
智谱发布 GLM-ASR(闭源)与开源 1.5B GLM-ASR-Nano-2512:针对中文与方言场景的语音识别尝试
就在刚才,智谱推出了两个语音识别模型:闭源的 GLM-ASR 和开源的 GLM-ASR-Nano-2512。与过去他们更多关注通用大模型或多模态模型不同,这次聚焦的是语音转文字(ASR)任务,尤其面向中文语境、方言与复杂环境。以下是对这两款模型已知公开资料的整理与分析。
加载中...
汇总「ASR」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
就在刚才,智谱推出了两个语音识别模型:闭源的 GLM-ASR 和开源的 GLM-ASR-Nano-2512。与过去他们更多关注通用大模型或多模态模型不同,这次聚焦的是语音转文字(ASR)任务,尤其面向中文语境、方言与复杂环境。以下是对这两款模型已知公开资料的整理与分析。

阿里发布了全新的语音识别大模型Qwen3-ASR-Flash,该模型是Qwen3系列模型中首个语音识别大模型,中英文语音识别错误率低于GPT-4o-transcribe和Gemini 2.5 Pro。不过,该模型目前仅通过API提供,不开源!
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。
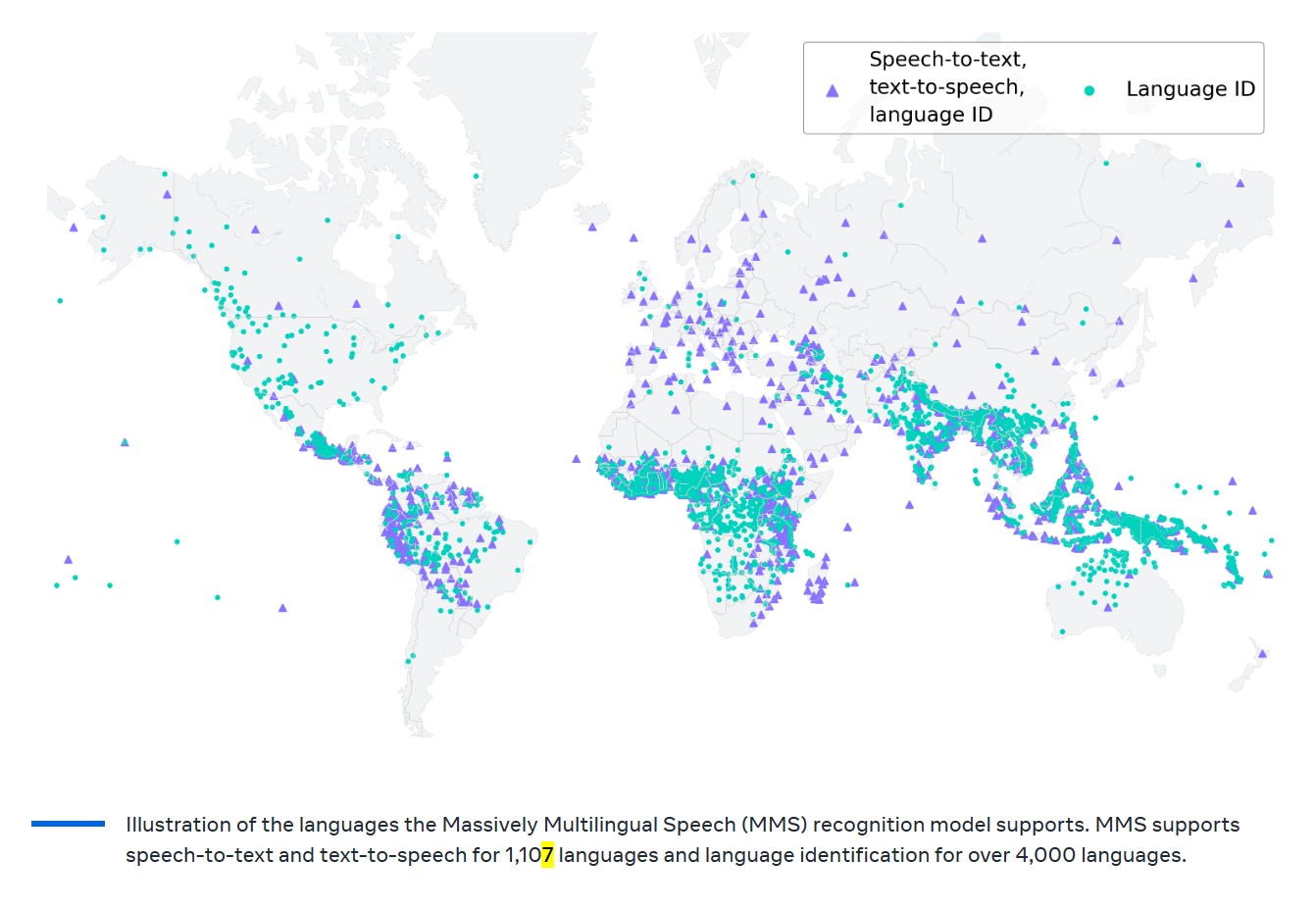
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!
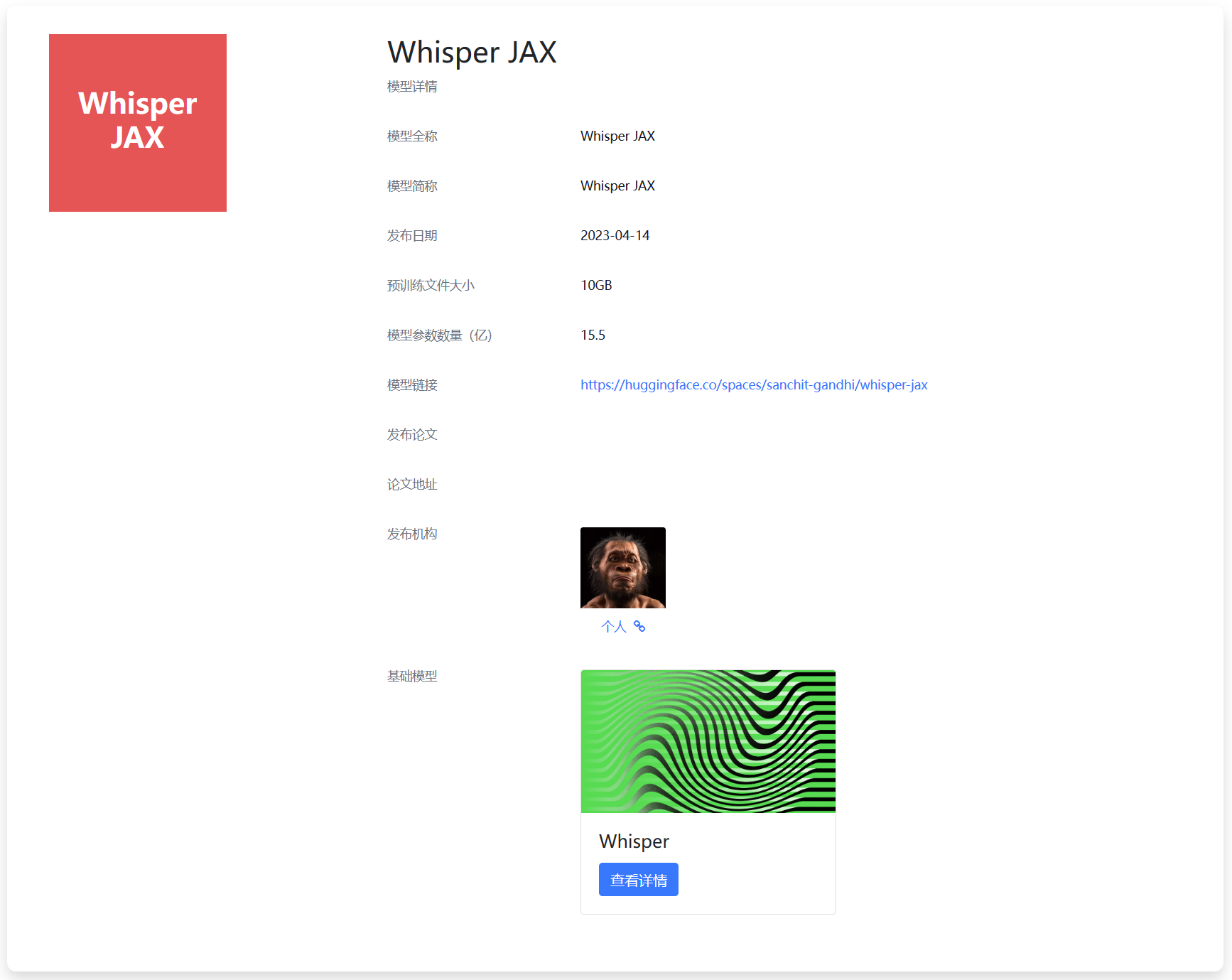
Whisper是OpenAI在2022年9月份开源的自动语音识别模型。官方宣传其英语的识别水平与人类接近。而2个月后,官方就发布了Whisper V2版本,是第一个版本继续训练2.5倍得到,且加了正则化技术。而今天,一位网友Sanchit Gandhi发布了Whisper JAX,这是对原有版本的优化结果,识别速度最高达到原始模型的70倍!