
阿里通义千问团队首次开源语音合成大模型:Qwen3-TTS:总共5个模型,最小的仅0.6B参数规模,最大1.8B参数
就在刚刚,阿里开源了全新的语音合成大模型Qwen3-TTS系列!本次开源的语音合成模型共5个版本,最小的仅0.6B参数规模,最大的模型参数也就1.7B,基本上手机端都可以运行。此次发布不仅在性能上宣称超越了许多商业级闭源模型(如 OpenAI 的 GPT-4o-Audio 和 ElevenLabs),更重要的这应该是阿里通义千问团队首次开源语音合成系列大模型。
汇总「TTS」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
就在刚刚,阿里开源了全新的语音合成大模型Qwen3-TTS系列!本次开源的语音合成模型共5个版本,最小的仅0.6B参数规模,最大的模型参数也就1.7B,基本上手机端都可以运行。此次发布不仅在性能上宣称超越了许多商业级闭源模型(如 OpenAI 的 GPT-4o-Audio 和 ElevenLabs),更重要的这应该是阿里通义千问团队首次开源语音合成系列大模型。

几个小时前,阿里一次更新了3个大模型,分别是开源的全模态大模型Qwen3-Omni、开源的图像编辑大模型Qwen3-Image-Edit和不开源的语音识别大模型Qwen3-TTS。本次发布的3个模型均为多模态大模型,可以说阿里的大模型真的是全面开花,节奏很快!
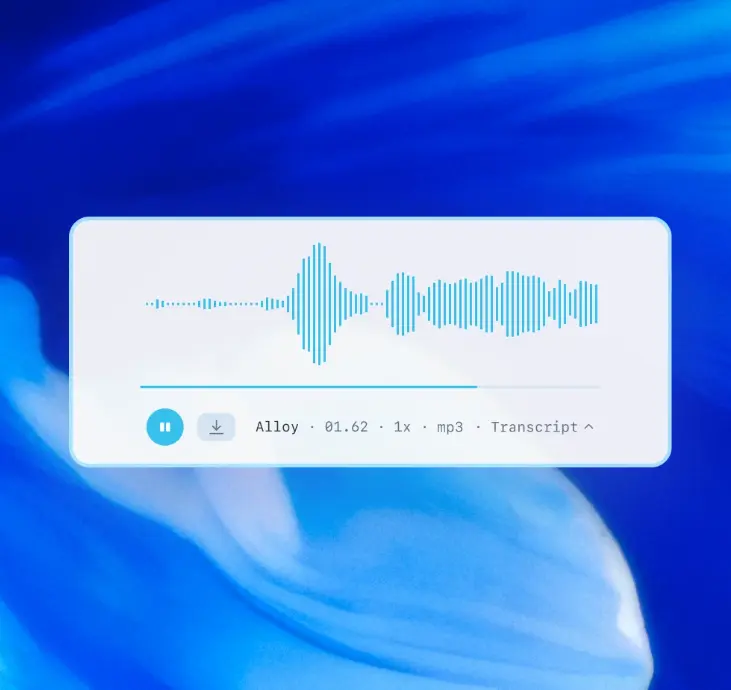
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。

OpenAI发布的模型中最主要的是大语言模型GPT系列。而且GPT系列模型也在朝着多模态的方向发展。尽管OpenAI有自己的TTS和ASR大模型,但是此前从未正式宣布过。就在今天,OpenAI正式宣布了他们首个语音合成大模型VoiceEngine,该模型也将提供API访问。OpenAI官方的声明中说,现有的基于声音的认证系统应该被淘汰掉!因为已经不安全了!
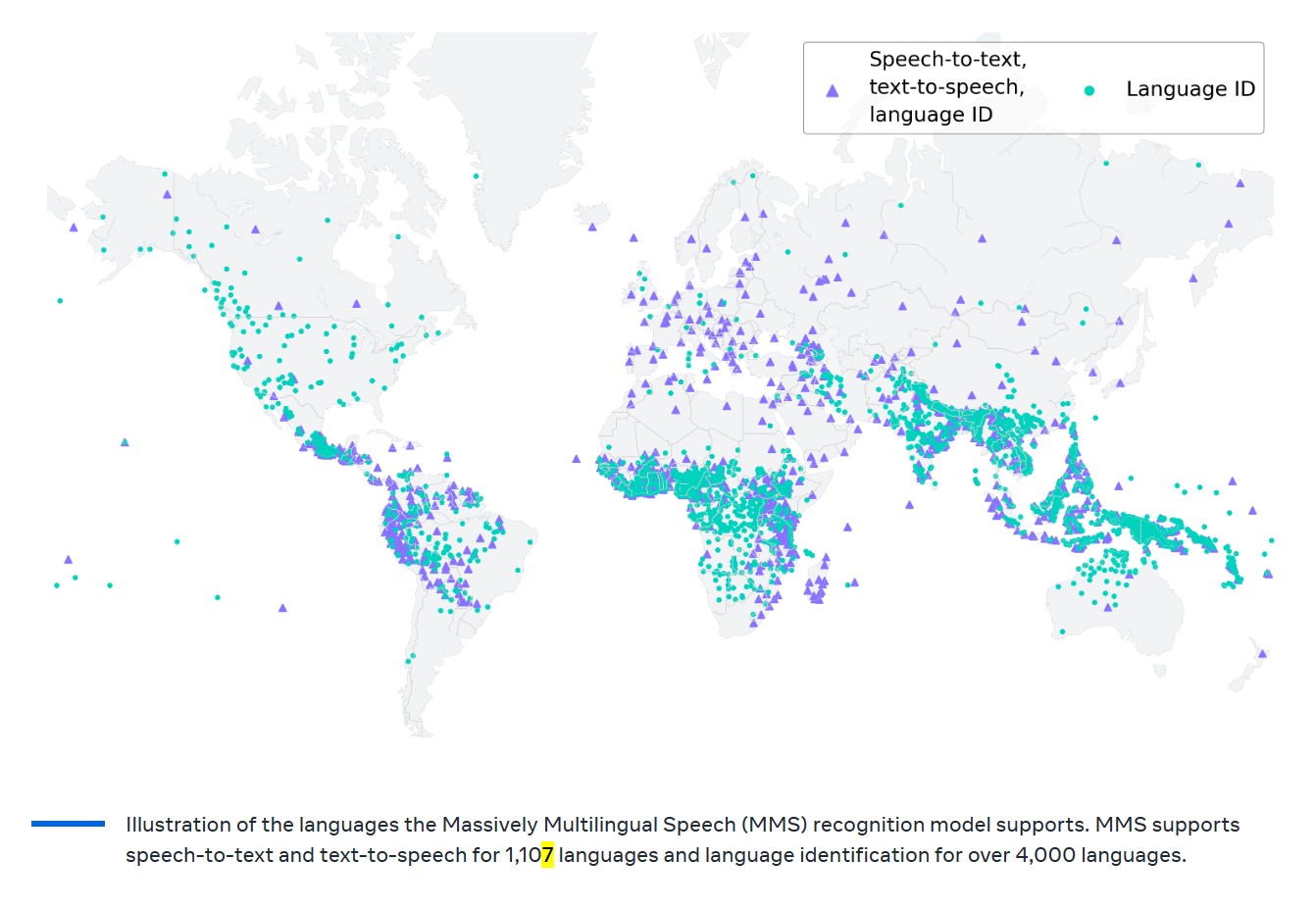
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~