OpenAI开源最新的3D物体生成预训练模型——Point-E
三维物体的生成(3D)其实是AR/VR领域一个非常重要的技术。但是,受限于算力和现有模型的限制,三维物体的生成相比较图像生成来说效率太低。目前,最好的图像生成模型在几秒钟就可以根据文字生成图像结果,但是3D物体的生成通常需要多个GPU小时才可以生成一个对象。为此,OpenAI在今天开源了一个速度极快的3D物体生成模型——Point-E,需要注意的是,这是今年来OpenAI罕见的源代码和预训练结果都开源的一个模型。
下图是一个实例:

Point-E只需要1-2分钟即可生成一个3D对象。‘
Point-E模型首先使用文本到图像的扩散模型生成一个单一的合成视图,然后使用第二个扩散模型生成一个三维点云,该模型以生成的图像为条件。虽然该方法在采样质量方面仍未达到最先进的水平,但它的采样速度要快一到两个数量级,为一些使用情况提供了实际的权衡。
下图是该模型的一个high-level的pipeline示意图:
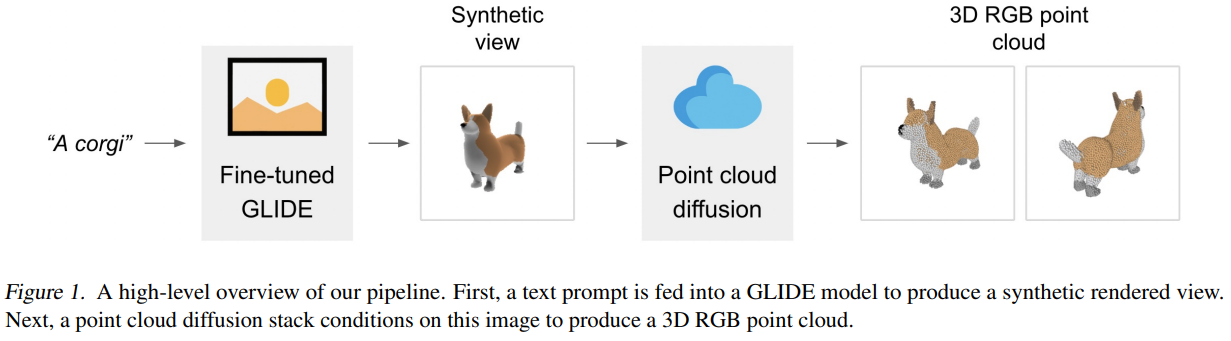
当前,该模型的版本包括如下几个:
| 预训练模型参数 | 说明 | 预训练模型下载地址 | | ------------ | ------------ | | | 4000万(uncond) | 一个没有任何条件信息的小模型 | https://openaipublic.azureedge.net/main/point-e/base_40m_uncond.pt | | 4000万(text vec.) | 一个小的模型,它只对文本标题,而不是渲染的图像进行限制。文本标题是用CLIP嵌入的,而CLIP的嵌入是作为一个单一的额外的上下文标记来附加的。这个模型依赖于我们的3D数据集中的文本标题,并没有利用微调的GLIDE模型。 | https://openaipublic.azureedge.net/main/point-e/base_40m_textvec.pt | | 4000万(image vec.) | 一个小模型,它以渲染图像的CLIP图像嵌入为条件,与Sanghi等人(2021)类似。这与其他图像条件模型的不同之处在于,图像被编码为上下文的单一标记,而不是作为对应于CLIP潜意识网格的潜意识序列 | https://openaipublic.azureedge.net/main/point-e/base_40m_imagevec.pt | | 4000万 | 一个小型的模型,通过CLIP潜意识的网格进行全图像调节 | https://openaipublic.azureedge.net/main/point-e/base_40m.pt | | 3亿参数 | 一个具有完整图像调节功能的中等模型通过CLIP潜规则的网格。| https://openaipublic.azureedge.net/main/point-e/base_300m.pt | | 10亿参数 | 一个大型的模型,通过CLIP潜规则的网格进行全图像调节。 | https://openaipublic.azureedge.net/main/point-e/base_1b.pt |
需要注意的是,Point-E的效果比不上Google的DreamFusion,但是速度比谷歌家的模型快600倍!
明年,3D物体生成模型应该会有大爆发,StabilityAI家的3D Stable Diffusion和Midjourney 3D版本估计都会发布。值得期待!
Point-E模型卡信息:https://www.datalearner.com/ai-resources/pretrained-models/point-e Point-E开源代码:https://github.com/openai/point-e
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
