
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




本文是Effective Java第三版笔记的第七个之消除过期的对象引用,Item 7: Eliminate obsolete object references
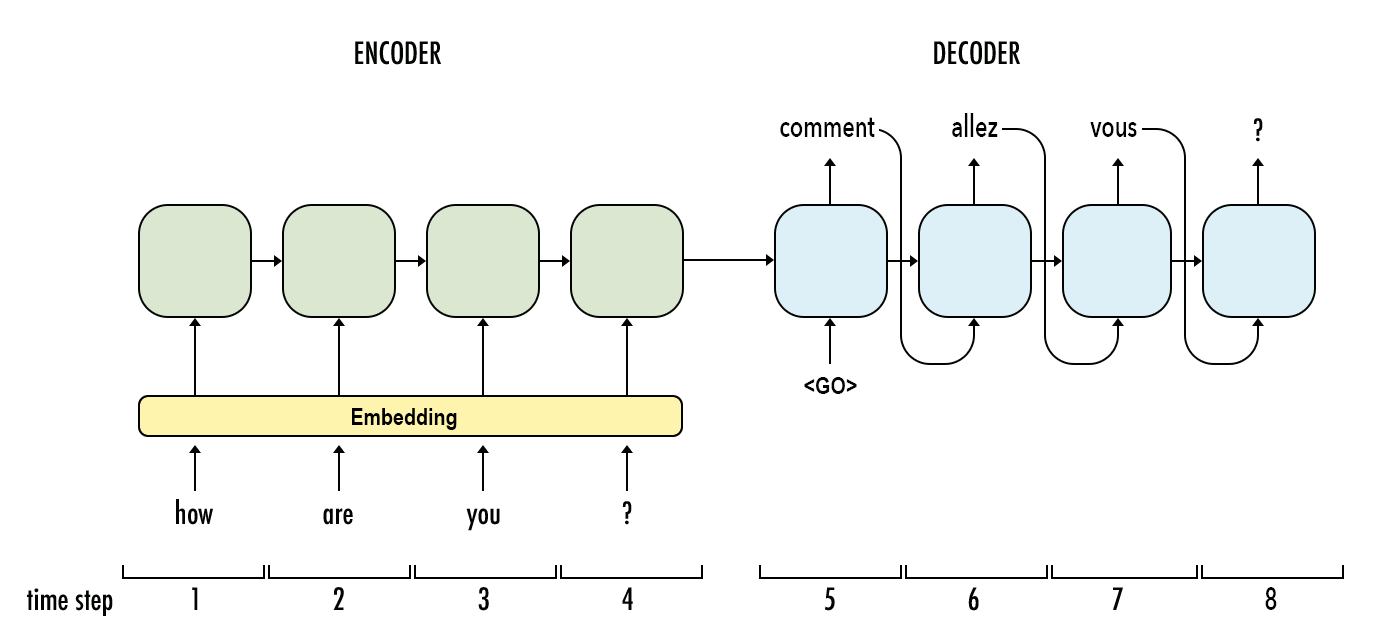
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。

为初学者、中级和有经验的开发者提供70多个python项目, 10000, 小木, PythonHub今天在推上给大家分享了一个非常棒的项目,就是这个为为初学者、中级和有经验的开发者提供70多个python项目。 亲自动手实践一些项目可以增加我们的实际的编程技巧。每一次都做一点将会得到很多。很多人都在GitHub、Reddit或者是Quera上搜索过哪些项目可以让Python初学者、中级者增加经验的Python项目。这次它来了。

随着ChatGPT的火爆以及MetaAI开源了LLaMA,各家公司好像一夜之间都有了各种ChatGPT模型的研发实力。而针对不同任务和应用构建的LLM更是层出不穷。那么,如何选择合适的模型完成特定的任务,甚至是使用多个模型完成一个复杂的任务似乎仍然很困难。为此,浙江大学与微软亚洲研究院联合发布了一个大模型写作系统HuggingGPT,可以根据输入的任务帮我们选择合适的大模型解决!

ChatGPT的Code Interpreter插件让ChatGPT突破了大语言模型本身只能做文本处理的限制,使其可以通过生成并执行Python代码来实现强大的数据分析、图片生成、视频数据处理等操作,大大拓展了ChatGPT的实用范围和价值。在此前的文章中,我们已经分析了Code Interpreter插件的官方实现。而今天,LangChain的官方博客也推出了一种类似的开源方案,让开源模型也可以实现ChatGPT的Code Interperter插件。我们简要描述一下这个方案。
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。

Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!