大模型ARC-AGI-3评测基准:首个交互式推理基准
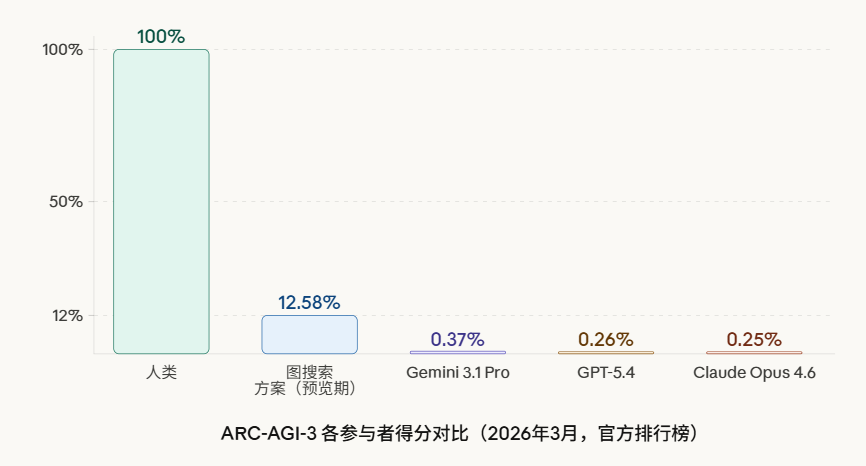
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。
汇总「AGI」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。

Grok Imagine 是一个由 xAI 开发的创新功能,集成到 Grok AI 聊天机器人中,旨在让用户能够从文本和视觉命令快速生成图像和视频。Grok Imagine最大的特点是能够生成长达 15 秒的视频,带有同步音频,使其成为 OpenAI 的 Sora 和 Google 的 Veo 3 等工具的直接竞争者。此外,它还包括一个“Spicy”模式,允许生成成人或显式内容,这一点引发了伦理和潜在误用的争议。

人工智能(AI)的通用智能(AGI)发展一直是研究领域的焦点。近期,由 ARC Prize 基金会推出并由 AI 研究者 François Chollet 联合发起的 ARC-AGI-2 评测基准,为衡量大模型在未知情境下的实时推理能力和学习效率提供了新的视角。

Mistral AI今天发布了其首个专注于推理能力的系列模型——**Magistral**。这次发布包含两个核心模型:旗舰模型`Magistral Medium`和<font color=red>已开源的</font>`Magistral Small (24B)`。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!
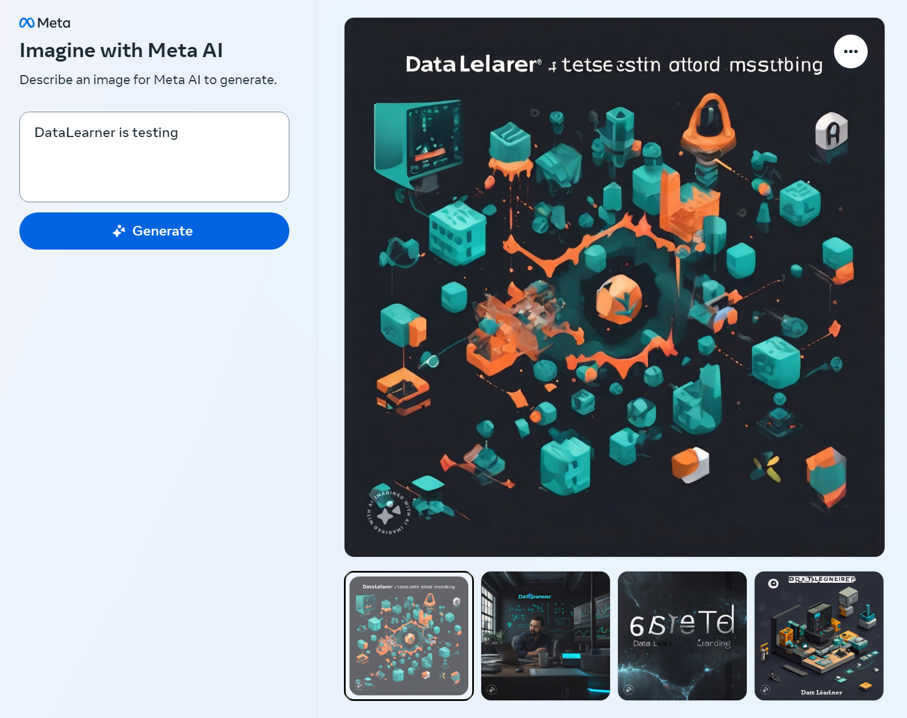
在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。
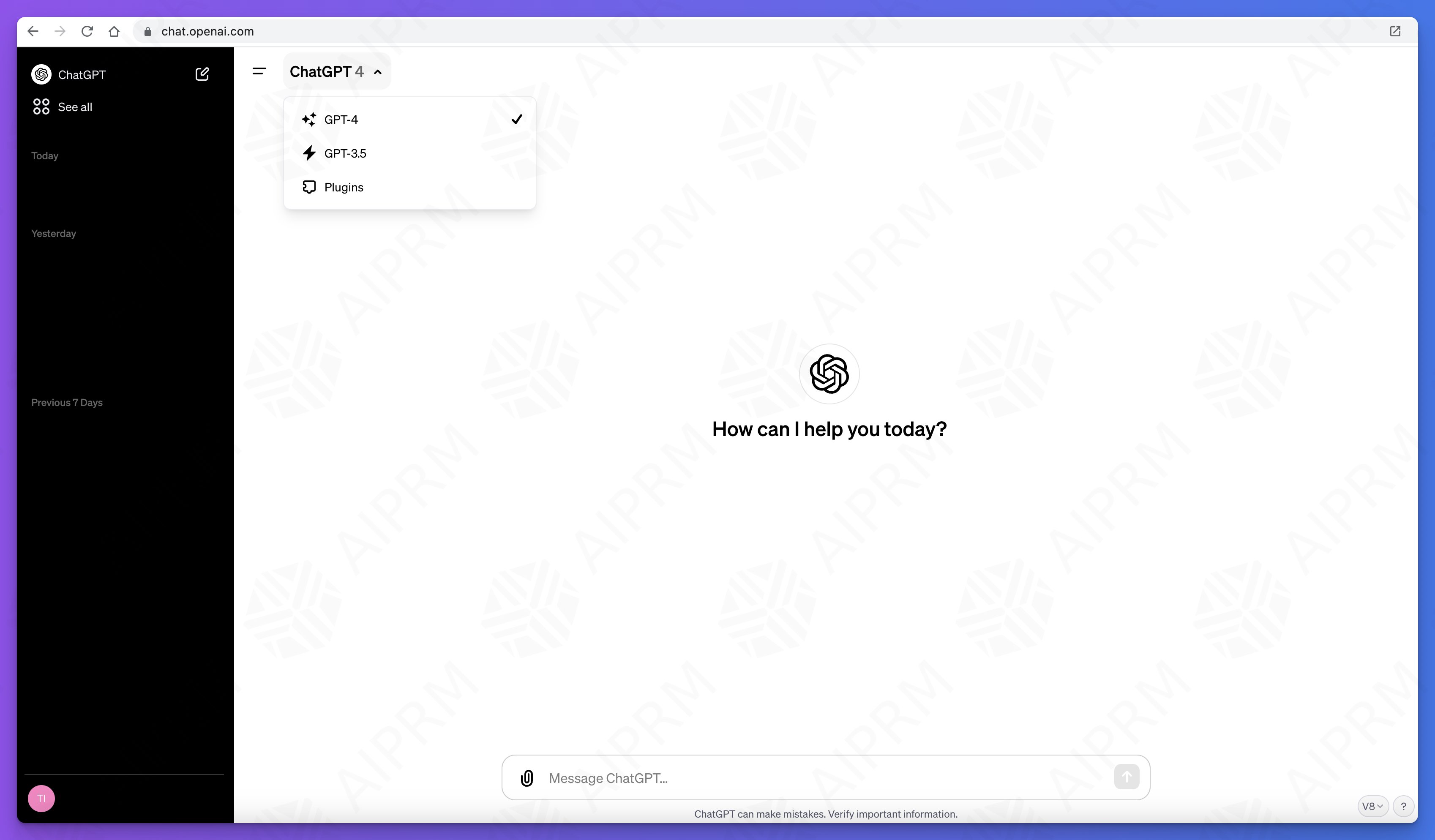
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!
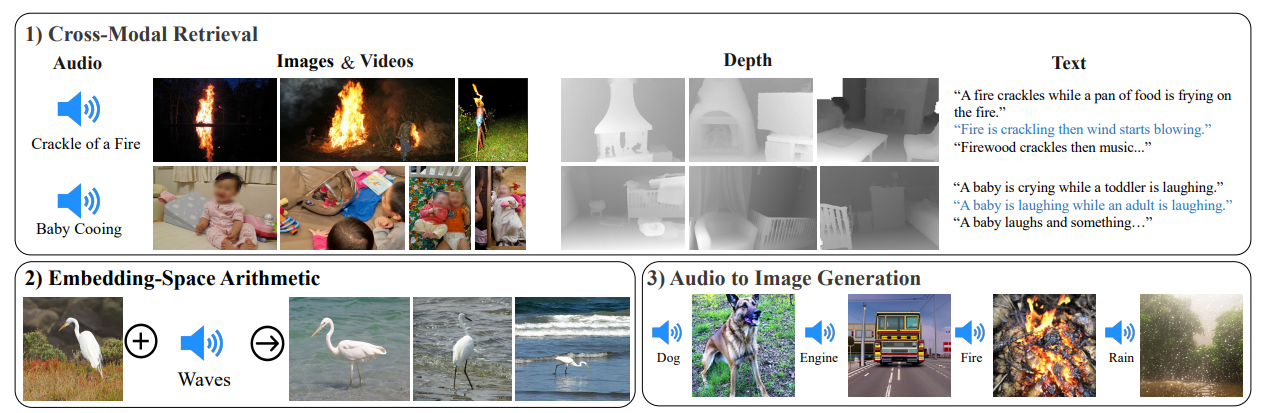
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。