PyTorch 2.0发布——一个更快、更加Pythonic和灵活的PyTorch版本,让Tranformer运行更快!
在去年12月2日的PyTorch大会上(参考链接:重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!),PyTorch官方宣布2.0版本即将到来,而今天,PyTorch2.0的稳定版正式发布!本篇博客将主要关注PyTorch 2.0最主要的特性!

一、PyTorch 2.0概述
PyTorch 2.0是PyTorch的下一代版本,提供了兼容前期版本的的eager模式的开发和用户体验,同时在编译器级别上改变和加强了PyTorch的运行方式,具有更快的性能、对动态形状和分布式的支持。PyTorch 2.0发布了包括PyTorch Transformer API的新的高性能实现(以前称为“Better Transformer API”,现在更名为Accelerated PyTorch 2 Transformers)以提升对多种深度学习模型架构的支持。2.0版本的PyTorch最大的特点是有非常明显的速度方面的提升。
下面我们将介绍其中最重要的几个更新。
二、对transformer架构的速度提升
这似乎是一个非常大的惊喜了。根据当前广泛流行的竞赛和论文(2022年竞赛报告数据:2022年机器学习竞赛领域大家都在使用什么AI模型?——2022竞赛模型使用分析报告!),transformer架构在NLP领域几乎一统天下,在CV领域也与CNN分庭抗礼。因此,transformer训练的速度对于当前的模型开发十分重要。
下图是PyTorch1.13与2.0版本训练速度的对比:
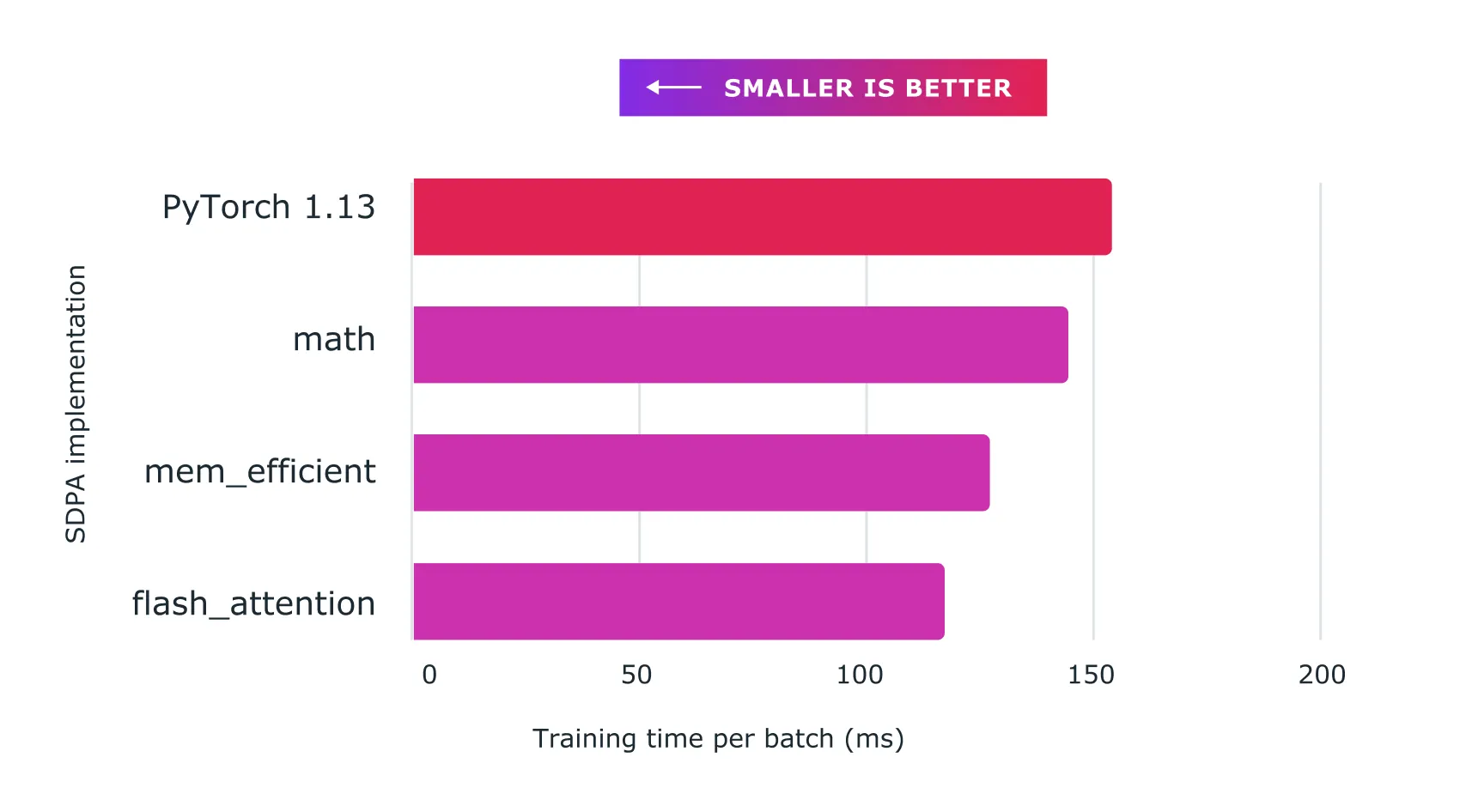
可以看到,相比较PyTorch1.13版本,2.0版本速度提升明显,每个批次的训练时间从超过150ms降低到最低只有120ms左右。这对于大型语言模型的训练性能提升来说十分巨大。而这只需要你在你现有模型代码之前加上model = torch.compile(model)即可。
三、对苹果Mac支持更加友好
是的,你没看错,PyTorch2.0优化了对mac电脑的支持,加入了MPS Backend能力,可以使用Mac电脑的GPU加速训练。此版本带来了更好的正确性、稳定性和操作符覆盖范围。
四、提升X86芯片上模型量化的性能
新的X86量化后端使用FBGEMM和oneDNN内核库,取代FBGEMM成为x86 CPU平台的默认量化后端,并提供比原始FBGEMM后端更好的int8推理性能,利用两个库的优势,对40多个深度学习模型进行了1.3倍至2倍的推理性能加速。新的后端在功能上与原始FBGEMM后端兼容。 这是默认启动的能力,也就是说,只要你升级到了PyTorch2.0,那么你在X86芯片上运行模型量化和推理就可以速度更快,最多速度可以提升2倍。
五、提高了CPU上GNN推理的性能
PyTorch 2.0包括几项关键优化,以提高CPU上的GNN推理和训练性能。在2.0之前,由于缺乏对几个关键内核(散射/聚集等)的性能调整和缺乏与GNN相关的稀疏矩阵乘法运算,PyG的GNN模型在CPU上效率低下。 而现在,在基准测试中,单个节点推理场景下,2.0的PyTorch测量出1.12x-4.07x的性能加速结果!
六、其它更新
除了上述优化的性能,PyTorch2.0还有一些原型特性,未来将进入beta测试版本。主要包括放弃对Cuda11.6的支持,增加对Python3.11的支持等。
总结一下,PyTorch2.0的稳定版本发布,这个版本真的是对性能有极大的提升,而且几乎不需要改动代码即可带来新的特性。从前面的内容可以看到,在模型架构如transformer、模型量化等,在芯片支持如Mac版本的GPU、CPU上的推理等都在提升性能。不得不说,PyTorch被广大地球人这么喜爱是有道理的!
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
