
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




Pandas中的DataFrame选择某些行和某些列是有很多中操作和选择的,不太容易记,这里整理一下。
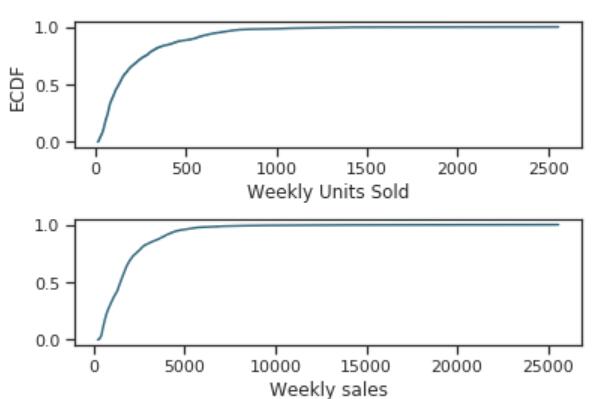
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。

在Java中,自增是一种非常常见的操作,在自增中,有两种写法,一种是前缀自增(++i),一种是后缀自增(i++)。这里主要简单介绍两种自增的差别。
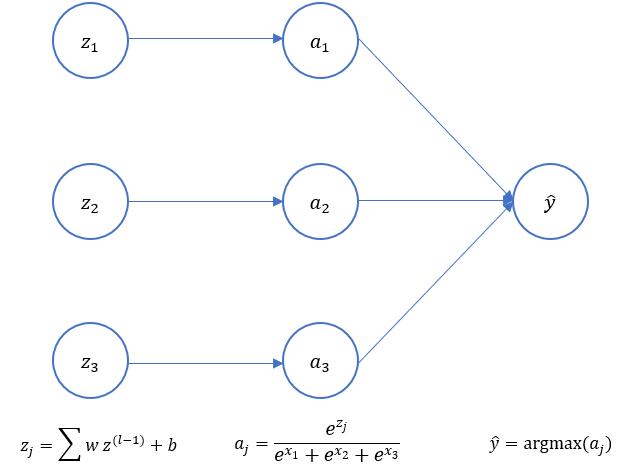
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。本篇博客将简要介绍相关概念和原理。
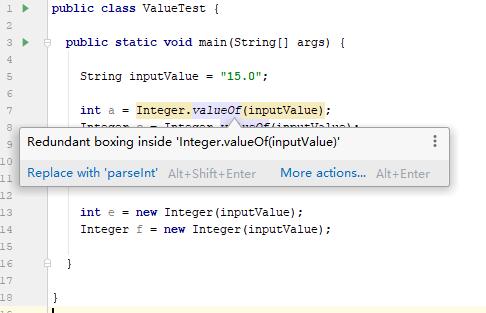
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。

随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。
今日推荐
需要多少GPU显存才能运行预训练大语言模型?大语言模型参数规模与显存大小的关系估算方法~
Batch Normalization应该在激活函数之前使用还是激活函数之后使用?
突破英特尔CPU+英伟达GPU的大模型训练硬件组合:苹果与AMD都有新进展!
简单几步教你如何在搭建并使用DALL·E开源版本来基于文字生成图片
近期ChatGPT Plus用户发现GPT-4性能大幅下降!GPT-4性能下降的现象和原因总结
Artificial Analysis报告显示中国AI产业技术突破,已经与美国形成全球双极主导
重磅!MLPerf™训练1.1成绩发布!AI训练正在超越摩尔定律!
0基础安装搭建Visual Studio Code开发环境——Python开发环境
OpenAI开源大模型调测工具Transformer Debugger(TDB):可以在训练大模型之前理解模型的运行情况并干预