
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



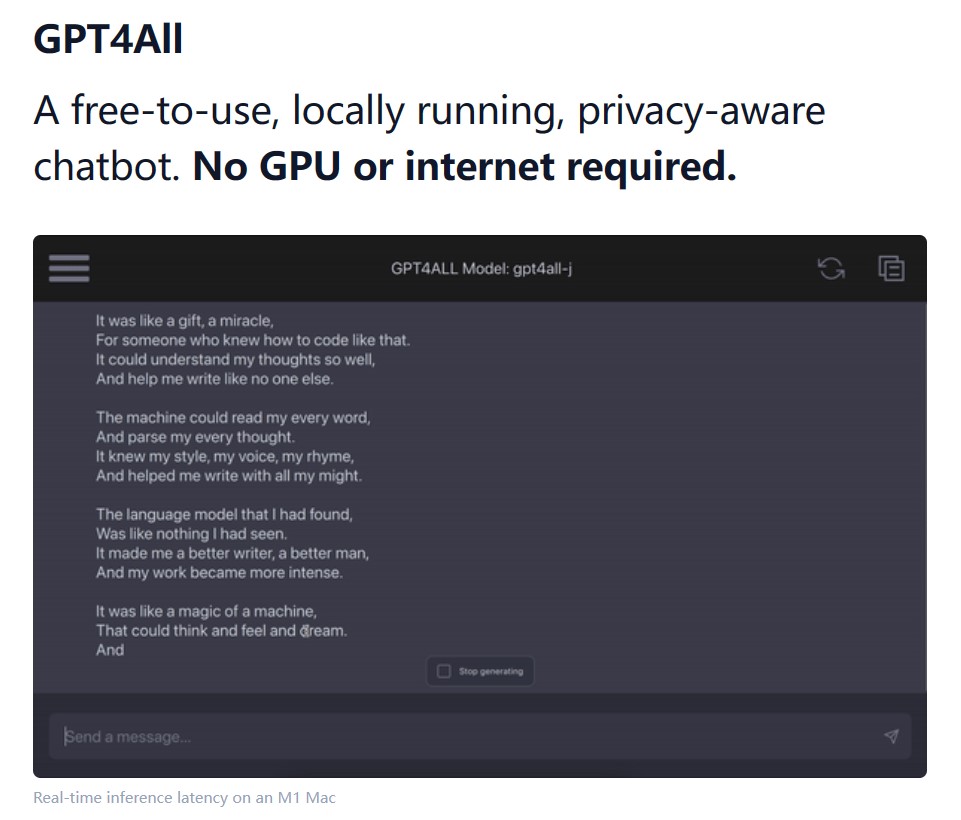
NomicAI推出了GPT4All这款软件,它是一款可以在本地运行各种开源大语言模型的软件。GPT4All将大型语言模型的强大能力带到普通用户的电脑上,无需联网,无需昂贵的硬件,只需几个简单的步骤,你就可以使用当前业界最强大的开源模型。
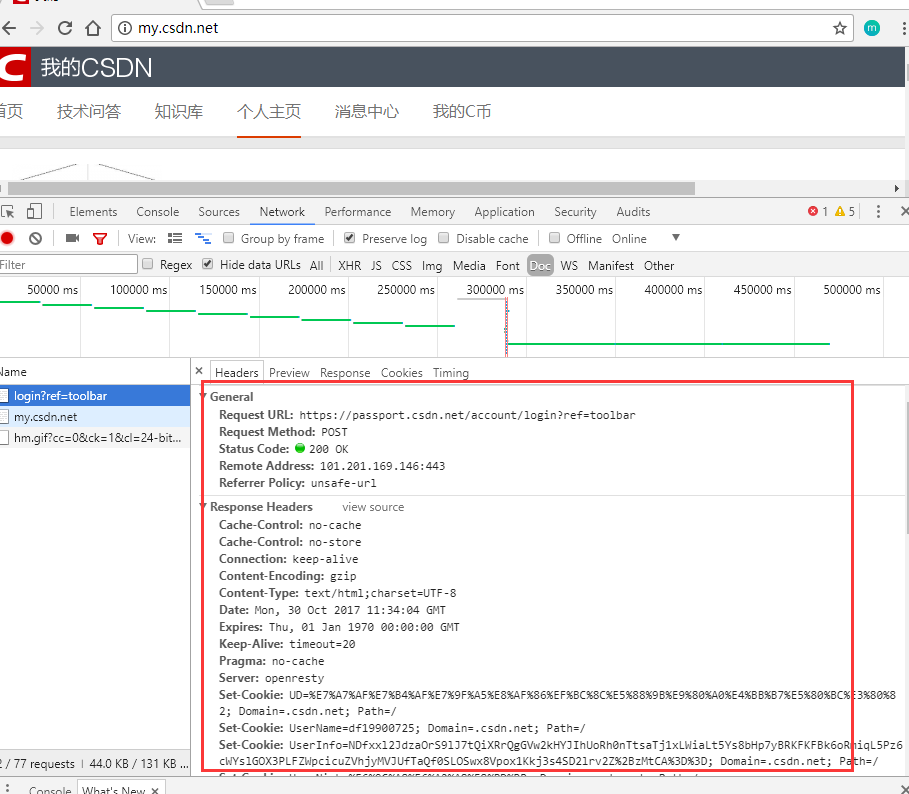
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录
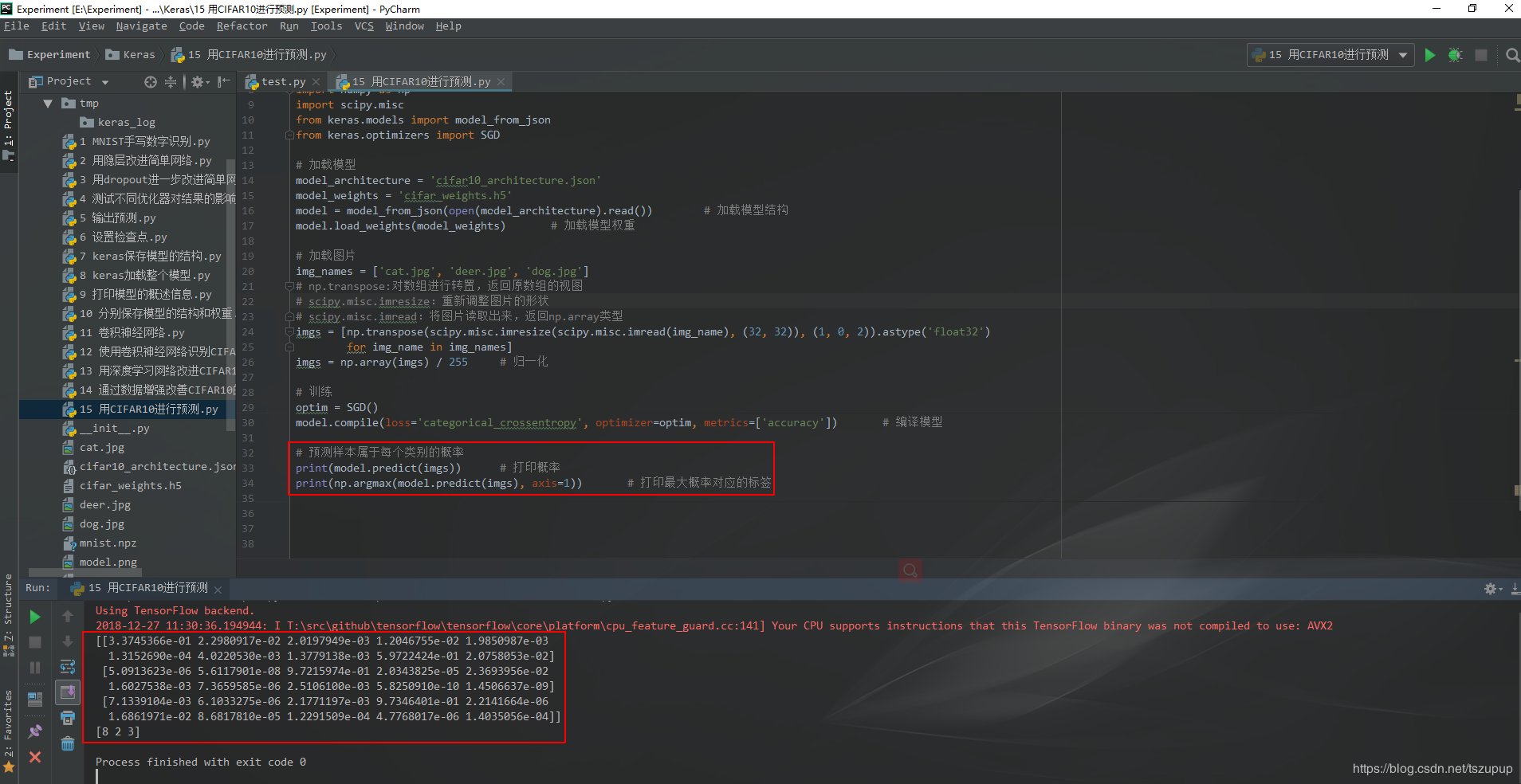
Keras中predict()方法和predict_classes()方法的区别

开源大语言模型的发展非常迅速,其强大的能力也吸引了很多人的尝试与体验。尽管预训练大语言模型的使用并不复杂,但是,因为其对GPU资源的消耗很大,导致很多人并不能很好地运行加载模型,也做了很多浪费时间的工作。其中一个比较的的问题就是很多人并不知道自己的显卡支持多大参数规模的模型运行。本文将针对这个问题做一个非常简单的介绍和估算。
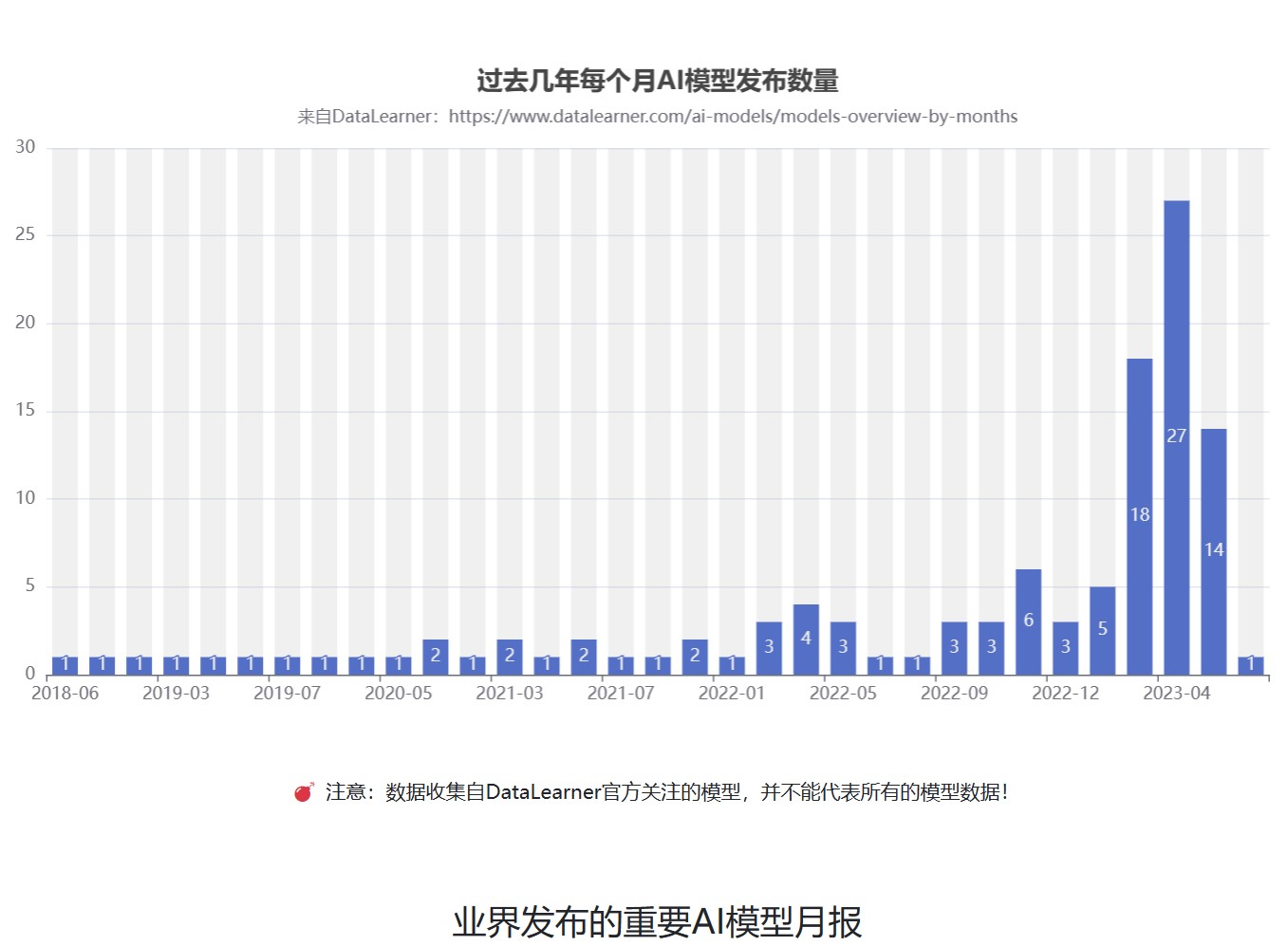
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。

贝叶斯分析在概率模型中有非常重要的作用,这些年以来比较有影响力的模型如LDA、非参数贝叶斯模型等都是基于贝叶斯分析的。贝叶斯分析有一些非常基础性的知识,在这里我们描述了贝叶斯分析里面的一些基本表示和一些分析准则等内容。
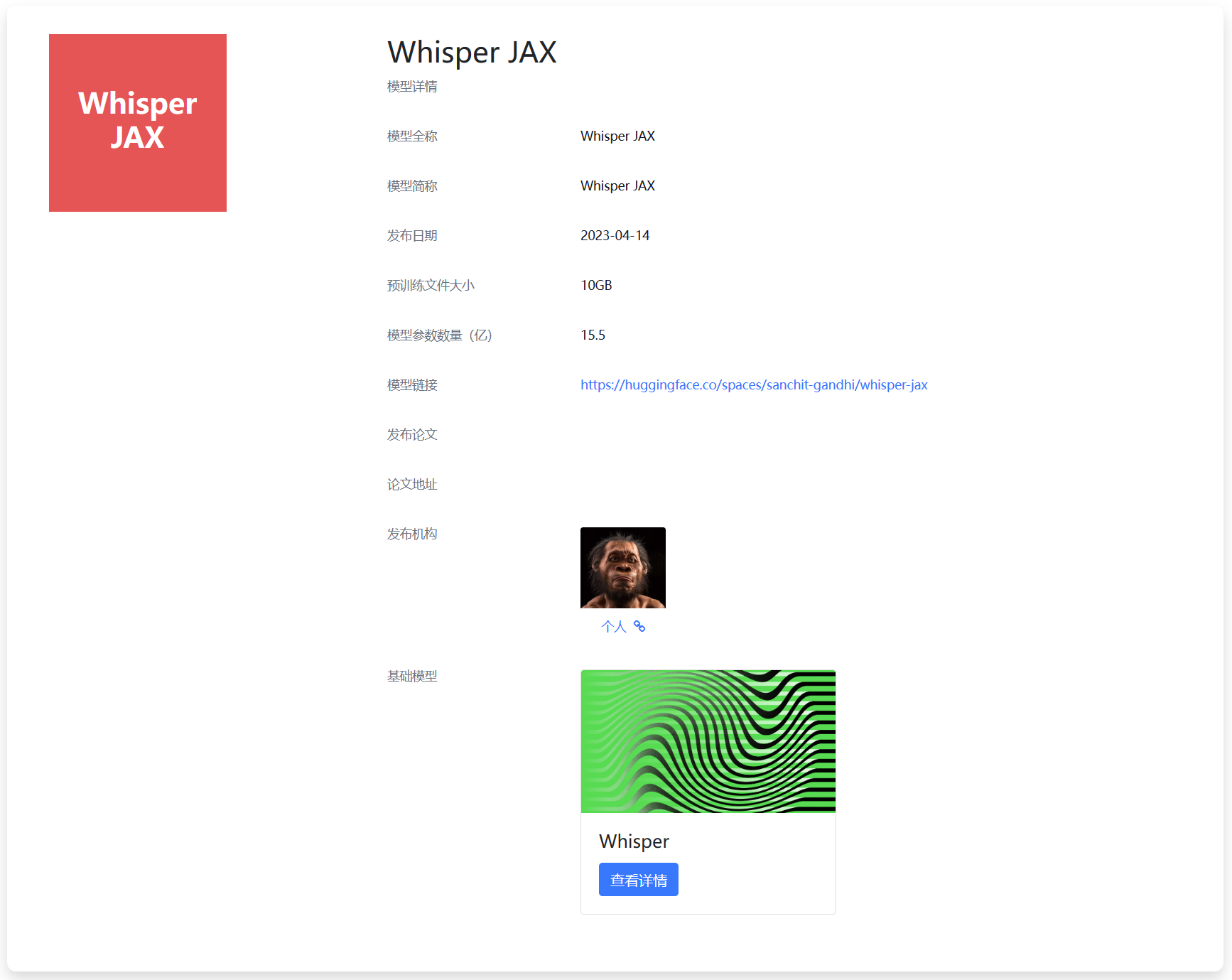
Whisper是OpenAI在2022年9月份开源的自动语音识别模型。官方宣传其英语的识别水平与人类接近。而2个月后,官方就发布了Whisper V2版本,是第一个版本继续训练2.5倍得到,且加了正则化技术。而今天,一位网友Sanchit Gandhi发布了Whisper JAX,这是对原有版本的优化结果,识别速度最高达到原始模型的70倍!
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。
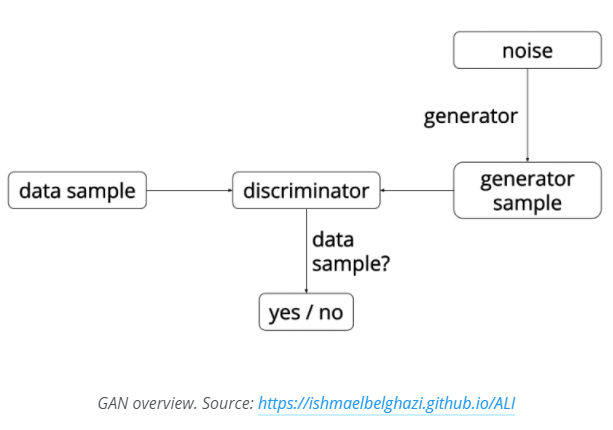
这篇博客是AYLIEN上的一篇关于生成对抗网络的简单介绍,包含非常简洁的代码示例。是入门非常好的材料。
这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规 模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同 时使用总体分布将参数的依赖结构化,从而避免过拟合问题。本节将讲述互换性并建立层次模型
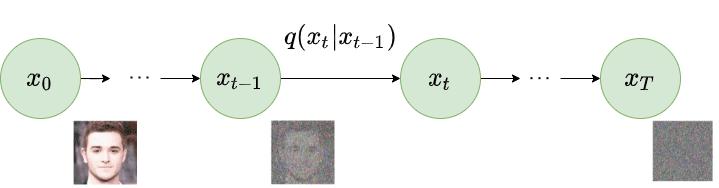
随着DALL·E2的发布,大家发现Text-to-Image居然可以取得如此好的效果。也让diffusion模型变得非常受欢迎。扩散模型虽然火热,但是背后的数学原理可能很多人也不太了解。这篇博客不仅介绍了扩散模型背后的数学原理,也讲述了如何训练扩散模型以及提高扩散模型训练效率的种种技巧,十分值得大家钻研。
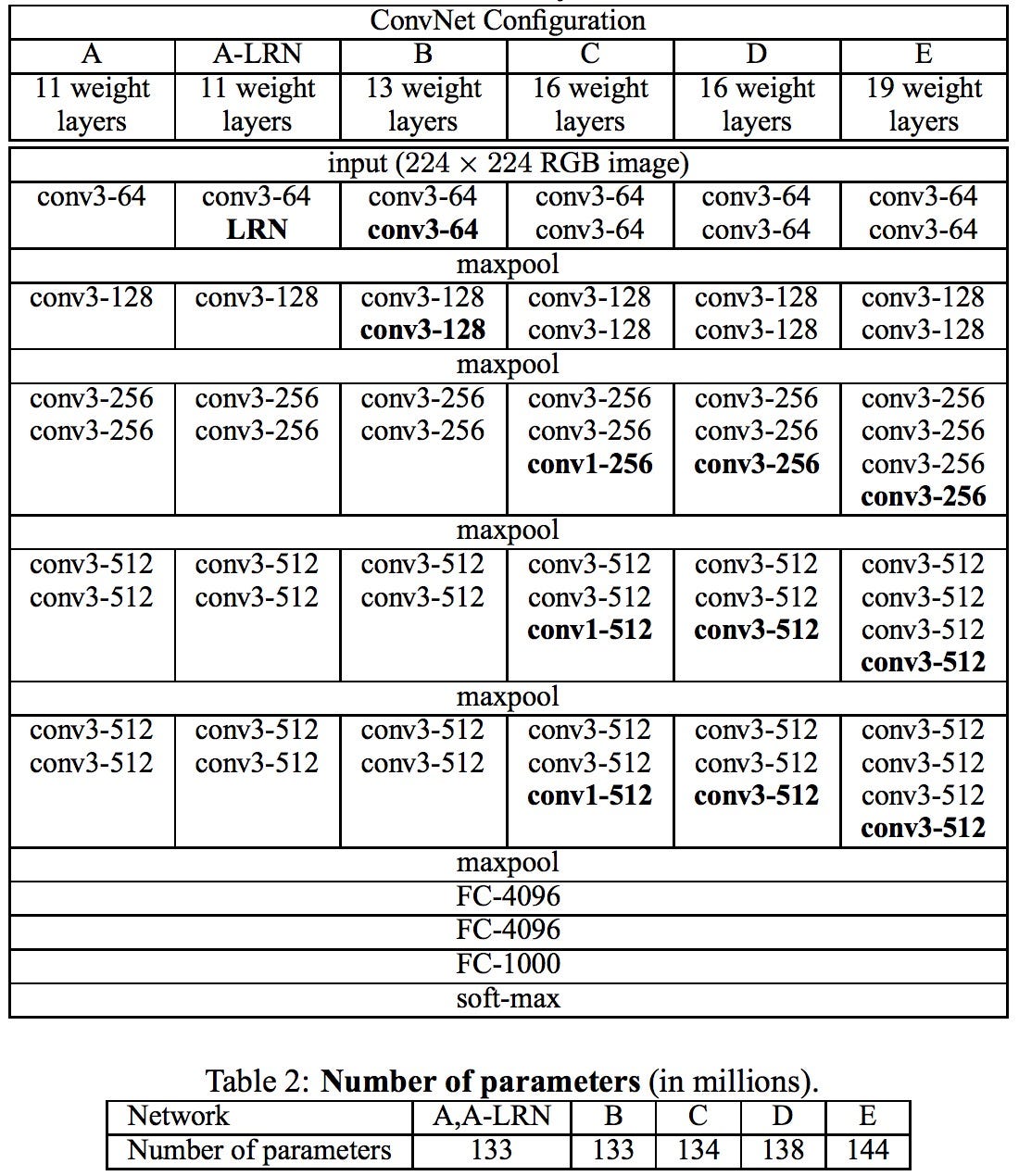
VGGNet(Visual Geometry Group)是2014年又一个经典的卷积神经网络。VGGNet最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而VGGNet的提出,给这些结构设计带来了一些标准参考。

这是OpenAI官方的cookebook最新更新的一篇技术博客,里面说明了为什么我们需要使用embeddings-based的搜索技术来完成问答任务。
今日推荐
可能是过去三十年来编程语言最大的革新:新的面向AI的编程语言Mojo发布~
Google最新超大模型Pathways:一个会讲笑话的6400亿参数的语言模型
Python报Memory Error或者是numpy报ValueError: array is too big; `arr.size * arr.dtype.itemsize` 的解决方法
HuggingFace开源语音识别模型Distil-Whisper,基于OpenAI的Whisper-V2模型蒸馏,速度快6倍,参数小49%!
月之暗面开源了一个全新的160亿参数规模的MoE大语言模型Moonlight-16B:其训练算力仅需业界主流的一半
预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning和prompt-tuning
重磅数据集分享:大规模多模态语料库之悟道数据集(WuDaoCorpora 2.0)
重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B