
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。
使用SpringMVC框架搭建Web项目工程是目前非常流行的web项目创建方式。同时Spring Security也为我们提供了登录验证和权限控制等内容。

![[翻译]当推荐系统遇上深度学习](https://www.datalearner.com/resources/blog_images/2cdfcd04-ad6f-4183-9e6e-0c3b24ec4515.png)
翻译自Wann-Jiun Ma的Deep Learning Meets Recommendation Systems,主要讲了推荐系统的基础算法以及使用深度学习对电影的海报进行近似计算,从而推荐相似的电影。
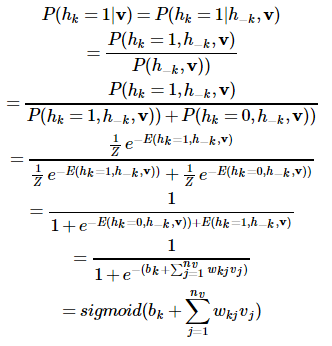
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是G.Hinton教授的一宝。Hinton教授是深度学习的开山鼻祖,也正是他在2006年的关于深度信念网络DBN的工作,以及逐层预训练的训练方法,开启了深度学习的序章。其中,DBN中在层间的预训练就采用了RBM算法模型。RBM是一种无向图模型,也是一种神经网络模型。
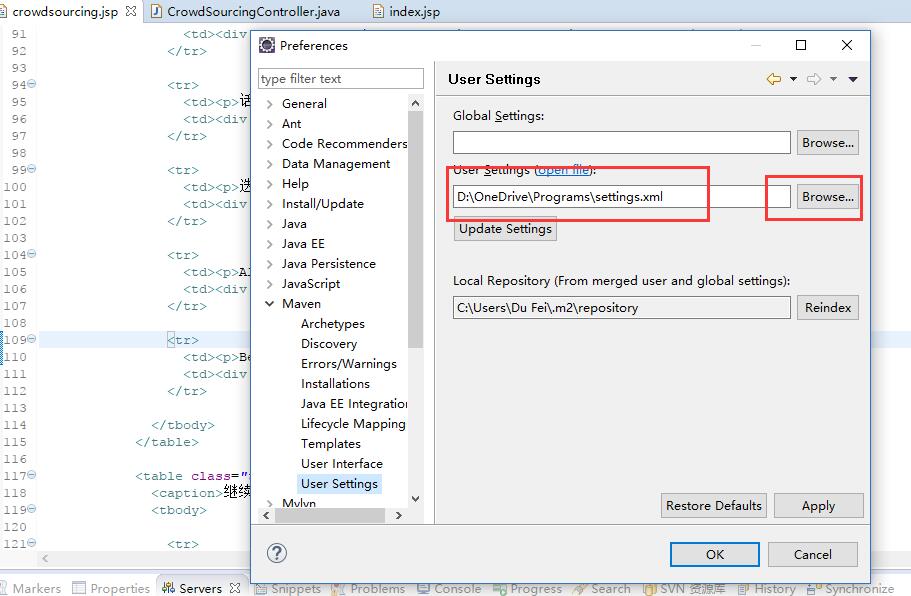
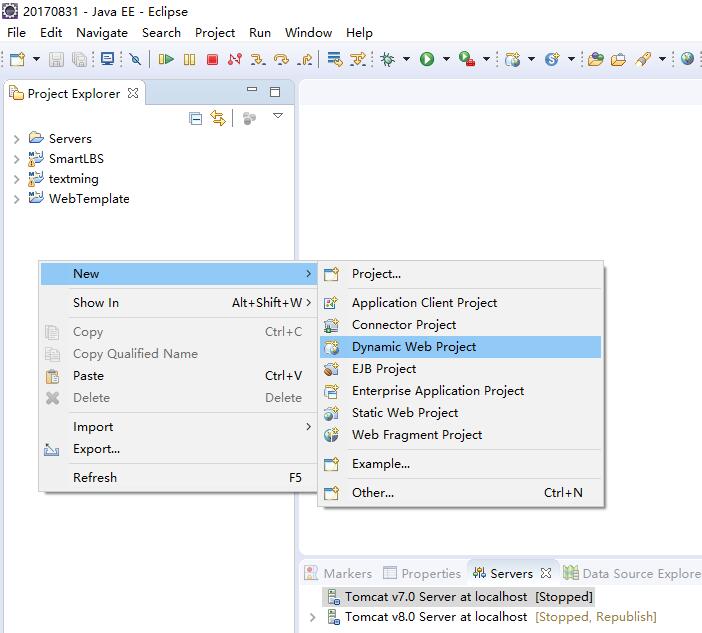
使用Maven作为构建工具,管理项目和依赖非常方便。这篇博客将简要介绍在Eclipse中如何使用Maven插件
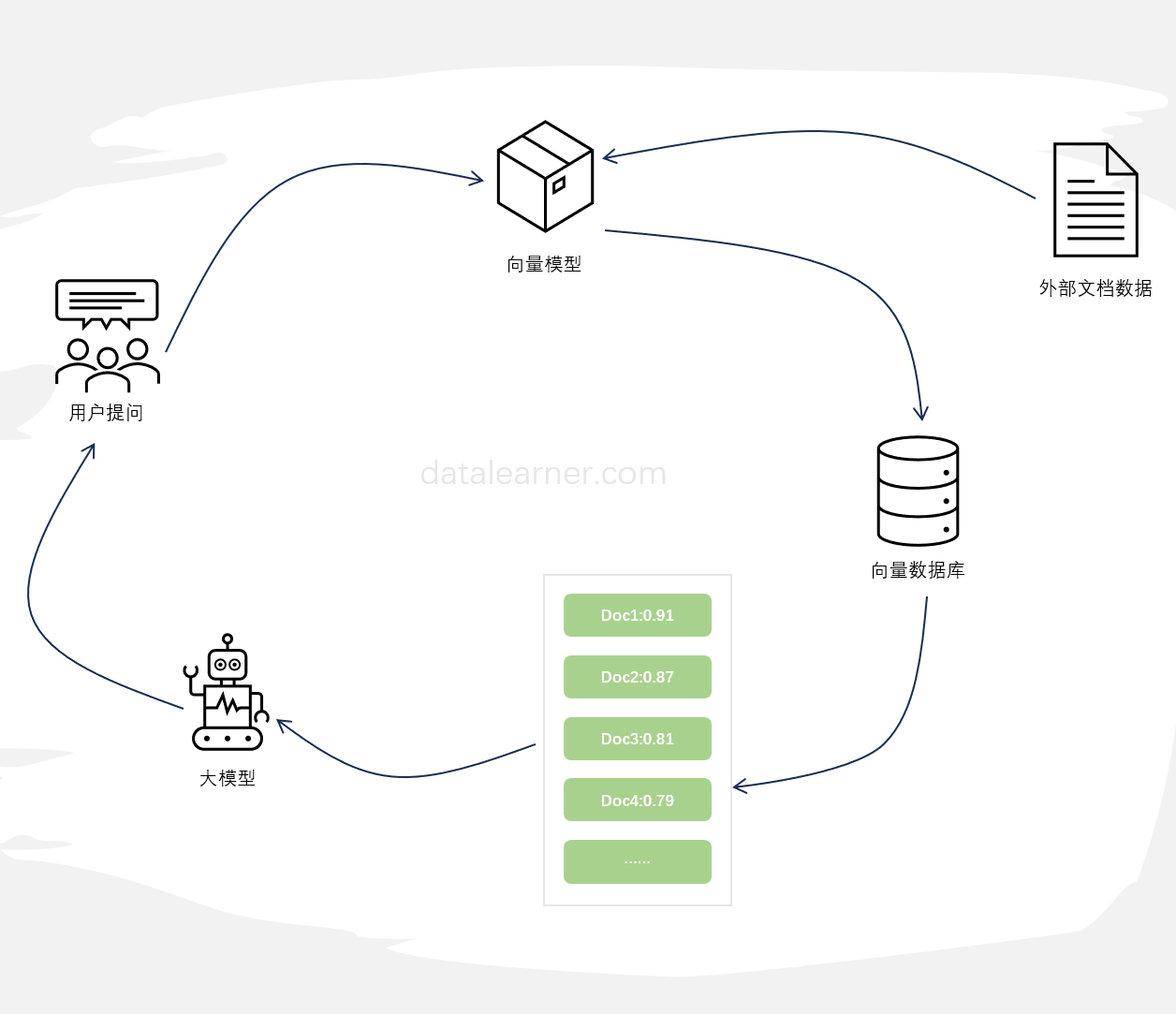
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。


使用pandas的DataFrame和dask的DataFrame保存数据到csv文件时候会出现两个换行符的情况。本文描述如何解决。
Spring Security可以帮助我们进行页面的权限控制和登录验证,在这篇博客中,我们将简要描述如何使用Spring Security进行登录验证。
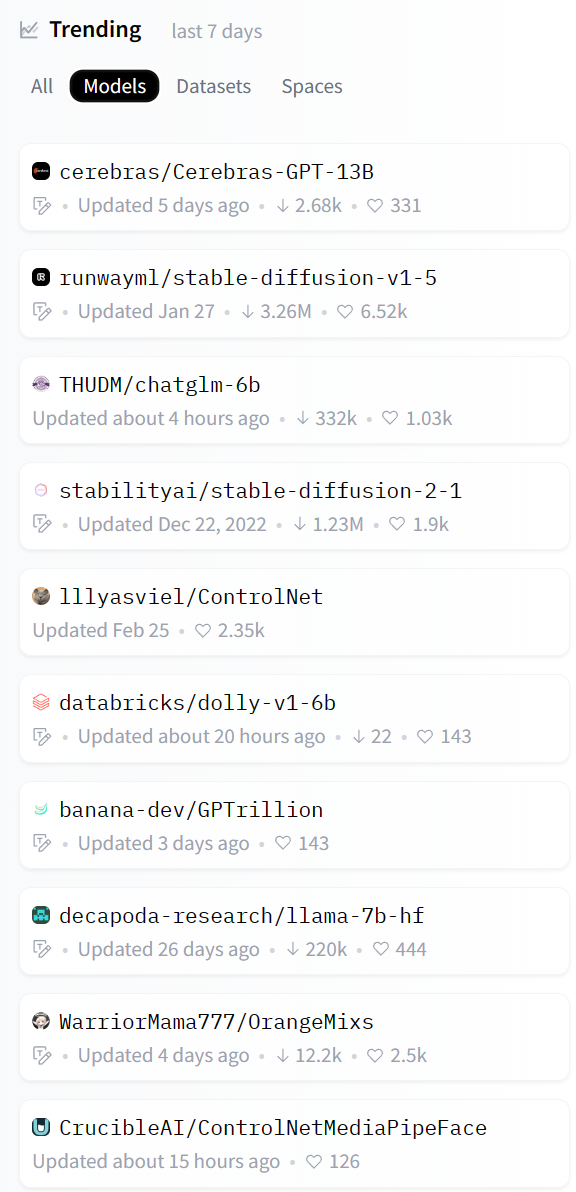
HuggingFace是目前最火热的AI社区(HuggingFace简介:https://www.datalearner.com/blog/1051636550099750 ),很多人称之为AI模型的GitHub。包括Google、微软等很多知名企业都在上面发布模型。而HuggingFace上提供的流行的模型也是大家应当关注的内容。本文简单介绍一下2023年4月初的七天(当然包括3月底几天)的最流行的9个模型(为什么9个,因为我发现第10个是一个数据集!服了!)。让大家看看地球人都在关注和使用什么模型。