
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



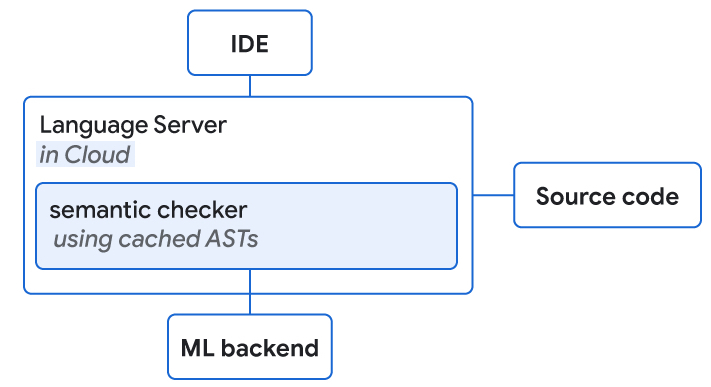
我们将介绍如何将ML和SE结合起来,开发一种新的基于Transformer的混合语义ML代码补全,现在可供内部谷歌开发人员使用。我们讨论了如何通过(1)使用ML对SE单标记建议重新排序,(2)使用ML应用单行和多行补全并使用SE检查正确性,或(3)使用单标记语义建议的ML的单行和多行延拓来组合ML和SE。

重磅福利,斯坦福大学在去年秋季开设了应该是全球第一个transformers相关的课程,授课人员来自OpenAI、Google Brain、Facebook人工智能实验室、DeepMind甚至是牛津大学的业界与学术界的一线大牛。而这两天,这门课相关视频也都公开了,大家可以去观看学习了!

《Python for Data Analysis: Data Wrangling with pandas, NumPy, and Jupyter》是由Wes McKinney撰写的Python数据分析专业工具书籍。很容易理解,这本书就是教大家如何使用Pandas、NumPy以及Jupyter分析数据的。
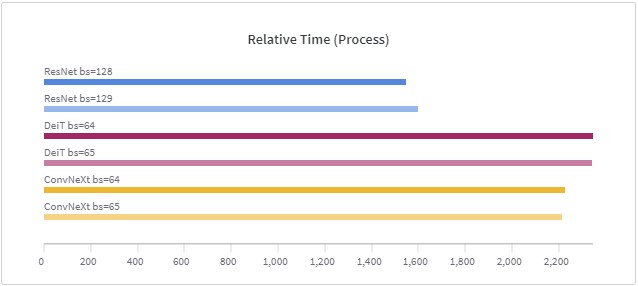
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。

指标(metrics)和损失函数(loss function)在深度学习和机器学习里面非常常见,很多时候他们的公式都似乎是一样的,在编写程序的时候,二者的区别好像也不是很大。那为什么还会有这两种不同的概念出现呢?本文将简单介绍一下二者的区别和应用。
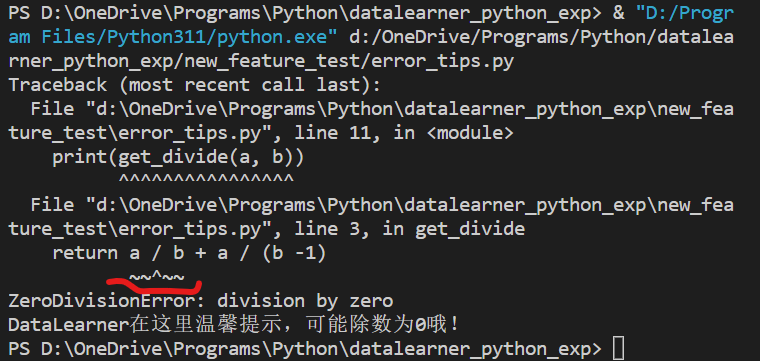
上个月Python的3.11版本发布了第一个beta版本,3.11带来了很多非常棒的新特性,例如错误提示更加具体,可以定位到具体代码位置等,十分友好,建议大家关注。这里简单为大家介绍一下。

昨天,卡地夫大学的NLP研究小组CardiffNLP发布了一个全新的NLP处理Python库——TweetNLP,这是一个完全基于推文训练的NLP的Python库。它提供了一组非常实用的NLP工具,可以做推文的情感分析、emoji预测、命名实体识别等。

前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。
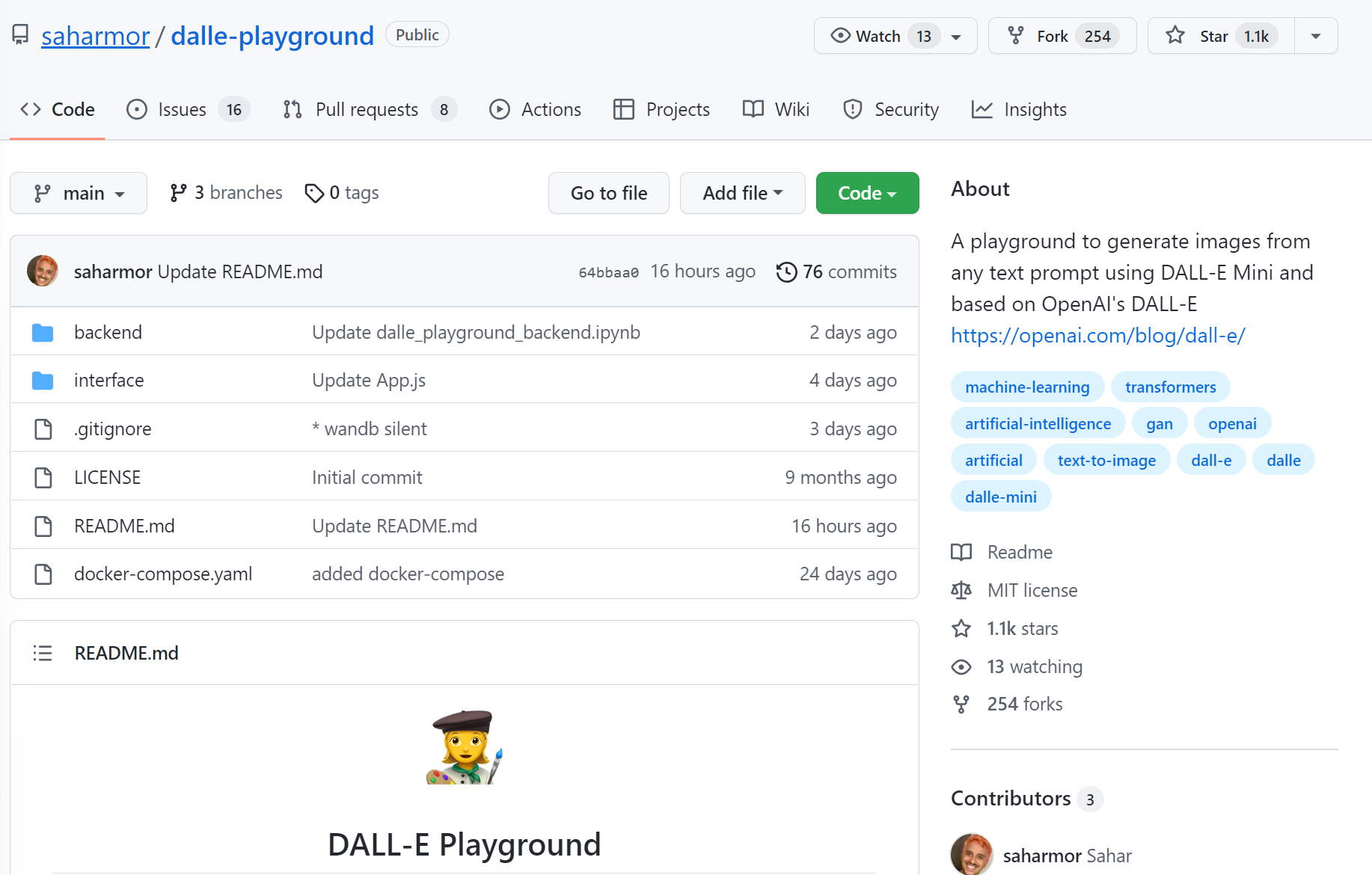
大规模的text-to-image模型没有公开预训练结果,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。

最近开始学习新的前端技术。以前开发网站直接使用jQuery+Bootstrap组合,感觉非常容易和方便。但是,现在前端貌似都开始转向基于构建的方式去开发。由于初学者进入一个项目看很多内容也不如上手启动一个项目感受好,本文抛弃原理,直接教大家上手创建一个vue项目。

就在儿童节前一天,Hugging Face发布了一个最新的深度学习模型评估库Evaluate。对于机器学习模型而言,评估是最重要的一个方面。但是Hugging Face认为当前模型评估方面非常分散且没有很好的文档。导致评估十分困难。因此,Hugging Face发布了这样一个Python的库,用以简化大家评估的步骤与时间。
在做LeetCode题目的时候,有一类题目是关于大数运算的。比如,全排列计算或者组合运算,在使用C语言或者Java代码解决这类问题的时候都会遇到变量数值超过阈值的情况。一般来说需要自己构造字符串数组或者是其它数组来存储超过长度的数值。但是,使用Python语言处理这类问题时候却毫无压力,这类题目的计算不会有任何问题。本文将从Python底层实现解释这个问题。

自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。
本周,谷歌的研究人员在arXiv上提交了一个非常有意思的论文,其主要目的就是分享了他们建立能够翻译一千多种语言的机器翻译系统的经验和努力。