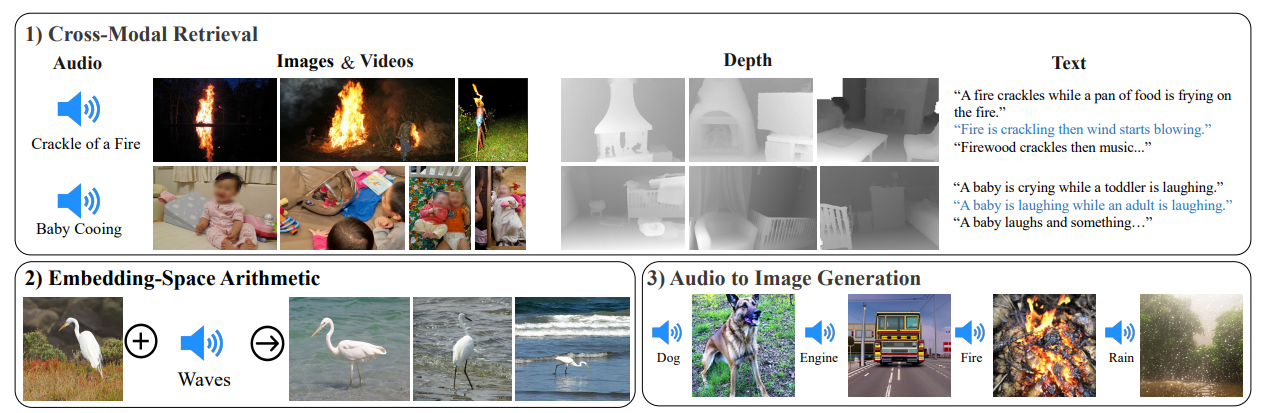
通用人工智能(AGI)再往前一步:MetaAI发布新的能听会说的多模态AI大模型ImageBind
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。
汇总「ImageBind」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。