大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



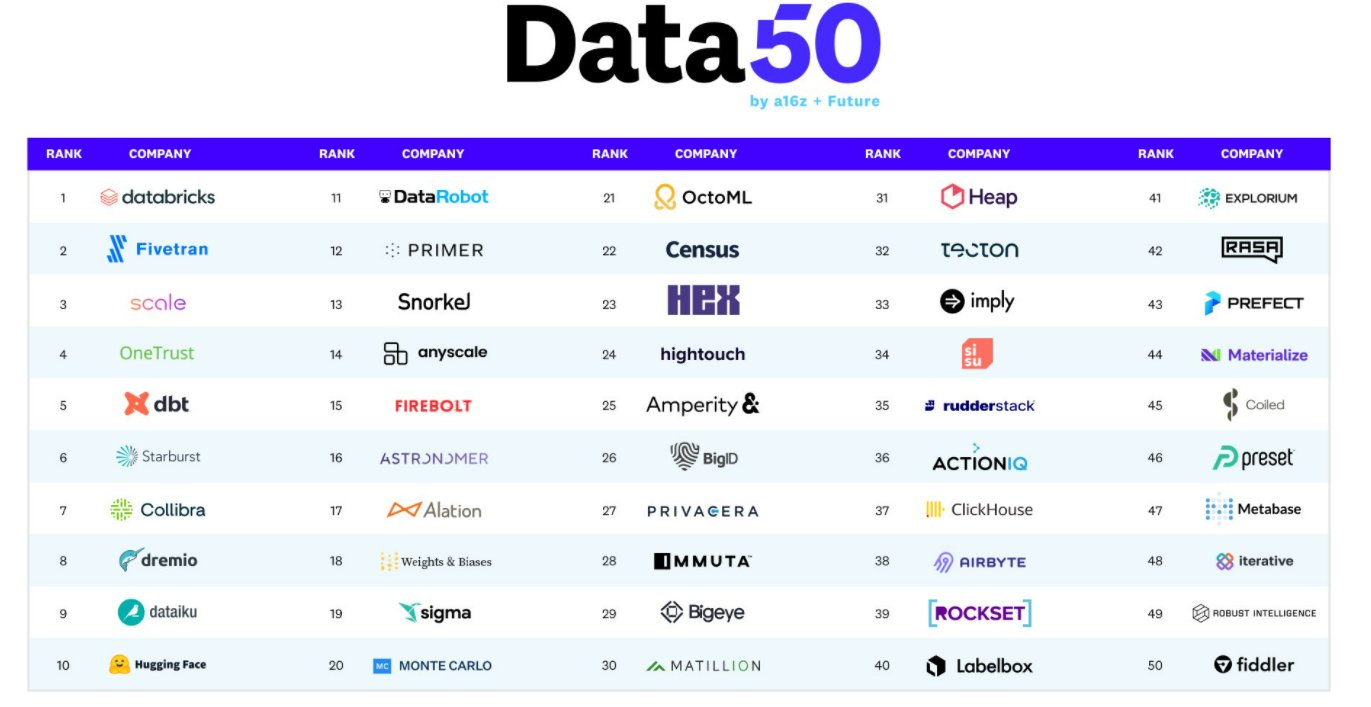
最近几年,数据的重要性在各个领域都获得了巨大的重视。因此,数据管理相关的业务也成为各项基础设施中增长最快的业务,目前的市场规模约700亿美元,占所有企业的基础设施支持约1/5。仅在2021年,数据处理相关的公司获得了数百亿的风险投资。为此,Future总结了2022年全球最大的50家数据创业企业。这里我们列举其中的最大的10个进行介绍。

大模型虽然效果很好,但是对资源的消耗却非常高。更麻烦的其实不是训练过程慢,而是峰值内存(显存)的消耗直接决定了我们的硬件是否可以来针对大模型进行训练。最近LightningAI官方总结了使用Fabric降低大模型训练内存的方法。但是,它也适用于其它场景。因此,本文总结一下相关的方法。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。

在编程的世界中,有不同层次的语言(language),这些语言有时候也称代码(code)。本文将简单介绍编程语言(Programming Language)、汇编语言(Assembly Language, ASM)、机器语言(Machine Language/Code)的区别。

在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。
机器学习是实现人工智能最重要的方法之一,包括深度学习等都属于机器学习中的一种方法。因此,机器学习的应用被认为是实现人工智能应用的重要途径。人工智能的应用目标是使用计算机(机器)来代替或者辅助人工来完成某项任务。机器学习在解决业务问题的应用需要谨慎考虑。本文提供一些步骤可以参考。
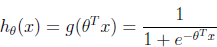
监督学习中的分类问题和Logistic回归常常被用于推荐问题中关于BPR的研究,但是为什么一定要用Logistic函数来建模和优化呢?本篇博客将带你揭晓奥秘~

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。
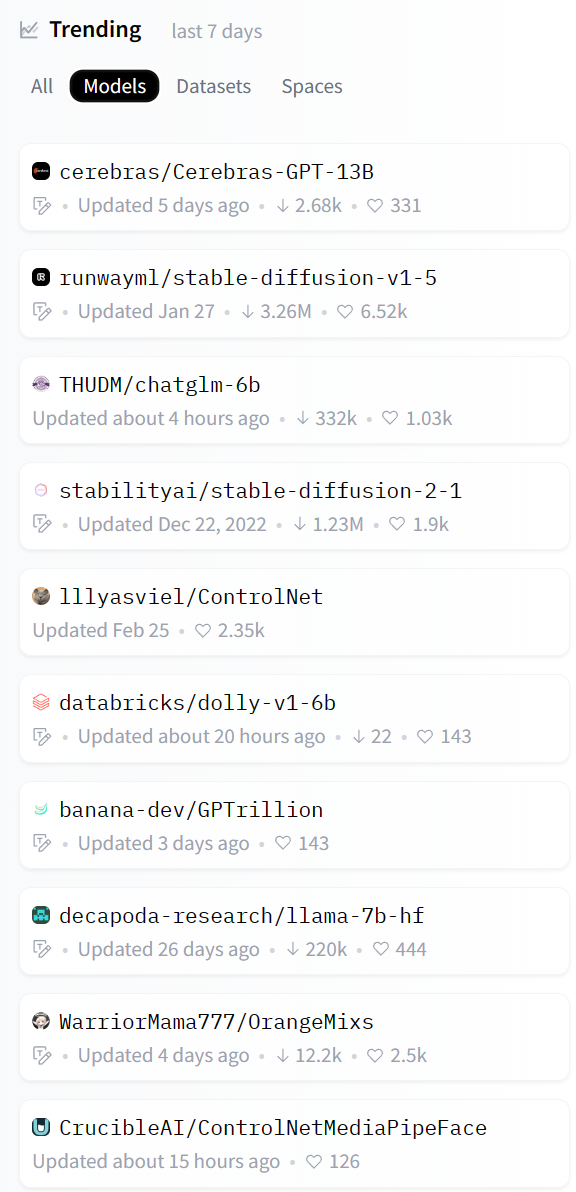
HuggingFace是目前最火热的AI社区(HuggingFace简介:https://www.datalearner.com/blog/1051636550099750 ),很多人称之为AI模型的GitHub。包括Google、微软等很多知名企业都在上面发布模型。而HuggingFace上提供的流行的模型也是大家应当关注的内容。本文简单介绍一下2023年4月初的七天(当然包括3月底几天)的最流行的9个模型(为什么9个,因为我发现第10个是一个数据集!服了!)。让大家看看地球人都在关注和使用什么模型。
Spring Security可以帮助我们进行页面的权限控制和登录验证,在这篇博客中,我们将简要描述如何使用Spring Security进行登录验证。