
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




GPTs是OpenAI推出的用户自定义的GPT功能,这里的GPTs可以认为是specific GPT。用户创建GPTs主要是通过OpenAI提供的GPT Builder完成。GPT Builder提供的最基本的能力就是基于对话的方式来帮助用户创建GPTs。那么,这个对话式的GPT背后的指令是什么?官方设置了什么样的Prompt来让GPT帮助普通用户建立GPTs呢?本文基于官方最新的博客介绍一下。
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。

今天,OpenAI官方宣布了一个非常有意思的论文,他们使用GPT-4模型来自动解释GPT-2中每个神经元的含义,试图让语言模型来对语言模型本身的原理进行解释。

本周,谷歌的研究人员在arXiv上提交了一个非常有意思的论文,其主要目的就是分享了他们建立能够翻译一千多种语言的机器翻译系统的经验和努力。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。
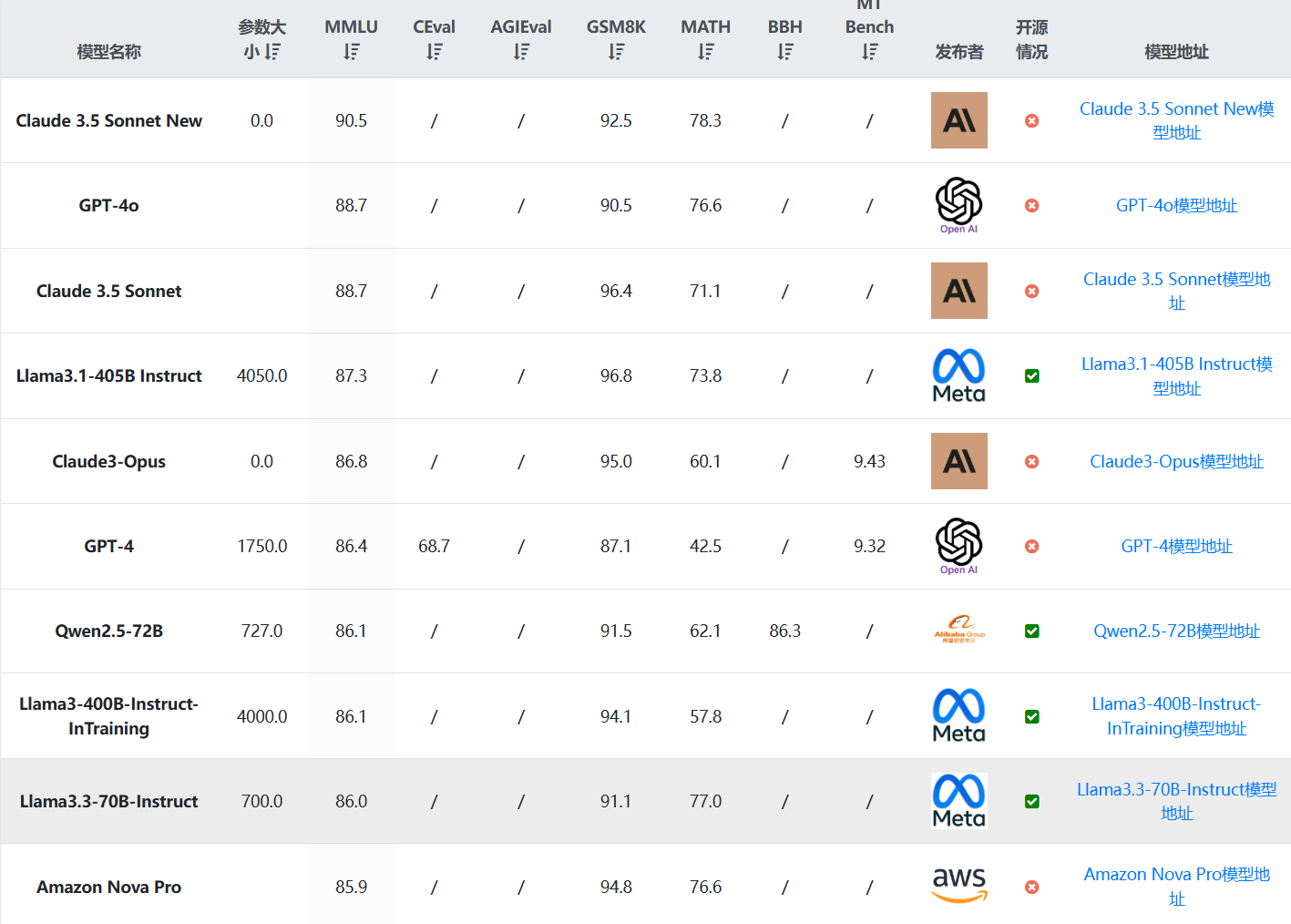
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。

Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。

最近开始学习新的前端技术。以前开发网站直接使用jQuery+Bootstrap组合,感觉非常容易和方便。但是,现在前端貌似都开始转向基于构建的方式去开发。由于初学者进入一个项目看很多内容也不如上手启动一个项目感受好,本文抛弃原理,直接教大家上手创建一个vue项目。
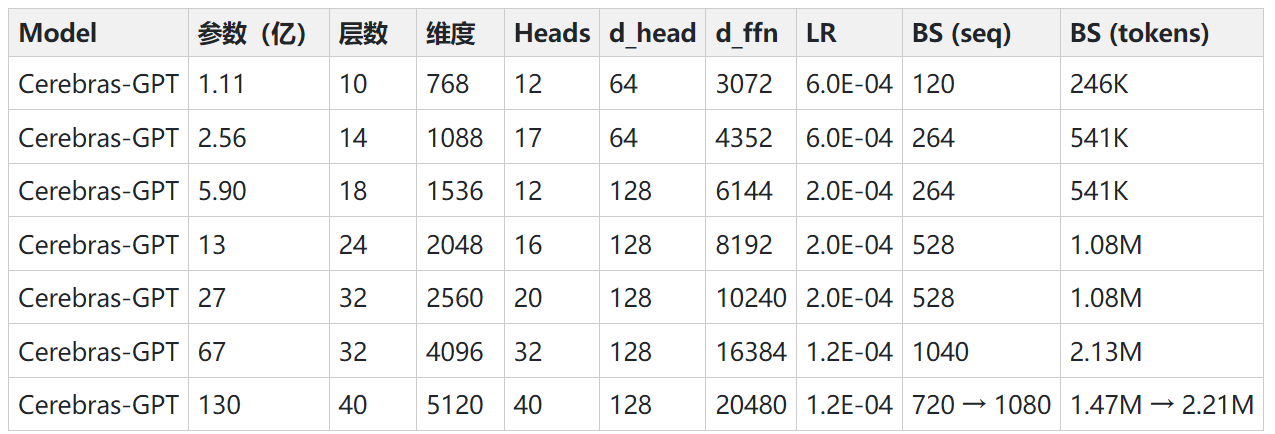
在最近的24个小时内,有2个开源的自然语言处理领域的开源预训练大模型发布。这两个模型都是类似GPT的Transformer模型,可以完成和ChatGPT类似的能力。最重要的是这2个模型完全开源!
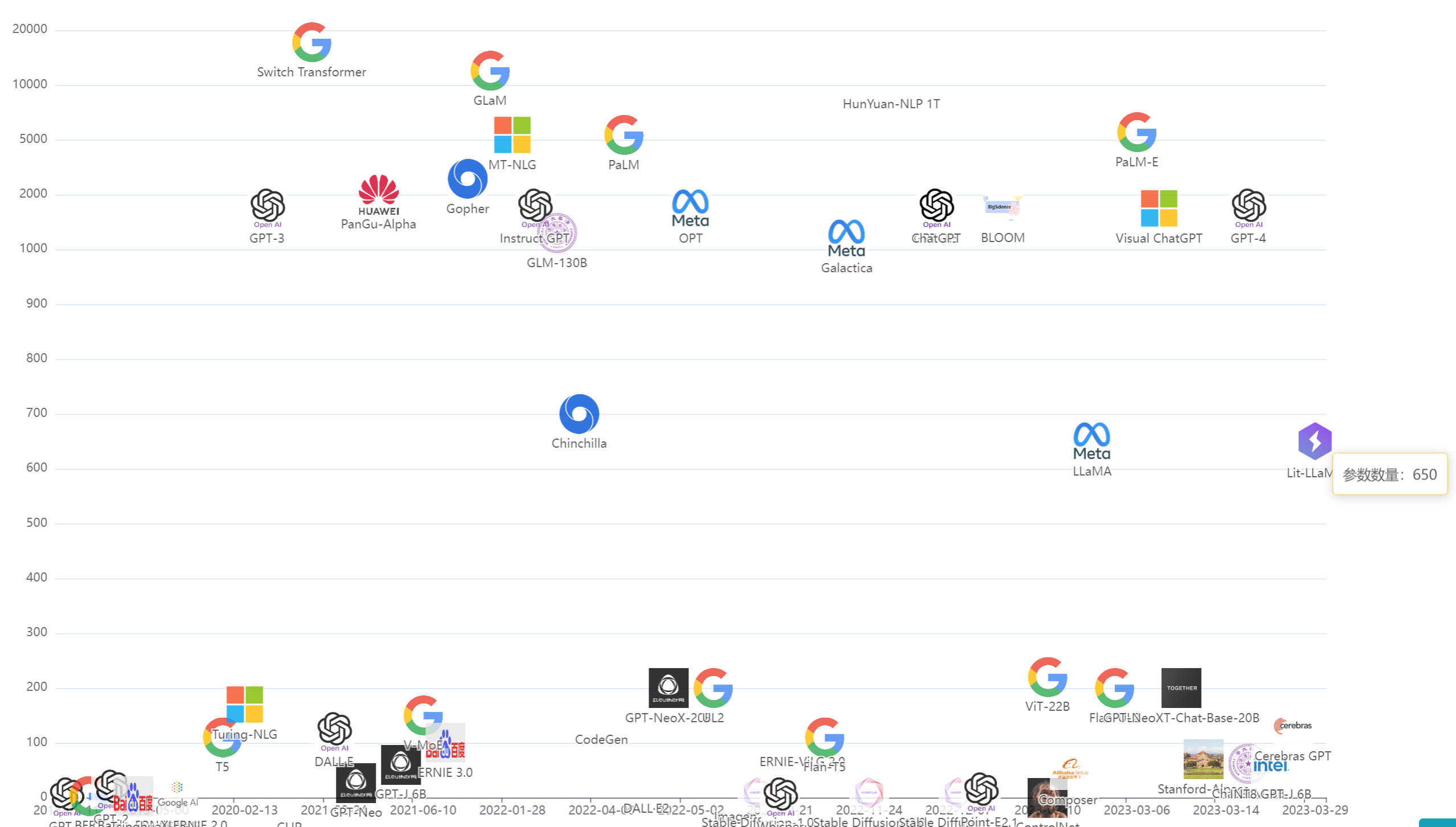
斯坦福大学发布的基础大模型追踪图谱Ecosystem Graphs,用图谱的方式给大家呈现了模型之间的联系,让人非常清楚明白追踪不同模型之间的关系。
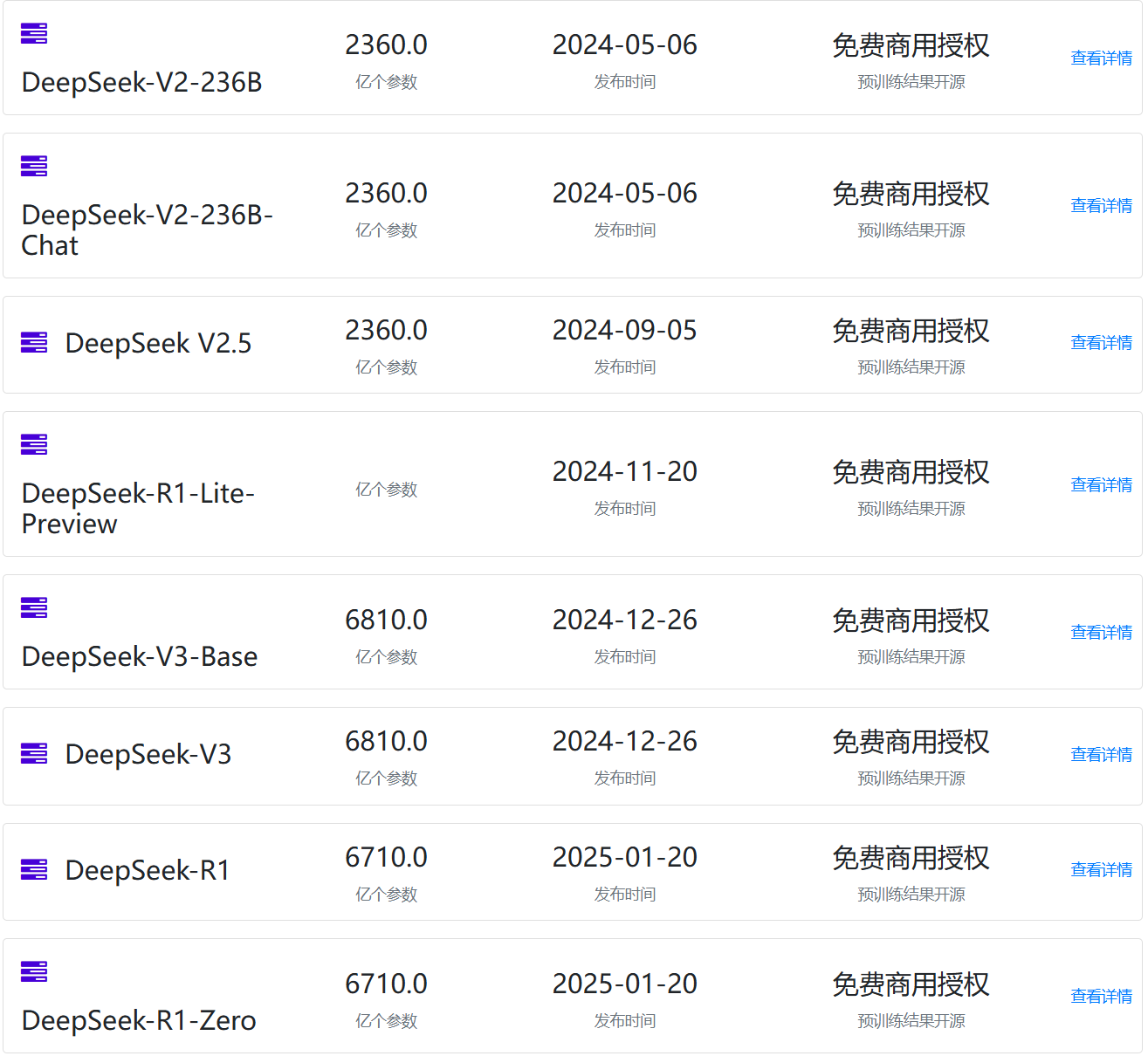
DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。
彭博社今天发布了一份研究论文,详细介绍了BloombergGPT的开发,这是一个新的大规模生成式人工智能(AI)模型。这个大型语言模型(LLM)经过专门的金融数据训练,支持金融业内的多种自然语言处理(NLP)任务。
几个小时前,OpenAI开启了今年密集的产品发布时间,本次发布会持续12天,直播12天。几个小时前,第一个发布的产品宣布,那就是OpenAI o1模型的正式版。同时也开启了一个全新的ChatGPT付费计划,即ChatGPT Pro,每个月200美元,可以不限量使用所有模型。本文详细介绍OpenAI o1模型。
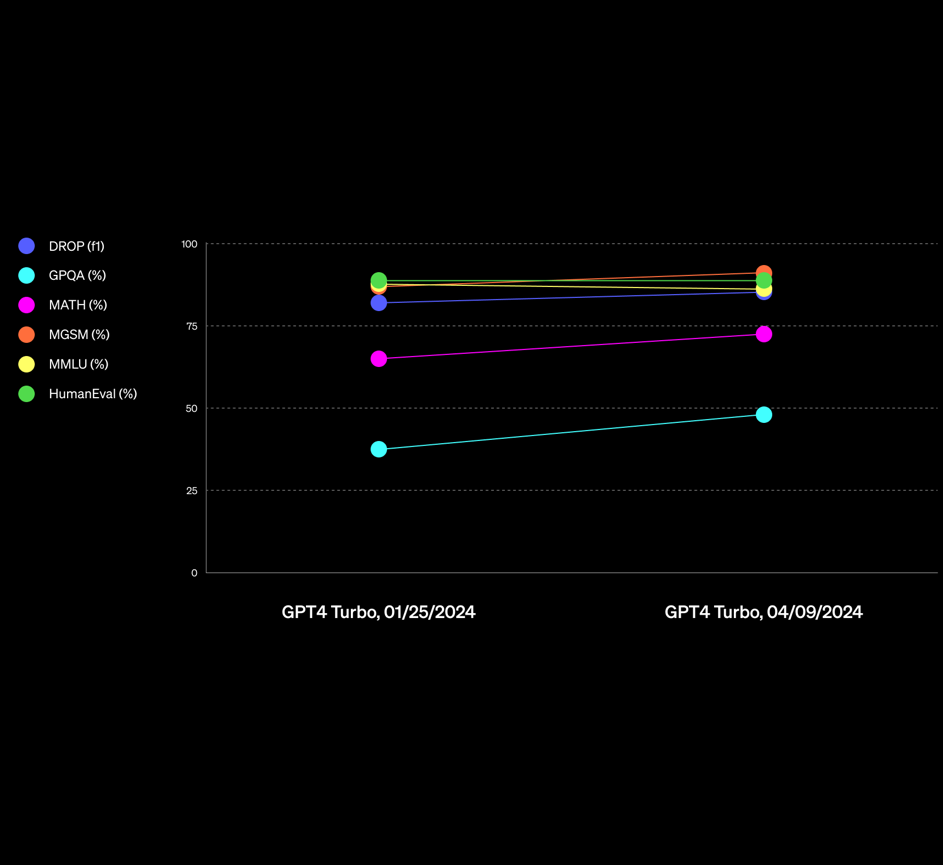
OpenAI的GPT-4一直是全球最强的大语言模型。但是在最近的一系列新模型对比中,已经有一些模型在某些领域被认为已经接近或者超过GPT-4了。而在前几天,OpenAI更新了一个新版本的GPT-4,是GPT-4-Turbo-2024-04-09,官方说该版本的GPT在推理和数学能力上有明显提升,而实测结果也很不错。在基准测试评测中,最高有19%的提升幅度!在GPT-4这样强的模型上有这样的提升幅度,十分不错!
今日推荐
主题模型聚类匹配2018TKDE阅读笔记(Topic Models for Unsupervised Cluster Matching)
ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文!
智谱AI发布国产最强大模型GLM4,理解评测与数学能力仅次于Gemini Ultra和GPT-4,编程能力超过Gemini-pro,还有对标GPTs商店的GLMs
即将发布的装备了ChatGPT模型的新版bing都有哪些功能?
最强SQL代码生成开源大模型发布:DefogAI开源超过gpt-3.5-turbo的SQL生成大模型SQLCoder,免费商用授权~