
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




本文是Steffen Rendle的文章BPR: Bayesian Personalized Ranking from Implicit Feedback的译文
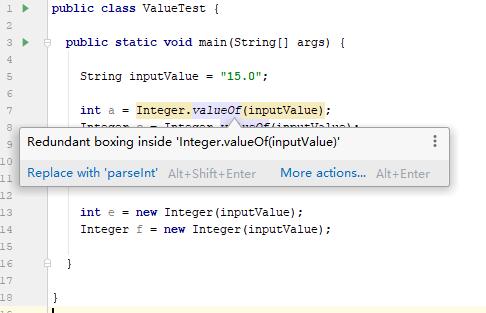
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。
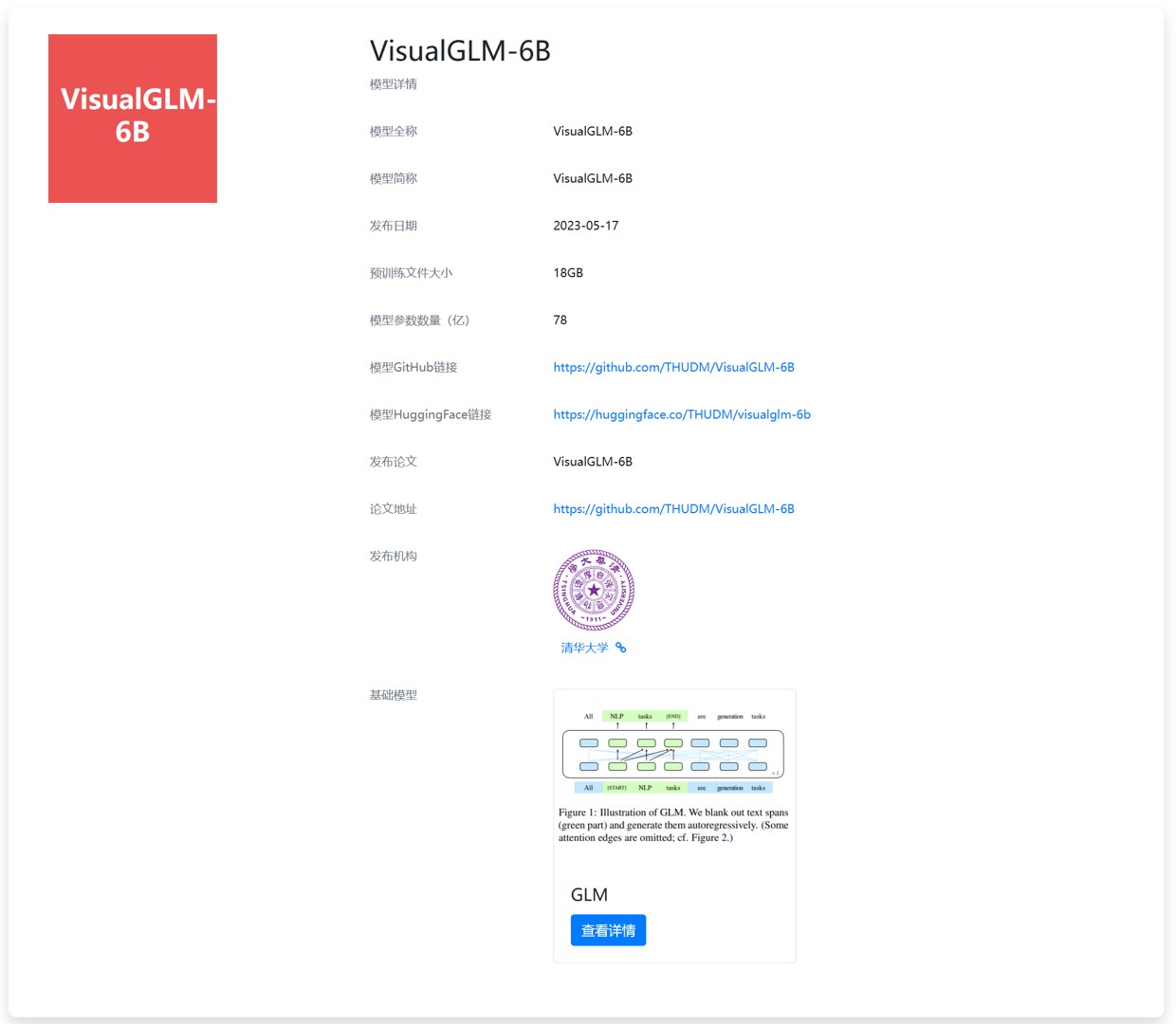
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。
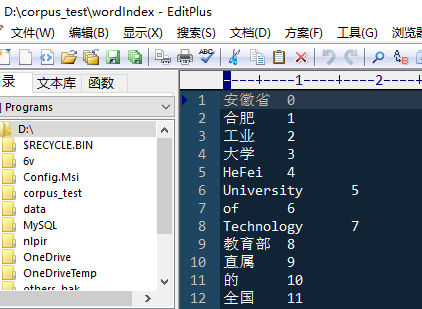
HFUTUtils是一个工具程序集合,方便我们平时处理数据。针对文本处理的内容较多。使用起来非常简单。是本人平时使用Java处理数据时候写的工具,方便数据预处理的。
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~
Android是基于Linux的修改版本的移动操作系统。 大多数Android代码是在开源Apache许可证下发布的。本文将简单介绍Android开发入门知识。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。
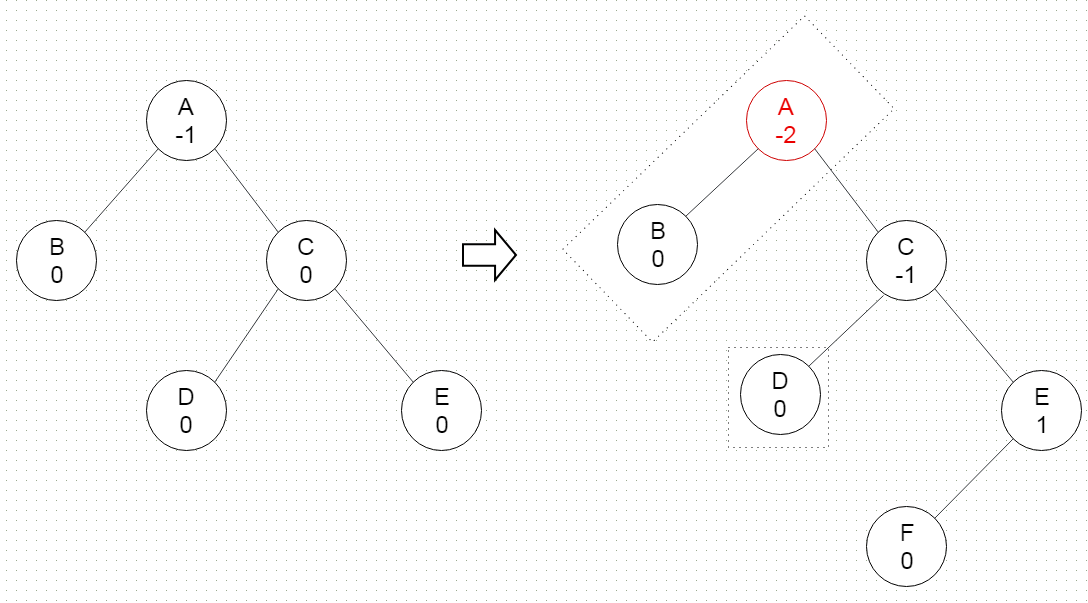
在前面的内容中,我们已经介绍了平衡二叉树。其中提到了AVL树,这是一种非常著名的平衡二叉树。这是第一个发明类似自平衡机制的二叉树数据结构。在AVL树中,任何节点的两个子树的高度最多相差一个。如果在任何时候它们相差多于一个,则重新平衡以恢复此属性。
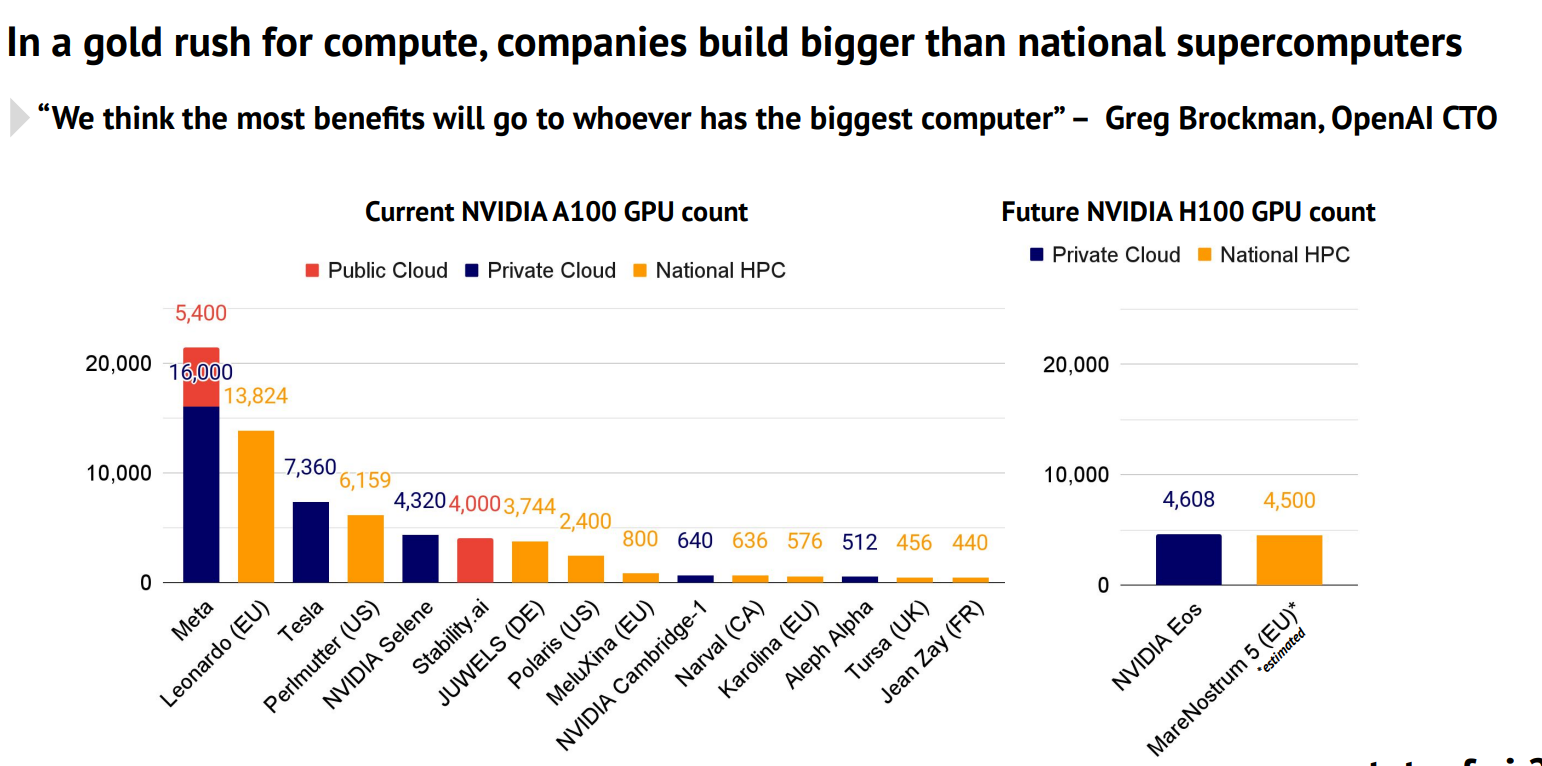
Stateof.AI上周发布了最新的AI的报告中报告了当前各大企业和机构拥有的NVIDIA A100的GPU数量。A100是目前商用的最强大的GPU,对于超级计算机、大规模AI模型的训练和推理来说都十分重要。这里透露的各大企业的GPU数量也让我们可以看到各家的竞争情况。
本文是Steffen Rendle的Pairwise Interaction Tensor Factorization for Personalized Tag Recommendation的译文。
广告分配问题属于运筹中的优化问题。一般情况下,我们期望有个最大化收益,但同时需要保证合约的完成。因此,这是一个带不等式约束的最优化问题。由于广告数量和用户数量很多,因此,求解的难度很高。在这篇文章中,作者推导了原问题的拉格朗日函数的系数之间的关系,大大降低了求解的难度。这里将简要介绍原理和推导过程。
tf.nn.softmax_cross_entropy_with_logits函数
今日推荐
GPT-4来了!微软德国CTO透露GPT-4将是多模态模型,并于下周发布!
基于GPU的机器学习Python库——RAPIDS简介及其使用方法
大型语言模型的新扩展规律(DeepMind新论文)——Training Compute-Optimal Large Language Models
DataLearnerAI-GPT:可以回答关于大模型评测结果的GPT
Mistral AI开源全新的120亿参数的Mistral NeMo模型,Mistral 7B模型的继任者!完全免费开源!中文能力大幅增强!
如何让开源大模型支持ChatGPT的Code Interpreter能力:基于LangChain的开源项目Code Interpreter API
数学推理能力超过ChatGPT-3.5:微软与中科院研究人员合作最新的开源大模型WizardMath发布!开源模型第一,免费商用授权!