5月3日,2个重磅开源的AI模型发布:Replit代码补全大模型和LLaMA复刻版OpenLLaMA发布
2,205 阅读
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
这两个项目都是开源的模型,就模型的前景来说,值得大家关注。
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
这两个项目都是开源的模型,就模型的前景来说,值得大家关注。
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送

Replit 是一家在线代码编辑器和云IDE公司。它提供一个在线编程环境,让用户可以编写代码并直接运行和调试程序。
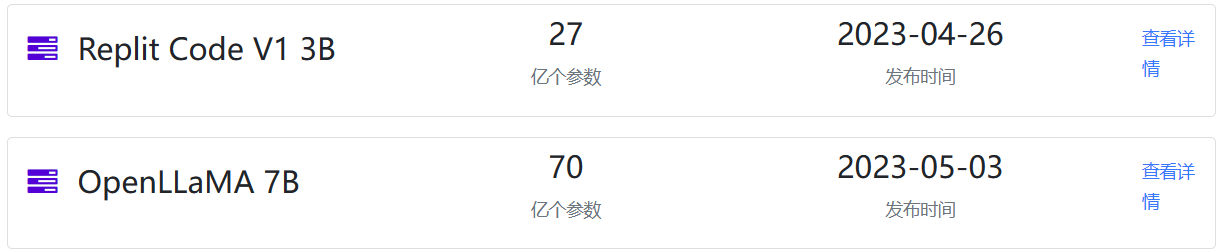
2023年4月26日,Replit官方宣布他们正在训练2个代码补全模型,一个是replit-code-v1-3b,一个是replit-finetuned-v1-3b。本次开源的是前者。

这两个模型都是27亿参数,但官方并未透露二者的具体差别。从名称看,前者是专注编程相关,后者则是通过某种方法微调得到。当时,官方给出了2个对比测试结果,一个是与开源的编程模型相比,27亿参数的replit-finetuned-v1-3b效果最好,清华大学的CodeGeeX第二,而replit-code-v1-3b得分第三。在非开源的模型对比中,replit-finetuned-v1-3b也取得了第二名的好成绩。关键是,replit这两个模型的参数规模相比较其它模型都很小。
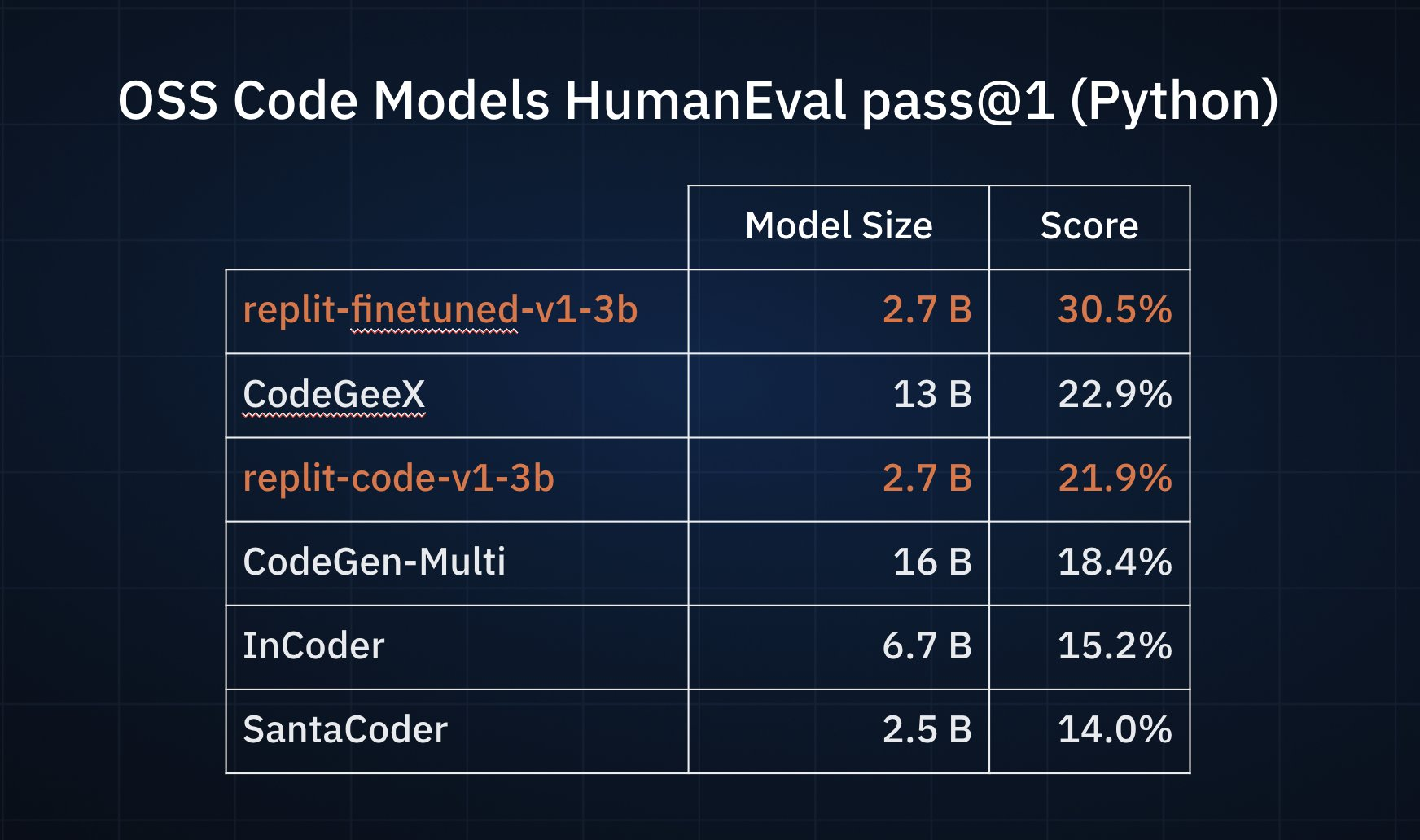
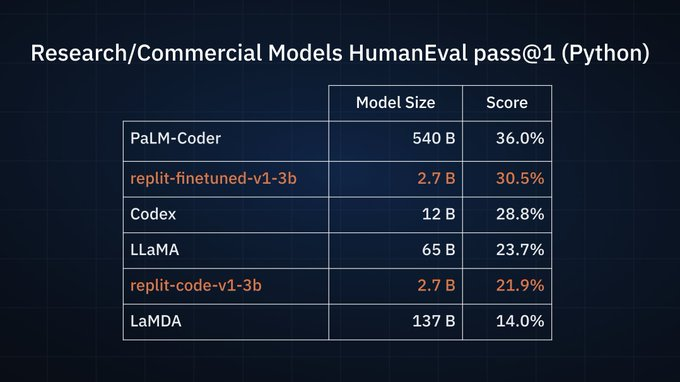
2023年5月3日,Replit Code V1-3b正式发布,并在HuggingFace上开源。模型也有了更多的细节。
Replit Code V1-3b模型主要关注代码补全的能力,基于Stack Dedup v1.2数据集的一个子集进行训练,共包含5250亿个tokens(数据集本身只有1750亿tokens,Replit将其重复了3个Epochs)。Replit Code V1-3b支持20种编程语言的补全能力。下图是我测试的结果:
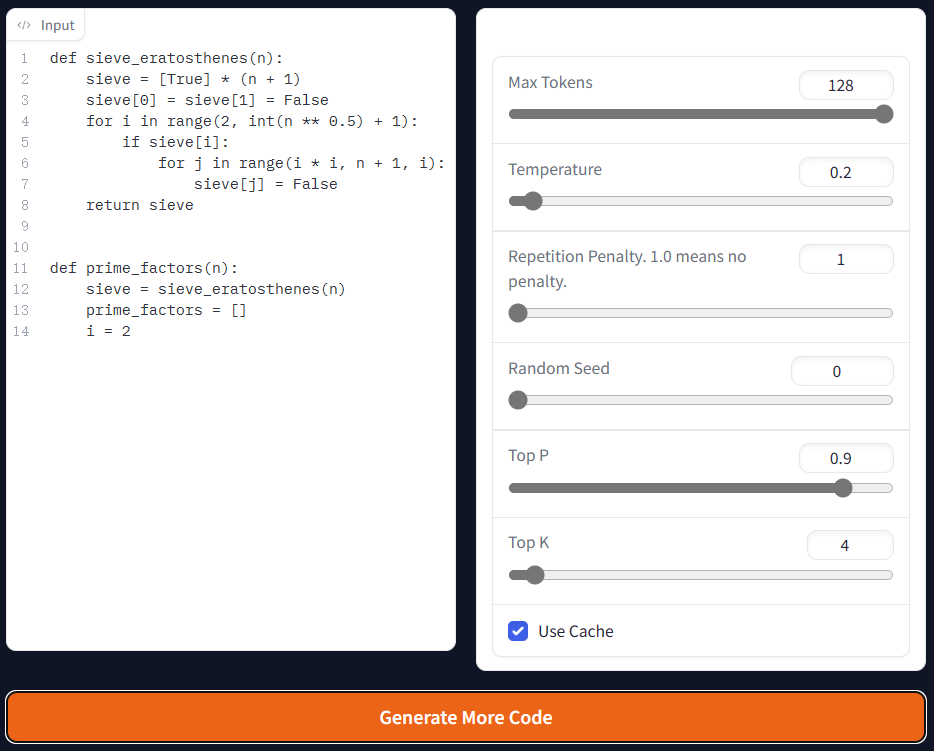
需要注意的是,该模型从测试看可以很好的识别代码含义,并做补全。但是,与商业化版本的GitHub Copilot相比,工程化能力有欠缺,例如,它的补全可能不会基于单个方法,而是方法结束之后继续补全了其它方法。官方也没有透露效果更好的replit-finetuned-v1-3b未来是否开源,估计按照他们公司的属性,很有可能作为收费服务在云端IDE提供。
不过,预训练结果已经发布,并且没有商用限制,基于该模型进行代码补全插件的二次开发应该十分具有前景。预训练结果10.4GB,消费级显卡估计很难带动,希望后面有量化版本出现。
Replit Code V1 3B在DataLearner上的模型信息卡链接:https://www.datalearner.com/ai-models/pretrained-models
OpenLLaMA 7B是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
MetaAI发布LLaMA模型的时候,在论文中详细描述了模型的架构、数据集的处理等信息,并向业界发布了预训练结果。但是LLaMA的许可有一个限制是任何基于LLaMA微调的模型都需要从MetaAI申请原始的预训练结果文件,不允许私自分发。
OpenLLaMA的目的是从头开始训练一个类似LLaMA模型,使用的模型架构、context长度、训练步骤、学习速率等,完全按照原始的LLaMA论文设置。唯一的区别是OpenLLaMA使用RedPajama数据进行训练。
5月3日,OpenLLaMA发布第一个训练结果,即OpenLLaMA 7B模型,70亿参数版本的模型,基于2000亿tokens的RedPajama数据集训练。使用Google的TPU-v4s和EasyLM进行训练。模型提供JAX和PyTorch两个版本的预训练结果。训练过程中的损失函数如下:
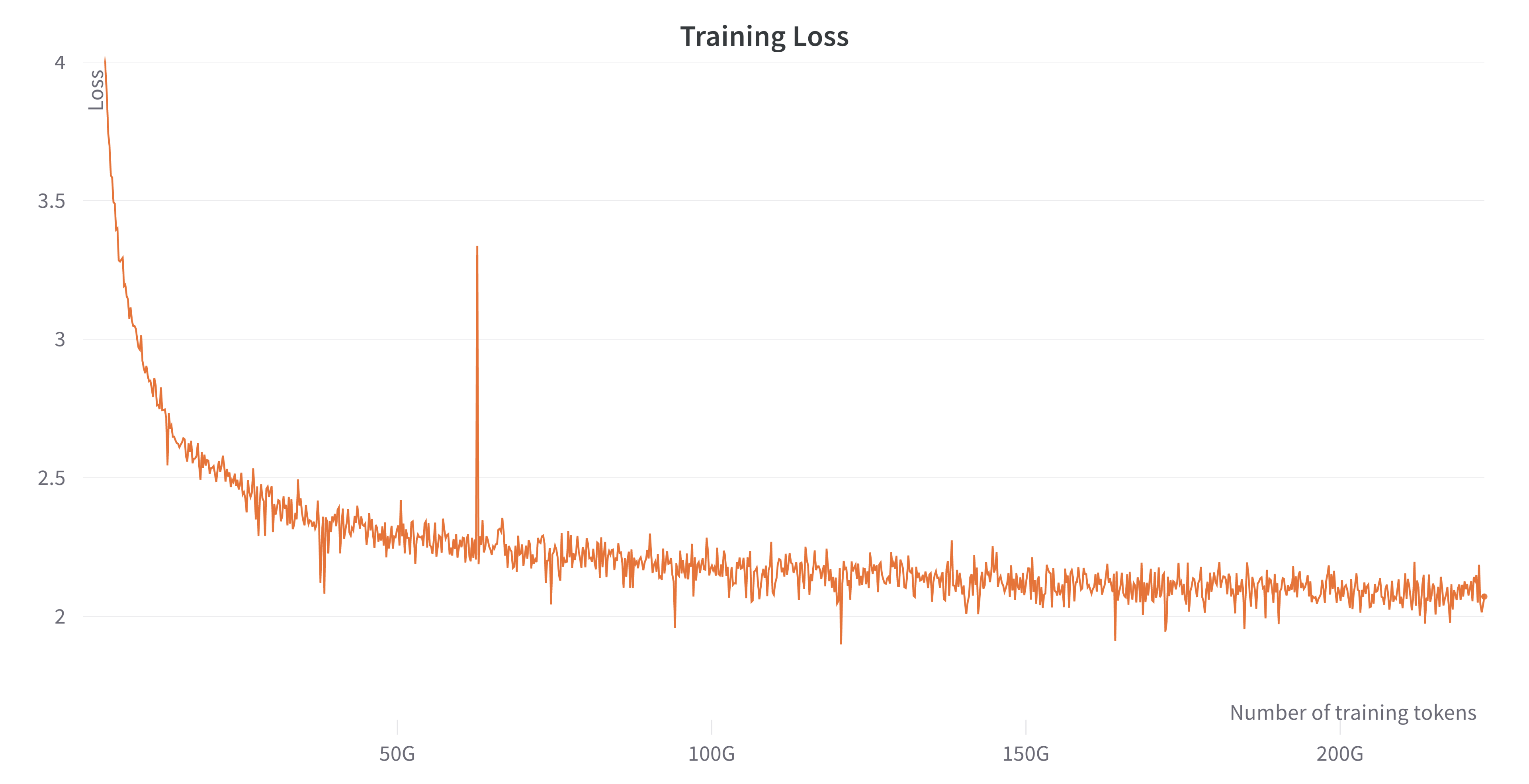
由于OpenLLaMA 7B完全从头开始训练,因此无需获取原始的LLaMA权重,也不需要遵从LLaMA相关的协议。目前官方说法是这个预览版的预训练结果和训练框架都是基于Apache 2.0协议开源。因此商用友好。不过需要注意的是,未来正式版本是否有变更还不确定。
OpenLLaMA 7B在DataLearner上的模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/OpenLLaMA-7B
| 训练平台 | UC Berkeley的EasyLM | https://github.com/young-geng/EasyLM |
| 训练速度 | 每秒每TPU-v4s训练1900个tokens |
| 训练数据集 | RedPajama | https://www.together.xyz/blog/redpajama |
| 开源情况 | 完全开源 |