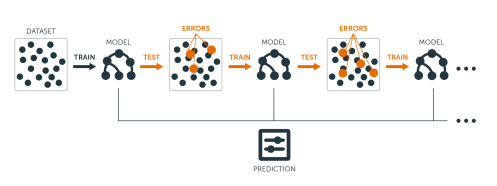
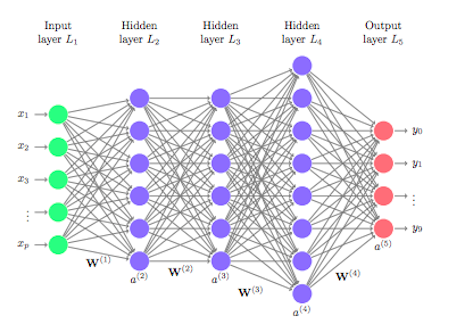
**优点**:容易理解且易于实现 **缺点**:对于复杂数据的建模能力较差,现实使用较少。 **优点**:使用多棵树群体决策,有时候会产生非常好的结果,同时训练的速度很快。 **缺点**:与其它算法相比,产生预测结果可能比较慢。是一个相对黑盒的模型,不太容易理解预测结果。 **优点**:预测性能很好。 **缺点**:训练集或者是预测集微小的变化会导致模型巨大的改变。同时对于预测结果不太容易理解。 **优点**:可以处理非常复杂的数据集,规模越大效果可能越好。 **缺点**:训练过程很慢,且需要很多的资源。几乎无法对结果理解。