
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




ChatGPT是OpenAI提供的最强大的大模型服务。而截止目前为止,OpenAI公开的ChatGPT的订阅计划包含三个:免费版本的ChatGPT-3.5、个人用户付费订阅的ChatGPT Plus以及面向企业的企业版本。而最新的ChatGPT的API接口显示,OpenAI即将推出一个Team版本的计划,是当前ChatGPT Plus版本的升级版!

LangChain是当前大模型应用开发领域里面最火热的框架。由于其提供了丰富的数据访问接口、各种大模型的交互接口以及很多构造大模型应用所需要的方法与实践工具,受到了很多人的关注。然而,今天Hacker News上的一位开发者直接提出LangChain是一个无用的框架,引起了很多人的共鸣。很多人都表示,在实际开发中,LangChain有很多问题,可能并不适合用来做大模型应用开发。
Code Interpreter是ChatGPT官方提供的一个插件。使用这个插件之后,ChatGPT可以通过生成Python代码来解决你的问题。在上周,Code Interperter已经完全开放给所有的付费用户,在大家使用了一段时间之后,已经有很多人通过机智的prompt来获取了Code Interpreter背后的执行环境和系统prompt信息等。本文针对这些获取的信息做一个总结,供大家参考。
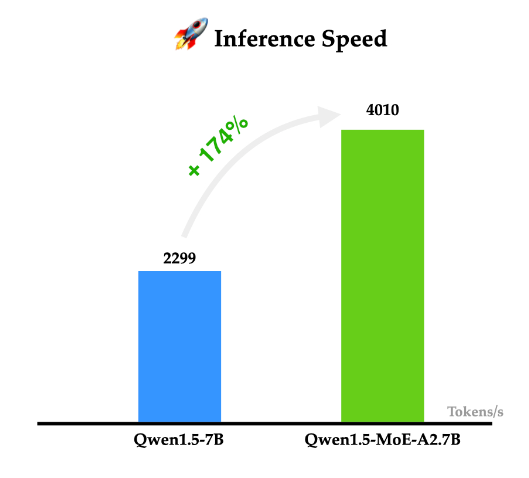
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
最近,谷歌发布了一项新的工具:Google Interview Warmup,让你练习回答由行业专家选定的问题,并使用机器学习来转录你的答案,帮助你发现改进面试的回答。
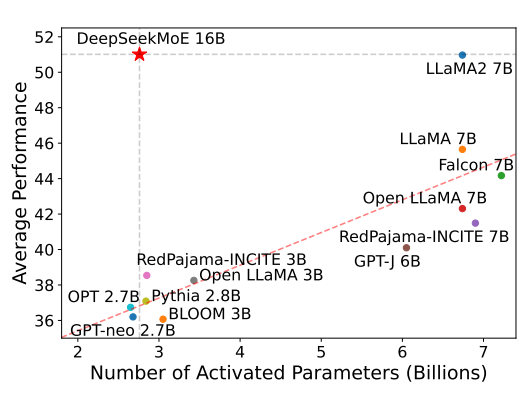
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。
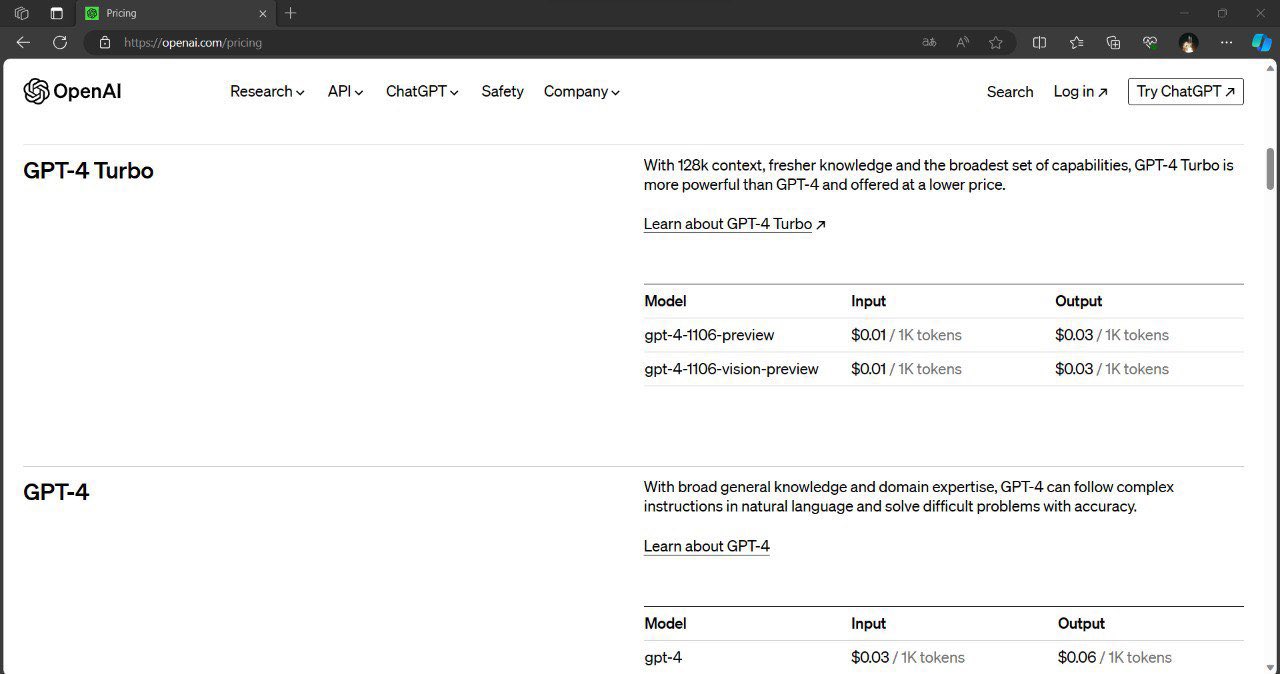
就在刚刚,有网友发现OpenAI的官方的文档接口更新中增加了128K的超长上下文版本,命名为GPT-4-128K-Turbo!

MLPerf™是MLCommons发布的一个用来测试AI相关软硬件性能的基准测试工具。2021年12月1日, Training v1.1的结果发布,这个结果不仅展示了最新的AI相关软硬件的进展,也有一个新的现象,就是AI训练正在超越摩尔定律。本文将简要解读一下相关数据。
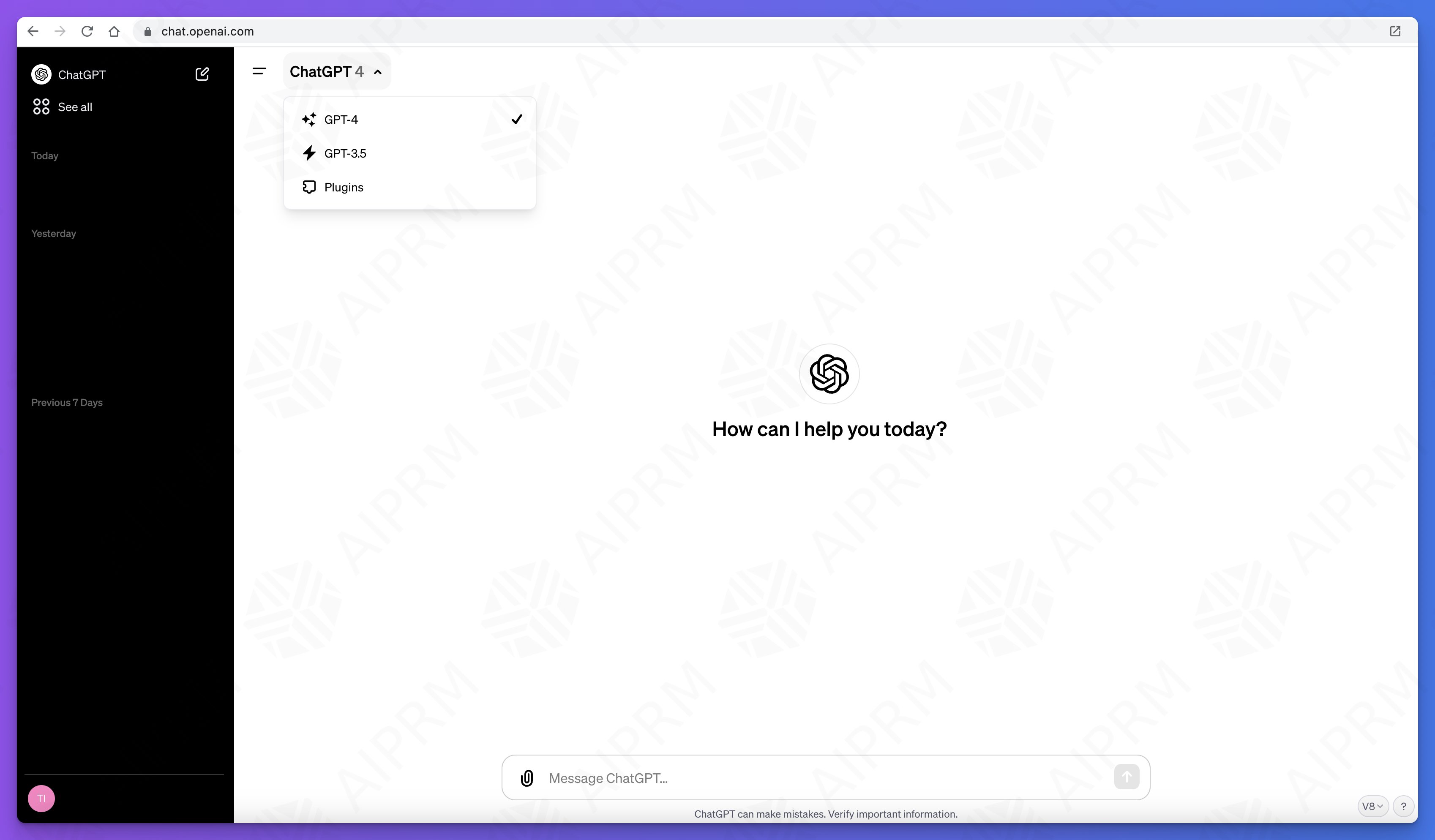
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!

Jupyter Notebook虽然在教学等领域有着非常大的优势,但是实际编程中,它的效率、可维护性等方面与python脚本相比的差距到底在哪也一直不那么清晰。就在上个月底,JetBrains的研究人员使用了大量的数据详细对比了二者的差异。这里总结一下其主要结论。